 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximally-Informative Retrieval for State Space Model Generation
Jun 13, 2025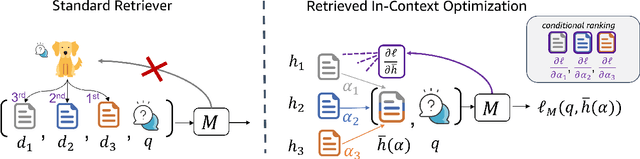
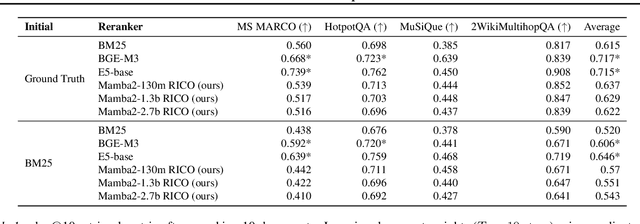
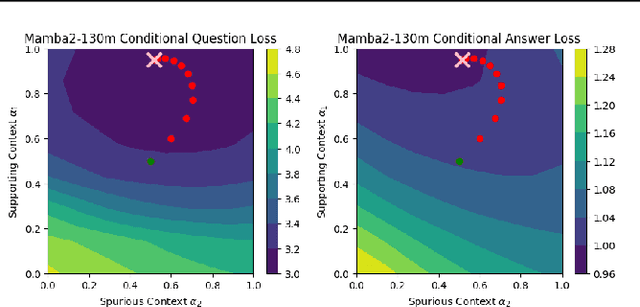
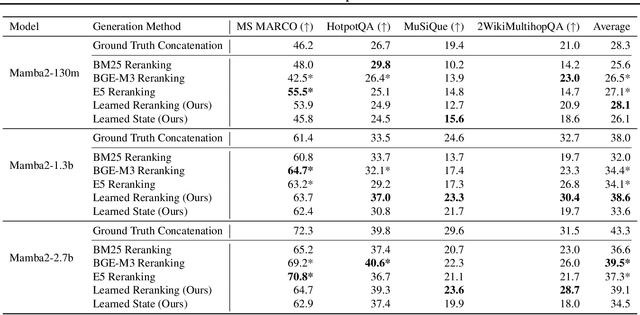
Given a query and dataset, the optimal way of answering the query is to make use all the information available. Modern LLMs exhibit impressive ability to memorize training data, but data not deemed important during training is forgotten, and information outside that training set cannot be made use of. Processing an entire dataset at inference time is infeasible due to the bounded nature of model resources (e.g. context size in transformers or states in state space models), meaning we must resort to external memory. This constraint naturally leads to the following problem: How can we decide based on the present query and model, what among a virtually unbounded set of known data matters for inference? To minimize model uncertainty for a particular query at test-time, we introduce Retrieval In-Context Optimization (RICO), a retrieval method that uses gradients from the LLM itself to learn the optimal mixture of documents for answer generation. Unlike traditional retrieval-augmented generation (RAG), which relies on external heuristics for document retrieval, our approach leverages direct feedback from the model. Theoretically, we show that standard top-$k$ retrieval with model gradients can approximate our optimization procedure, and provide connections to the leave-one-out loss. We demonstrate empirically that by minimizing an unsupervised loss objective in the form of question perplexity, we can achieve comparable retriever metric performance to BM25 with \emph{no finetuning}. Furthermore, when evaluated on quality of the final prediction, our method often outperforms fine-tuned dense retrievers such as E5.
Cycles of Thought: Measuring LLM Confidence through Stable Explanations
Jun 05, 2024



In many high-risk machine learning applications it is essential for a model to indicate when it is uncertain about a prediction. While large language models (LLMs) can reach and even surpass human-level accuracy on a variety of benchmarks, their overconfidence in incorrect responses is still a well-documented failure mode. Traditional methods for ML uncertainty quantification can be difficult to directly adapt to LLMs due to the computational cost of implementation and closed-source nature of many models. A variety of black-box methods have recently been proposed, but these often rely on heuristics such as self-verbalized confidence. We instead propose a framework for measuring an LLM's uncertainty with respect to the distribution of generated explanations for an answer. While utilizing explanations is not a new idea in and of itself, by interpreting each possible model+explanation pair as a test-time classifier we can calculate a posterior answer distribution over the most likely of these classifiers. We demonstrate how a specific instance of this framework using explanation entailment as our classifier likelihood improves confidence score metrics (in particular AURC and AUROC) over baselines across five different datasets. We believe these results indicate that our framework is both a well-principled and effective way of quantifying uncertainty in LLMs.
Local Convergence of Gradient Descent-Ascent for Training Generative Adversarial Networks
May 14, 2023


Generative Adversarial Networks (GANs) are a popular formulation to train generative models for complex high dimensional data. The standard method for training GANs involves a gradient descent-ascent (GDA) procedure on a minimax optimization problem. This procedure is hard to analyze in general due to the nonlinear nature of the dynamics. We study the local dynamics of GDA for training a GAN with a kernel-based discriminator. This convergence analysis is based on a linearization of a non-linear dynamical system that describes the GDA iterations, under an \textit{isolated points model} assumption from [Becker et al. 2022]. Our analysis brings out the effect of the learning rates, regularization, and the bandwidth of the kernel discriminator, on the local convergence rate of GDA. Importantly, we show phase transitions that indicate when the system converges, oscillates, or diverges. We also provide numerical simulations that verify our claims.
High Probability Bounds for Stochastic Continuous Submodular Maximization
Mar 20, 2023



We consider maximization of stochastic monotone continuous submodular functions (CSF) with a diminishing return property. Existing algorithms only guarantee the performance \textit{in expectation}, and do not bound the probability of getting a bad solution. This implies that for a particular run of the algorithms, the solution may be much worse than the provided guarantee in expectation. In this paper, we first empirically verify that this is indeed the case. Then, we provide the first \textit{high-probability} analysis of the existing methods for stochastic CSF maximization, namely PGA, boosted PGA, SCG, and SCG++. Finally, we provide an improved high-probability bound for SCG, under slightly stronger assumptions, with a better convergence rate than that of the expected solution. Through extensive experiments on non-concave quadratic programming (NQP) and optimal budget allocation, we confirm the validity of our bounds and show that even in the worst-case, PGA converges to $OPT/2$, and boosted PGA, SCG, SCG++ converge to $(1 - 1/e)OPT$, but at a slower rate than that of the expected solution.
Instability and Local Minima in GAN Training with Kernel Discriminators
Aug 21, 2022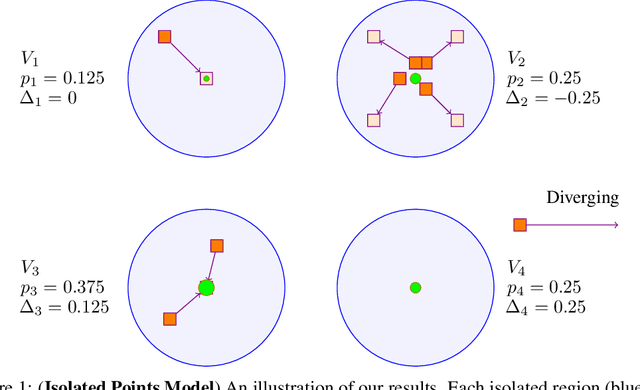
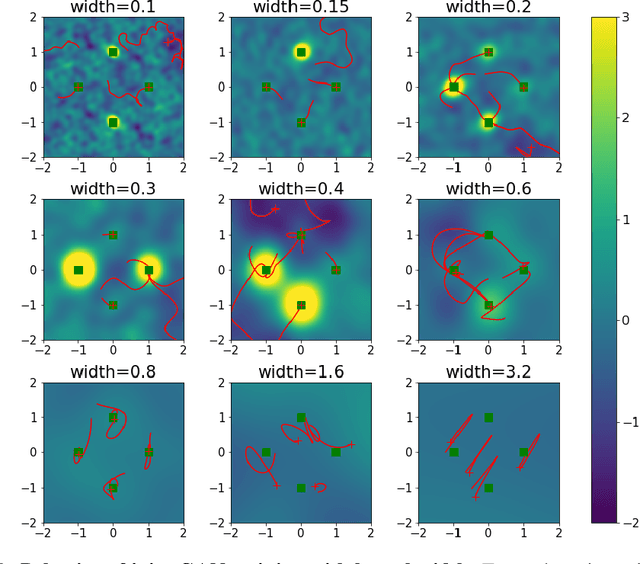
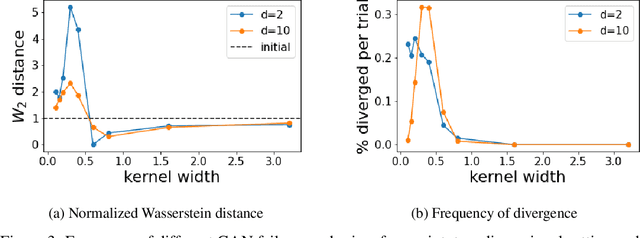
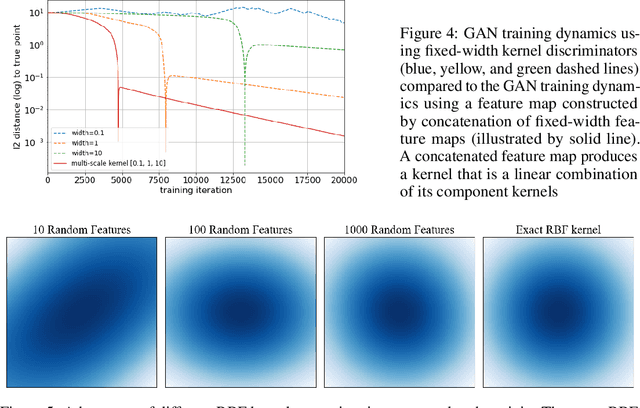
Generative Adversarial Networks (GANs) are a widely-used tool for generative modeling of complex data. Despite their empirical success, the training of GANs is not fully understood due to the min-max optimization of the generator and discriminator. This paper analyzes these joint dynamics when the true samples, as well as the generated samples, are discrete, finite sets, and the discriminator is kernel-based. A simple yet expressive framework for analyzing training called the $\textit{Isolated Points Model}$ is introduced. In the proposed model, the distance between true samples greatly exceeds the kernel width, so each generated point is influenced by at most one true point. Our model enables precise characterization of the conditions for convergence, both to good and bad minima. In particular, the analysis explains two common failure modes: (i) an approximate mode collapse and (ii) divergence. Numerical simulations are provided that predictably replicate these behaviors.