 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximally-Informative Retrieval for State Space Model Generation
Jun 13, 2025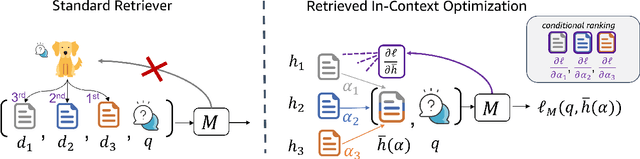
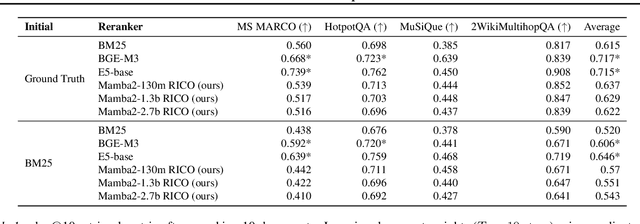
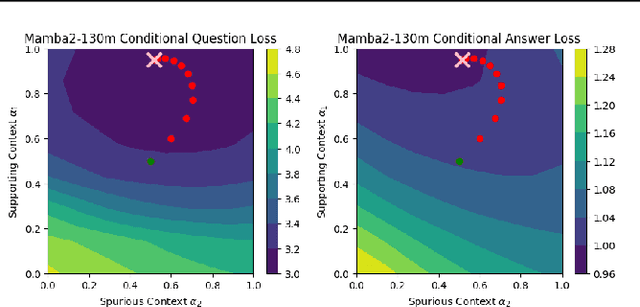
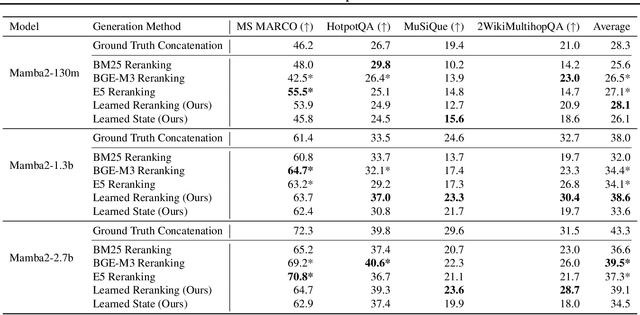
Given a query and dataset, the optimal way of answering the query is to make use all the information available. Modern LLMs exhibit impressive ability to memorize training data, but data not deemed important during training is forgotten, and information outside that training set cannot be made use of. Processing an entire dataset at inference time is infeasible due to the bounded nature of model resources (e.g. context size in transformers or states in state space models), meaning we must resort to external memory. This constraint naturally leads to the following problem: How can we decide based on the present query and model, what among a virtually unbounded set of known data matters for inference? To minimize model uncertainty for a particular query at test-time, we introduce Retrieval In-Context Optimization (RICO), a retrieval method that uses gradients from the LLM itself to learn the optimal mixture of documents for answer generation. Unlike traditional retrieval-augmented generation (RAG), which relies on external heuristics for document retrieval, our approach leverages direct feedback from the model. Theoretically, we show that standard top-$k$ retrieval with model gradients can approximate our optimization procedure, and provide connections to the leave-one-out loss. We demonstrate empirically that by minimizing an unsupervised loss objective in the form of question perplexity, we can achieve comparable retriever metric performance to BM25 with \emph{no finetuning}. Furthermore, when evaluated on quality of the final prediction, our method often outperforms fine-tuned dense retrievers such as E5.
PICASO: Permutation-Invariant Context Composition with State Space Models
Feb 24, 2025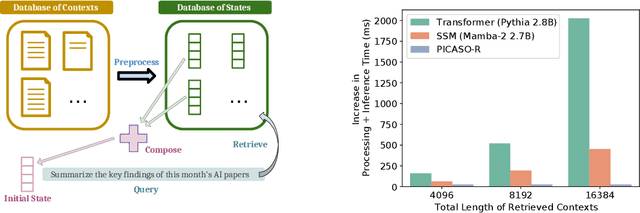

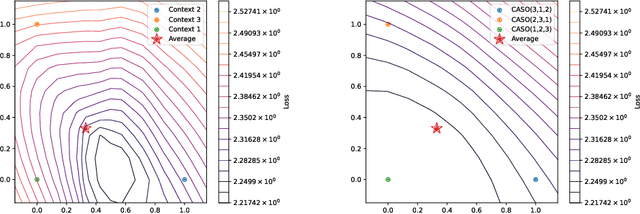

Providing Large Language Models with relevant contextual knowledge at inference time has been shown to greatly improve the quality of their generations. This is often achieved by prepending informative passages of text, or 'contexts', retrieved from external knowledge bases to their input. However, processing additional contexts online incurs significant computation costs that scale with their length. State Space Models (SSMs) offer a promising solution by allowing a database of contexts to be mapped onto fixed-dimensional states from which to start the generation. A key challenge arises when attempting to leverage information present across multiple contexts, since there is no straightforward way to condition generation on multiple independent states in existing SSMs. To address this, we leverage a simple mathematical relation derived from SSM dynamics to compose multiple states into one that efficiently approximates the effect of concatenating textual contexts. Since the temporal ordering of contexts can often be uninformative, we enforce permutation-invariance by efficiently averaging states obtained via our composition algorithm across all possible context orderings. We evaluate our resulting method on WikiText and MSMARCO in both zero-shot and fine-tuned settings, and show that we can match the strongest performing baseline while enjoying on average 5.4x speedup.
Conjuring Semantic Similarity
Oct 21, 2024The semantic similarity between sample expressions measures the distance between their latent 'meaning'. Such meanings are themselves typically represented by textual expressions, often insufficient to differentiate concepts at fine granularity. We propose a novel approach whereby the semantic similarity among textual expressions is based not on other expressions they can be rephrased as, but rather based on the imagery they evoke. While this is not possible with humans, generative models allow us to easily visualize and compare generated images, or their distribution, evoked by a textual prompt. Therefore, we characterize the semantic similarity between two textual expressions simply as the distance between image distributions they induce, or 'conjure.' We show that by choosing the Jensen-Shannon divergence between the reverse-time diffusion stochastic differential equations (SDEs) induced by each textual expression, this can be directly computed via Monte-Carlo sampling. Our method contributes a novel perspective on semantic similarity that not only aligns with human-annotated scores, but also opens up new avenues for the evaluation of text-conditioned generative models while offering better interpretability of their learnt representations.
Meanings and Feelings of Large Language Models: Observability of Latent States in Generative AI
May 22, 2024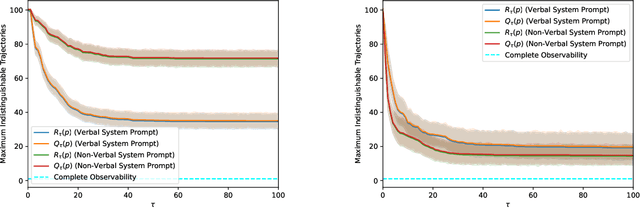
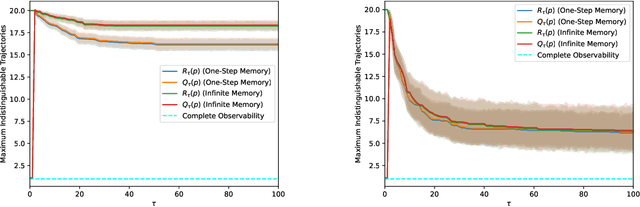

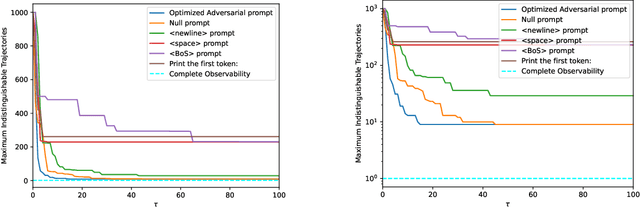
We tackle the question of whether Large Language Models (LLMs), viewed as dynamical systems with state evolving in the embedding space of symbolic tokens, are observable. That is, whether there exist multiple 'mental' state trajectories that yield the same sequence of generated tokens, or sequences that belong to the same Nerode equivalence class ('meaning'). If not observable, mental state trajectories ('experiences') evoked by an input ('perception') or by feedback from the model's own state ('thoughts') could remain self-contained and evolve unbeknown to the user while being potentially accessible to the model provider. Such "self-contained experiences evoked by perception or thought" are akin to what the American Psychological Association (APA) defines as 'feelings'. Beyond the lexical curiosity, we show that current LLMs implemented by autoregressive Transformers cannot have 'feelings' according to this definition: The set of state trajectories indistinguishable from the tokenized output is a singleton. But if there are 'system prompts' not visible to the user, then the set of indistinguishable trajectories becomes non-trivial, and there can be multiple state trajectories that yield the same verbalized output. We prove these claims analytically, and show examples of modifications to standard LLMs that engender such 'feelings.' Our analysis sheds light on possible designs that would enable a model to perform non-trivial computation that is not visible to the user, as well as on controls that the provider of services using the model could take to prevent unintended behavior.
Interpretable Measures of Conceptual Similarity by Complexity-Constrained Descriptive Auto-Encoding
Feb 14, 2024Quantifying the degree of similarity between images is a key copyright issue for image-based machine learning. In legal doctrine however, determining the degree of similarity between works requires subjective analysis, and fact-finders (judges and juries) can demonstrate considerable variability in these subjective judgement calls. Images that are structurally similar can be deemed dissimilar, whereas images of completely different scenes can be deemed similar enough to support a claim of copying. We seek to define and compute a notion of "conceptual similarity" among images that captures high-level relations even among images that do not share repeated elements or visually similar components. The idea is to use a base multi-modal model to generate "explanations" (captions) of visual data at increasing levels of complexity. Then, similarity can be measured by the length of the caption needed to discriminate between the two images: Two highly dissimilar images can be discriminated early in their description, whereas conceptually dissimilar ones will need more detail to be distinguished. We operationalize this definition and show that it correlates with subjective (averaged human evaluation) assessment, and beats existing baselines on both image-to-image and text-to-text similarity benchmarks. Beyond just providing a number, our method also offers interpretability by pointing to the specific level of granularity of the description where the source data are differentiated.
Meaning Representations from Trajectories in Autoregressive Models
Nov 02, 2023We propose to extract meaning representations from autoregressive language models by considering the distribution of all possible trajectories extending an input text. This strategy is prompt-free, does not require fine-tuning, and is applicable to any pre-trained autoregressive model. Moreover, unlike vector-based representations, distribution-based representations can also model asymmetric relations (e.g., direction of logical entailment, hypernym/hyponym relations) by using algebraic operations between likelihood functions. These ideas are grounded in distributional perspectives on semantics and are connected to standard constructions in automata theory, but to our knowledge they have not been applied to modern language models. We empirically show that the representations obtained from large models align well with human annotations, outperform other zero-shot and prompt-free methods on semantic similarity tasks, and can be used to solve more complex entailment and containment tasks that standard embeddings cannot handle. Finally, we extend our method to represent data from different modalities (e.g., image and text) using multimodal autoregressive models.
AugUndo: Scaling Up Augmentations for Unsupervised Depth Completion
Oct 15, 2023Unsupervised depth completion methods are trained by minimizing sparse depth and image reconstruction error. Block artifacts from resampling, intensity saturation, and occlusions are amongst the many undesirable by-products of common data augmentation schemes that affect image reconstruction quality, and thus the training signal. Hence, typical augmentations on images that are viewed as essential to training pipelines in other vision tasks have seen limited use beyond small image intensity changes and flipping. The sparse depth modality have seen even less as intensity transformations alter the scale of the 3D scene, and geometric transformations may decimate the sparse points during resampling. We propose a method that unlocks a wide range of previously-infeasible geometric augmentations for unsupervised depth completion. This is achieved by reversing, or "undo"-ing, geometric transformations to the coordinates of the output depth, warping the depth map back to the original reference frame. This enables computing the reconstruction losses using the original images and sparse depth maps, eliminating the pitfalls of naive loss computation on the augmented inputs. This simple yet effective strategy allows us to scale up augmentations to boost performance. We demonstrate our method on indoor (VOID) and outdoor (KITTI) datasets where we improve upon three existing methods by an average of 10.4\% across both datasets.
Sub-token ViT Embedding via Stochastic Resonance Transformers
Oct 06, 2023



We discover the presence of quantization artifacts in Vision Transformers (ViTs), which arise due to the image tokenization step inherent in these architectures. These artifacts result in coarsely quantized features, which negatively impact performance, especially on downstream dense prediction tasks. We present a zero-shot method to improve how pre-trained ViTs handle spatial quantization. In particular, we propose to ensemble the features obtained from perturbing input images via sub-token spatial translations, inspired by Stochastic Resonance, a method traditionally applied to climate dynamics and signal processing. We term our method ``Stochastic Resonance Transformer" (SRT), which we show can effectively super-resolve features of pre-trained ViTs, capturing more of the local fine-grained structures that might otherwise be neglected as a result of tokenization. SRT can be applied at any layer, on any task, and does not require any fine-tuning. The advantage of the former is evident when applied to monocular depth prediction, where we show that ensembling model outputs are detrimental while applying SRT on intermediate ViT features outperforms the baseline models by an average of 4.7% and 14.9% on the RMSE and RMSE-log metrics across three different architectures. When applied to semi-supervised video object segmentation, SRT also improves over the baseline models uniformly across all metrics, and by an average of 2.4% in F&J score. We further show that these quantization artifacts can be attenuated to some extent via self-distillation. On the unsupervised salient region segmentation, SRT improves upon the base model by an average of 2.1% on the maxF metric. Finally, despite operating purely on pixel-level features, SRT generalizes to non-dense prediction tasks such as image retrieval and object discovery, yielding consistent improvements of up to 2.6% and 1.0% respectively.
Tangent Transformers for Composition, Privacy and Removal
Jul 20, 2023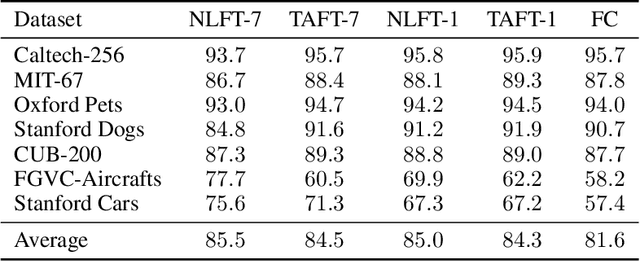
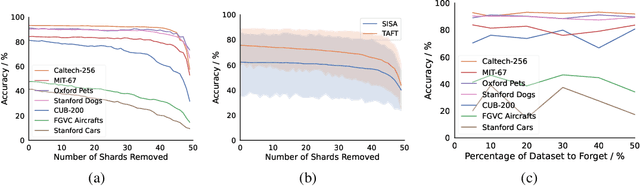
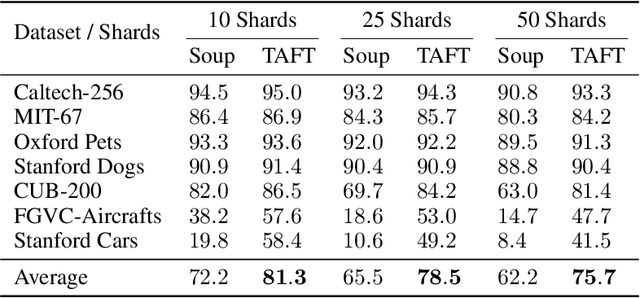
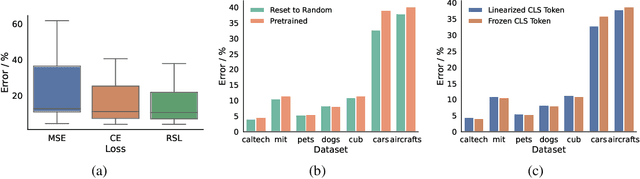
We introduce Tangent Attention Fine-Tuning (TAFT), a method for fine-tuning linearized transformers obtained by computing a First-order Taylor Expansion around a pre-trained initialization. We show that the Jacobian-Vector Product resulting from linearization can be computed efficiently in a single forward pass, reducing training and inference cost to the same order of magnitude as its original non-linear counterpart, while using the same number of parameters. Furthermore, we show that, when applied to various downstream visual classification tasks, the resulting Tangent Transformer fine-tuned with TAFT can perform comparably with fine-tuning the original non-linear network. Since Tangent Transformers are linear with respect to the new set of weights, and the resulting fine-tuning loss is convex, we show that TAFT enjoys several advantages compared to non-linear fine-tuning when it comes to model composition, parallel training, machine unlearning, and differential privacy.
Tangent Model Composition for Ensembling and Continual Fine-tuning
Jul 16, 2023



Tangent Model Composition (TMC) is a method to combine component models independently fine-tuned around a pre-trained point. Component models are tangent vectors to the pre-trained model that can be added, scaled, or subtracted to support incremental learning, ensembling, or unlearning. Component models are composed at inference time via scalar combination, reducing the cost of ensembling to that of a single model. TMC improves accuracy by 4.2% compared to ensembling non-linearly fine-tuned models at a 2.5x to 10x reduction of inference cost, growing linearly with the number of component models. Each component model can be forgotten at zero cost, with no residual effect on the resulting inference. When used for continual fine-tuning, TMC is not constrained by sequential bias and can be executed in parallel on federated data. TMC outperforms recently published continual fine-tuning methods almost uniformly on each setting -- task-incremental, class-incremental, and data-incremental -- on a total of 13 experiments across 3 benchmark datasets, despite not using any replay buffer. TMC is designed for composing models that are local to a pre-trained embedding, but could be extended to more general settings.