 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePICASO: Permutation-Invariant Context Composition with State Space Models
Paper and Code
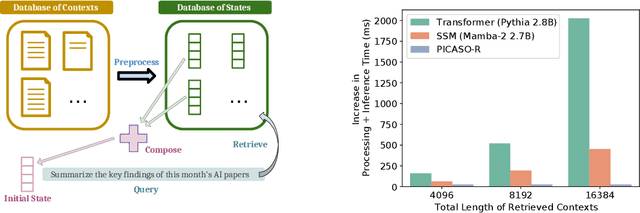

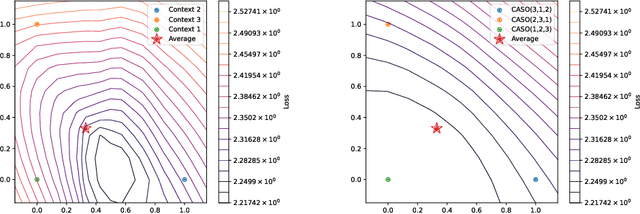

Providing Large Language Models with relevant contextual knowledge at inference time has been shown to greatly improve the quality of their generations. This is often achieved by prepending informative passages of text, or 'contexts', retrieved from external knowledge bases to their input. However, processing additional contexts online incurs significant computation costs that scale with their length. State Space Models (SSMs) offer a promising solution by allowing a database of contexts to be mapped onto fixed-dimensional states from which to start the generation. A key challenge arises when attempting to leverage information present across multiple contexts, since there is no straightforward way to condition generation on multiple independent states in existing SSMs. To address this, we leverage a simple mathematical relation derived from SSM dynamics to compose multiple states into one that efficiently approximates the effect of concatenating textual contexts. Since the temporal ordering of contexts can often be uninformative, we enforce permutation-invariance by efficiently averaging states obtained via our composition algorithm across all possible context orderings. We evaluate our resulting method on WikiText and MSMARCO in both zero-shot and fine-tuned settings, and show that we can match the strongest performing baseline while enjoying on average 5.4x speedup.