 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Evaluation of ECG Representations Must Be Fixed
Feb 19, 2026This position paper argues that current benchmarking practice in 12-lead ECG representation learning must be fixed to ensure progress is reliable and aligned with clinically meaningful objectives. The field has largely converged on three public multi-label benchmarks (PTB-XL, CPSC2018, CSN) dominated by arrhythmia and waveform-morphology labels, even though the ECG is known to encode substantially broader clinical information. We argue that downstream evaluation should expand to include an assessment of structural heart disease and patient-level forecasting, in addition to other evolving ECG-related endpoints, as relevant clinical targets. Next, we outline evaluation best practices for multi-label, imbalanced settings, and show that when they are applied, the literature's current conclusion about which representations perform best is altered. Furthermore, we demonstrate the surprising result that a randomly initialized encoder with linear evaluation matches state-of-the-art pre-training on many tasks. This motivates the use of a random encoder as a reasonable baseline model. We substantiate our observations with an empirical evaluation of three representative ECG pre-training approaches across six evaluation settings: the three standard benchmarks, a structural disease dataset, hemodynamic inference, and patient forecasting.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024



Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
Stereoscopic Universal Perturbations across Different Architectures and Datasets
Jan 07, 2022
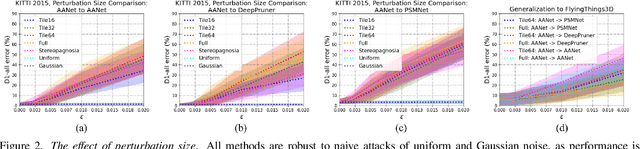
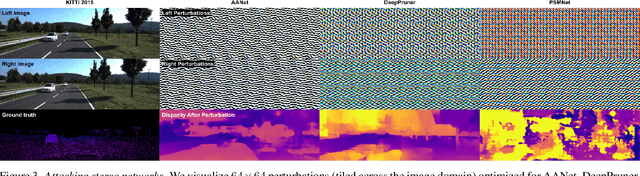
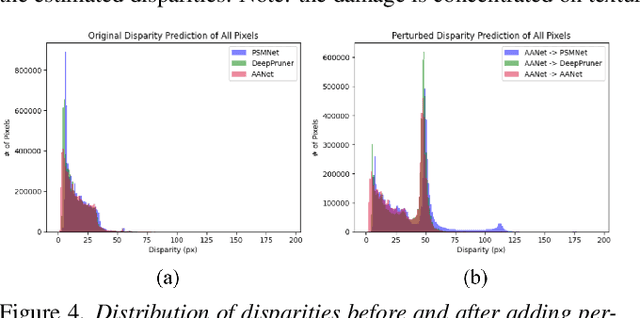
We study the effect of adversarial perturbations of images on deep stereo matching networks for the disparity estimation task. We present a method to craft a single set of perturbations that, when added to any stereo image pair in a dataset, can fool a stereo network to significantly alter the perceived scene geometry. Our perturbation images are "universal" in that they not only corrupt estimates of the network on the dataset they are optimized for, but also generalize to stereo networks with different architectures across different datasets. We evaluate our approach on multiple public benchmark datasets and show that our perturbations can increase D1-error (akin to fooling rate) of state-of-the-art stereo networks from 1% to as much as 87%. We investigate the effect of perturbations on the estimated scene geometry and identify object classes that are most vulnerable. Our analysis on the activations of registered points between left and right images led us to find that certain architectural components, i.e. deformable convolution and explicit matching, can increase robustness against adversaries. We demonstrate that by simply designing networks with such components, one can reduce the effect of adversaries by up to 60.5%, which rivals the robustness of networks fine-tuned with costly adversarial data augmentation.