 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTree: Speculative Tree Decoding for Hybrid State-Space Models
May 20, 2025



Speculative decoding is a technique to leverage hardware concurrency to improve the efficiency of large-scale autoregressive (AR) Transformer models by enabling multiple steps of token generation in a single forward pass. State-space models (SSMs) are already more efficient than AR Transformers, since their state summarizes all past data with no need to cache or re-process tokens in the sliding window context. However, their state can also comprise thousands of tokens; so, speculative decoding has recently been extended to SSMs. Existing approaches, however, do not leverage the tree-based verification methods, since current SSMs lack the means to compute a token tree efficiently. We propose the first scalable algorithm to perform tree-based speculative decoding in state-space models (SSMs) and hybrid architectures of SSMs and Transformer layers. We exploit the structure of accumulated state transition matrices to facilitate tree-based speculative decoding with minimal overhead to current SSM state update implementations. With the algorithm, we describe a hardware-aware implementation that improves naive application of AR Transformer tree-based speculative decoding methods to SSMs. Furthermore, we outperform vanilla speculative decoding with SSMs even with a baseline drafting model and tree structure on three different benchmarks, opening up opportunities for further speed up with SSM and hybrid model inference. Code will be released upon paper acceptance.
RSA: Resolving Scale Ambiguities in Monocular Depth Estimators through Language Descriptions
Oct 03, 2024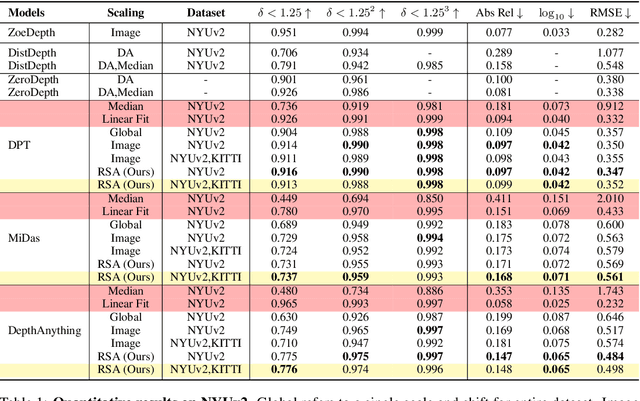
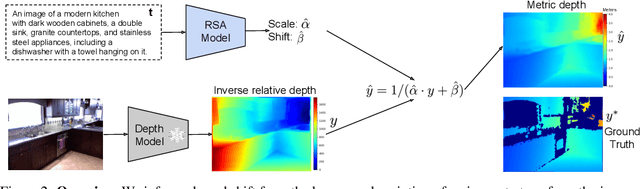
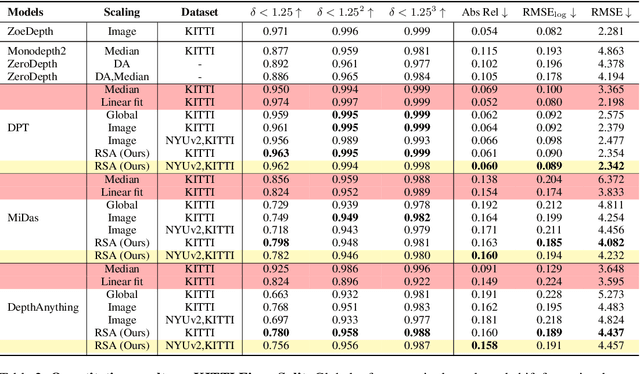

We propose a method for metric-scale monocular depth estimation. Inferring depth from a single image is an ill-posed problem due to the loss of scale from perspective projection during the image formation process. Any scale chosen is a bias, typically stemming from training on a dataset; hence, existing works have instead opted to use relative (normalized, inverse) depth. Our goal is to recover metric-scaled depth maps through a linear transformation. The crux of our method lies in the observation that certain objects (e.g., cars, trees, street signs) are typically found or associated with certain types of scenes (e.g., outdoor). We explore whether language descriptions can be used to transform relative depth predictions to those in metric scale. Our method, RSA, takes as input a text caption describing objects present in an image and outputs the parameters of a linear transformation which can be applied globally to a relative depth map to yield metric-scaled depth predictions. We demonstrate our method on recent general-purpose monocular depth models on indoors (NYUv2) and outdoors (KITTI). When trained on multiple datasets, RSA can serve as a general alignment module in zero-shot settings. Our method improves over common practices in aligning relative to metric depth and results in predictions that are comparable to an upper bound of fitting relative depth to ground truth via a linear transformation.
WorDepth: Variational Language Prior for Monocular Depth Estimation
Apr 05, 2024



Three-dimensional (3D) reconstruction from a single image is an ill-posed problem with inherent ambiguities, i.e. scale. Predicting a 3D scene from text description(s) is similarly ill-posed, i.e. spatial arrangements of objects described. We investigate the question of whether two inherently ambiguous modalities can be used in conjunction to produce metric-scaled reconstructions. To test this, we focus on monocular depth estimation, the problem of predicting a dense depth map from a single image, but with an additional text caption describing the scene. To this end, we begin by encoding the text caption as a mean and standard deviation; using a variational framework, we learn the distribution of the plausible metric reconstructions of 3D scenes corresponding to the text captions as a prior. To "select" a specific reconstruction or depth map, we encode the given image through a conditional sampler that samples from the latent space of the variational text encoder, which is then decoded to the output depth map. Our approach is trained alternatingly between the text and image branches: in one optimization step, we predict the mean and standard deviation from the text description and sample from a standard Gaussian, and in the other, we sample using a (image) conditional sampler. Once trained, we directly predict depth from the encoded text using the conditional sampler. We demonstrate our approach on indoor (NYUv2) and outdoor (KITTI) scenarios, where we show that language can consistently improve performance in both.
AugUndo: Scaling Up Augmentations for Unsupervised Depth Completion
Oct 15, 2023Unsupervised depth completion methods are trained by minimizing sparse depth and image reconstruction error. Block artifacts from resampling, intensity saturation, and occlusions are amongst the many undesirable by-products of common data augmentation schemes that affect image reconstruction quality, and thus the training signal. Hence, typical augmentations on images that are viewed as essential to training pipelines in other vision tasks have seen limited use beyond small image intensity changes and flipping. The sparse depth modality have seen even less as intensity transformations alter the scale of the 3D scene, and geometric transformations may decimate the sparse points during resampling. We propose a method that unlocks a wide range of previously-infeasible geometric augmentations for unsupervised depth completion. This is achieved by reversing, or "undo"-ing, geometric transformations to the coordinates of the output depth, warping the depth map back to the original reference frame. This enables computing the reconstruction losses using the original images and sparse depth maps, eliminating the pitfalls of naive loss computation on the augmented inputs. This simple yet effective strategy allows us to scale up augmentations to boost performance. We demonstrate our method on indoor (VOID) and outdoor (KITTI) datasets where we improve upon three existing methods by an average of 10.4\% across both datasets.
Sub-token ViT Embedding via Stochastic Resonance Transformers
Oct 06, 2023



We discover the presence of quantization artifacts in Vision Transformers (ViTs), which arise due to the image tokenization step inherent in these architectures. These artifacts result in coarsely quantized features, which negatively impact performance, especially on downstream dense prediction tasks. We present a zero-shot method to improve how pre-trained ViTs handle spatial quantization. In particular, we propose to ensemble the features obtained from perturbing input images via sub-token spatial translations, inspired by Stochastic Resonance, a method traditionally applied to climate dynamics and signal processing. We term our method ``Stochastic Resonance Transformer" (SRT), which we show can effectively super-resolve features of pre-trained ViTs, capturing more of the local fine-grained structures that might otherwise be neglected as a result of tokenization. SRT can be applied at any layer, on any task, and does not require any fine-tuning. The advantage of the former is evident when applied to monocular depth prediction, where we show that ensembling model outputs are detrimental while applying SRT on intermediate ViT features outperforms the baseline models by an average of 4.7% and 14.9% on the RMSE and RMSE-log metrics across three different architectures. When applied to semi-supervised video object segmentation, SRT also improves over the baseline models uniformly across all metrics, and by an average of 2.4% in F&J score. We further show that these quantization artifacts can be attenuated to some extent via self-distillation. On the unsupervised salient region segmentation, SRT improves upon the base model by an average of 2.1% on the maxF metric. Finally, despite operating purely on pixel-level features, SRT generalizes to non-dense prediction tasks such as image retrieval and object discovery, yielding consistent improvements of up to 2.6% and 1.0% respectively.
Stain-invariant self supervised learning for histopathology image analysis
Nov 14, 2022

We present a self-supervised algorithm for several classification tasks within hematoxylin and eosin (H&E) stained images of breast cancer. Our method is robust to stain variations inherent to the histology images acquisition process, which has limited the applicability of automated analysis tools. We address this problem by imposing constraints a learnt latent space which leverages stain normalization techniques during training. At every iteration, we select an image as a normalization target and generate a version of every image in the batch normalized to that target. We minimize the distance between the embeddings that correspond to the same image under different staining variations while maximizing the distance between other samples. We show that our method not only improves robustness to stain variations across multi-center data, but also classification performance through extensive experiments on various normalization targets and methods. Our method achieves the state-of-the-art performance on several publicly available breast cancer datasets ranging from tumor classification (CAMELYON17) and subtyping (BRACS) to HER2 status classification and treatment response prediction.
Small Lesion Segmentation in Brain MRIs with Subpixel Embedding
Sep 18, 2021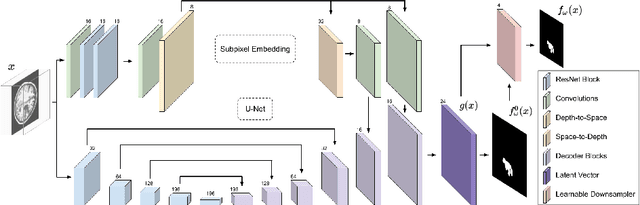

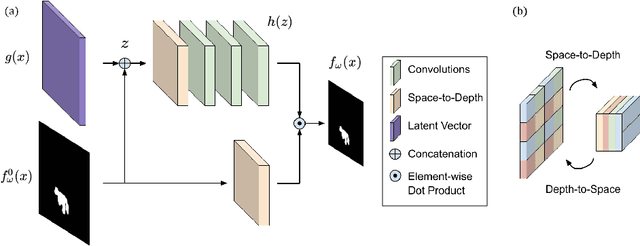
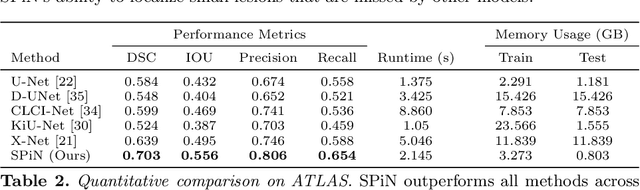
We present a method to segment MRI scans of the human brain into ischemic stroke lesion and normal tissues. We propose a neural network architecture in the form of a standard encoder-decoder where predictions are guided by a spatial expansion embedding network. Our embedding network learns features that can resolve detailed structures in the brain without the need for high-resolution training images, which are often unavailable and expensive to acquire. Alternatively, the encoder-decoder learns global structures by means of striding and max pooling. Our embedding network complements the encoder-decoder architecture by guiding the decoder with fine-grained details lost to spatial downsampling during the encoder stage. Unlike previous works, our decoder outputs at 2 times the input resolution, where a single pixel in the input resolution is predicted by four neighboring subpixels in our output. To obtain the output at the original scale, we propose a learnable downsampler (as opposed to hand-crafted ones e.g. bilinear) that combines subpixel predictions. Our approach improves the baseline architecture by approximately 11.7% and achieves the state of the art on the ATLAS public benchmark dataset with a smaller memory footprint and faster runtime than the best competing method. Our source code has been made available at: https://github.com/alexklwong/subpixel-embedding-segmentation.