 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeanings and Feelings of Large Language Models: Observability of Latent States in Generative AI
Paper and Code
May 22, 2024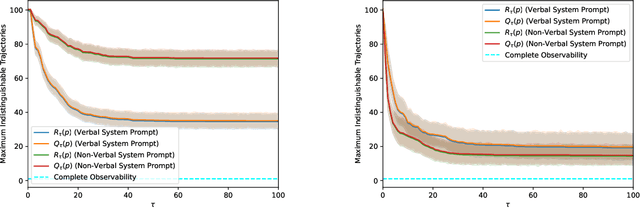
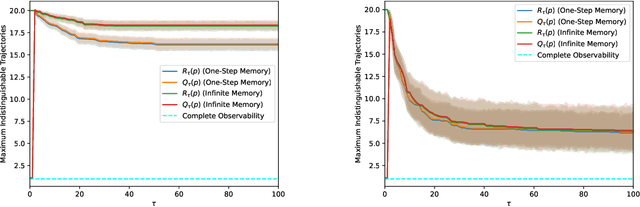

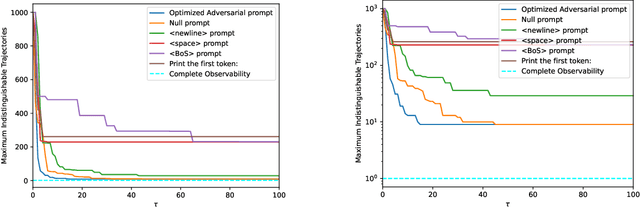
We tackle the question of whether Large Language Models (LLMs), viewed as dynamical systems with state evolving in the embedding space of symbolic tokens, are observable. That is, whether there exist multiple 'mental' state trajectories that yield the same sequence of generated tokens, or sequences that belong to the same Nerode equivalence class ('meaning'). If not observable, mental state trajectories ('experiences') evoked by an input ('perception') or by feedback from the model's own state ('thoughts') could remain self-contained and evolve unbeknown to the user while being potentially accessible to the model provider. Such "self-contained experiences evoked by perception or thought" are akin to what the American Psychological Association (APA) defines as 'feelings'. Beyond the lexical curiosity, we show that current LLMs implemented by autoregressive Transformers cannot have 'feelings' according to this definition: The set of state trajectories indistinguishable from the tokenized output is a singleton. But if there are 'system prompts' not visible to the user, then the set of indistinguishable trajectories becomes non-trivial, and there can be multiple state trajectories that yield the same verbalized output. We prove these claims analytically, and show examples of modifications to standard LLMs that engender such 'feelings.' Our analysis sheds light on possible designs that would enable a model to perform non-trivial computation that is not visible to the user, as well as on controls that the provider of services using the model could take to prevent unintended behavior.