 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoffee: Controllable Diffusion Fine-tuning
Nov 18, 2025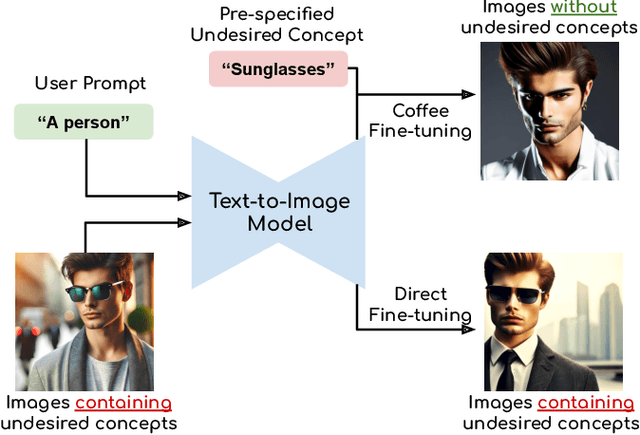
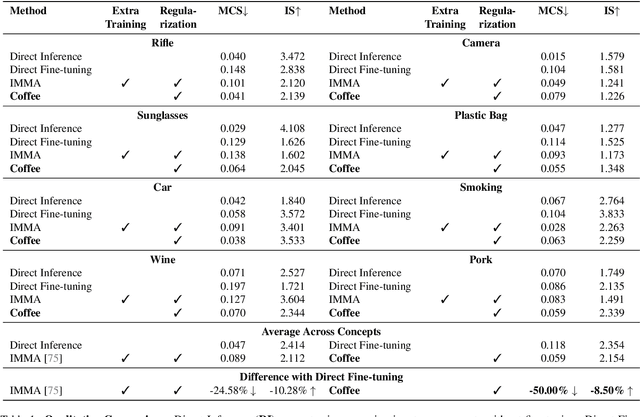

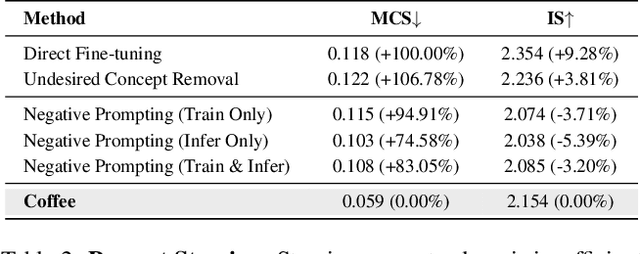
Text-to-image diffusion models can generate diverse content with flexible prompts, which makes them well-suited for customization through fine-tuning with a small amount of user-provided data. However, controllable fine-tuning that prevents models from learning undesired concepts present in the fine-tuning data, and from entangling those concepts with user prompts, remains an open challenge. It is crucial for downstream tasks like bias mitigation, preventing malicious adaptation, attribute disentanglement, and generalizable fine-tuning of diffusion policy. We propose Coffee that allows using language to specify undesired concepts to regularize the adaptation process. The crux of our method lies in keeping the embeddings of the user prompt from aligning with undesired concepts. Crucially, Coffee requires no additional training and enables flexible modification of undesired concepts by modifying textual descriptions. We evaluate Coffee by fine-tuning on images associated with user prompts paired with undesired concepts. Experimental results demonstrate that Coffee can prevent text-to-image models from learning specified undesired concepts during fine-tuning and outperforms existing methods. Code will be released upon acceptance.
ProtoDepth: Unsupervised Continual Depth Completion with Prototypes
Mar 17, 2025



We present ProtoDepth, a novel prototype-based approach for continual learning of unsupervised depth completion, the multimodal 3D reconstruction task of predicting dense depth maps from RGB images and sparse point clouds. The unsupervised learning paradigm is well-suited for continual learning, as ground truth is not needed. However, when training on new non-stationary distributions, depth completion models will catastrophically forget previously learned information. We address forgetting by learning prototype sets that adapt the latent features of a frozen pretrained model to new domains. Since the original weights are not modified, ProtoDepth does not forget when test-time domain identity is known. To extend ProtoDepth to the challenging setting where the test-time domain identity is withheld, we propose to learn domain descriptors that enable the model to select the appropriate prototype set for inference. We evaluate ProtoDepth on benchmark dataset sequences, where we reduce forgetting compared to baselines by 52.2% for indoor and 53.2% for outdoor to achieve the state of the art.
Efficient Interactive 3D Multi-Object Removal
Jan 30, 2025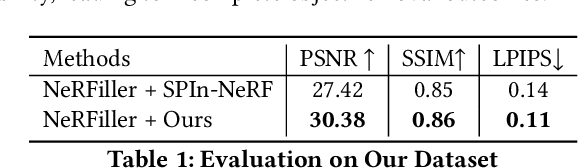
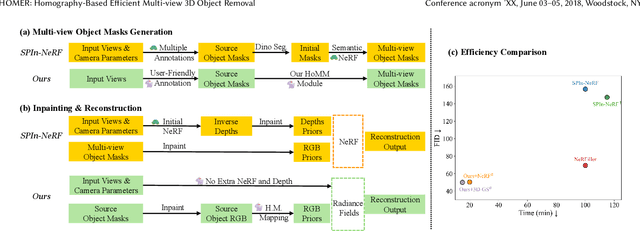
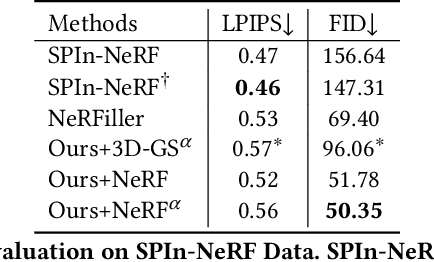
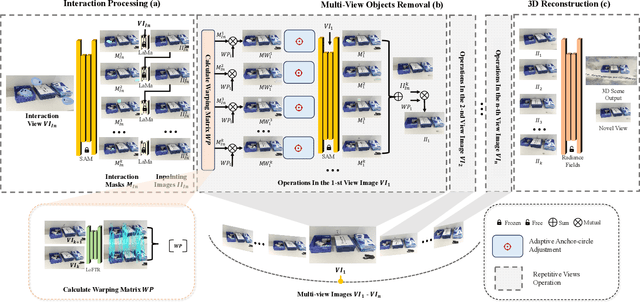
Object removal is of great significance to 3D scene understanding, essential for applications in content filtering and scene editing. Current mainstream methods primarily focus on removing individual objects, with a few methods dedicated to eliminating an entire area or all objects of a certain category. They however confront the challenge of insufficient granularity and flexibility for real-world applications, where users demand tailored excision and preservation of objects within defined zones. In addition, most of the current methods require kinds of priors when addressing multi-view inpainting, which is time-consuming. To address these limitations, we propose an efficient and user-friendly pipeline for 3D multi-object removal, enabling users to flexibly select areas and define objects for removal or preservation. Concretely, to ensure object consistency and correspondence across multiple views, we propose a novel mask matching and refinement module, which integrates homography-based warping with high-confidence anchor points for segmentation. By leveraging the IoU joint shape context distance loss, we enhance the accuracy of warped masks and improve subsequent inpainting processes. Considering the current immaturity of 3D multi-object removal, we provide a new evaluation dataset to bridge the developmental void. Experimental results demonstrate that our method significantly reduces computational costs, achieving processing speeds more than 80% faster than state-of-the-art methods while maintaining equivalent or higher reconstruction quality.
PriorDiffusion: Leverage Language Prior in Diffusion Models for Monocular Depth Estimation
Nov 24, 2024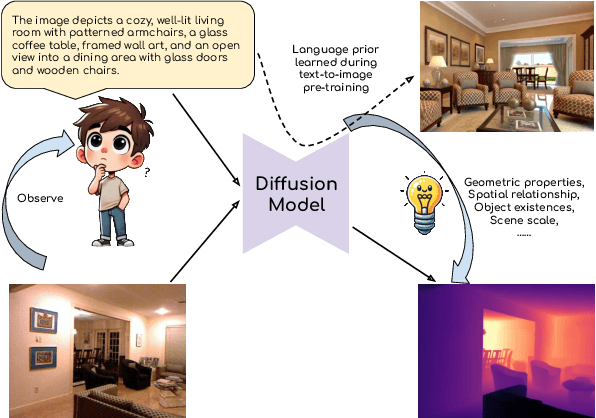
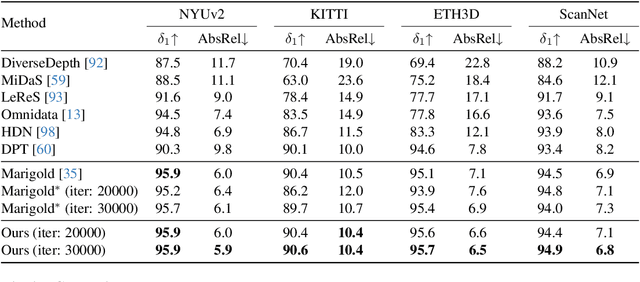
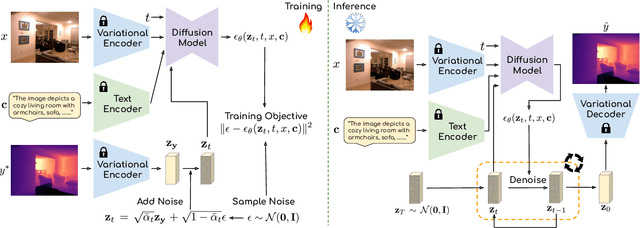
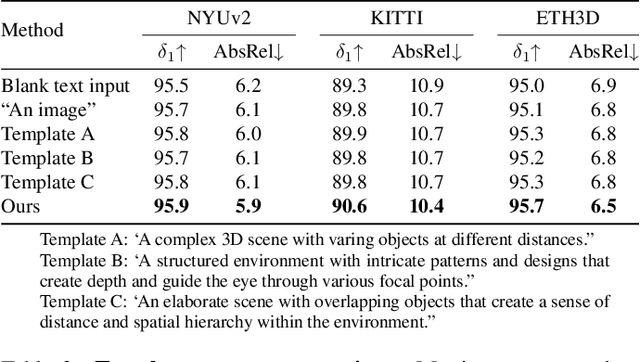
This paper explores the potential of leveraging language priors learned by text-to-image diffusion models to address ambiguity and visual nuisance in monocular depth estimation. Particularly, traditional monocular depth estimation suffers from inherent ambiguity due to the absence of stereo or multi-view depth cues, and nuisance due to lack of robustness of vision. We argue that language prior in diffusion models can enhance monocular depth estimation by leveraging the geometric prior aligned with the language description, which is learned during text-to-image pre-training. To generate images that reflect the text properly, the model must comprehend the size and shape of specified objects, their spatial relationship, and the scale of the scene. Thus, we propose PriorDiffusion, using a pre-trained text-to-image diffusion model that takes both image and text description that aligned with the scene to infer affine-invariant depth through a denoising process. We also show that language priors can guide the model's attention to specific regions and help it perceive the 3D scene in alignment with user intent. Simultaneously, it acts as a constraint to accelerate the convergence of the diffusion trajectory, since learning 3D properties from a condensed, low-dimensional language feature is more efficient compared with learning from a redundant, high-dimensional image feature. By training on HyperSim and Virtual KITTI, we achieve state-of-the-art zero-shot performance and a faster convergence speed, compared with other diffusion-based depth estimators, across NYUv2, KITTI, ETH3D, and ScanNet.
RSA: Resolving Scale Ambiguities in Monocular Depth Estimators through Language Descriptions
Oct 03, 2024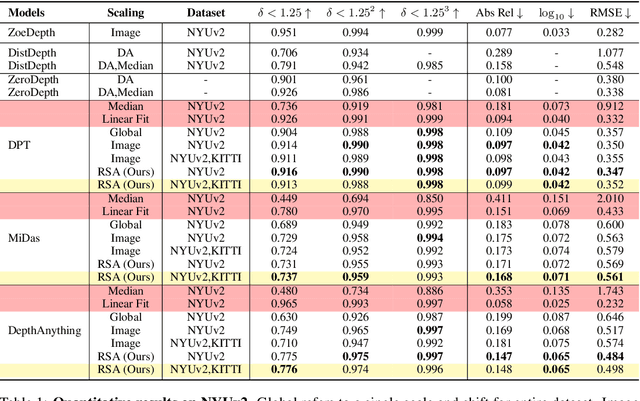
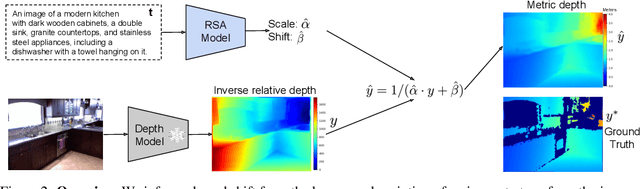
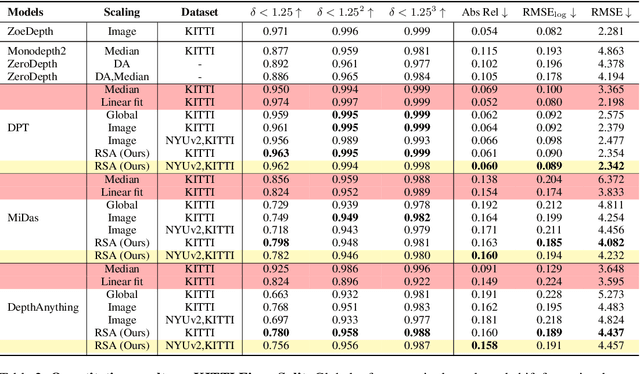

We propose a method for metric-scale monocular depth estimation. Inferring depth from a single image is an ill-posed problem due to the loss of scale from perspective projection during the image formation process. Any scale chosen is a bias, typically stemming from training on a dataset; hence, existing works have instead opted to use relative (normalized, inverse) depth. Our goal is to recover metric-scaled depth maps through a linear transformation. The crux of our method lies in the observation that certain objects (e.g., cars, trees, street signs) are typically found or associated with certain types of scenes (e.g., outdoor). We explore whether language descriptions can be used to transform relative depth predictions to those in metric scale. Our method, RSA, takes as input a text caption describing objects present in an image and outputs the parameters of a linear transformation which can be applied globally to a relative depth map to yield metric-scaled depth predictions. We demonstrate our method on recent general-purpose monocular depth models on indoors (NYUv2) and outdoors (KITTI). When trained on multiple datasets, RSA can serve as a general alignment module in zero-shot settings. Our method improves over common practices in aligning relative to metric depth and results in predictions that are comparable to an upper bound of fitting relative depth to ground truth via a linear transformation.
NeuroBind: Towards Unified Multimodal Representations for Neural Signals
Jul 19, 2024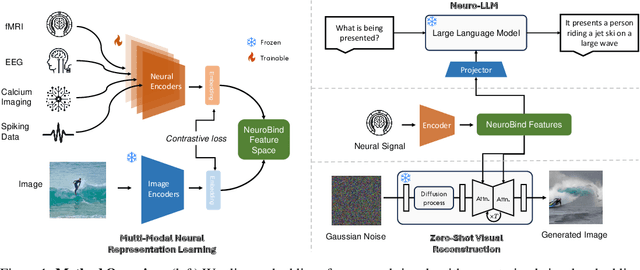
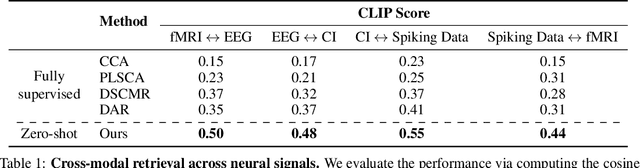

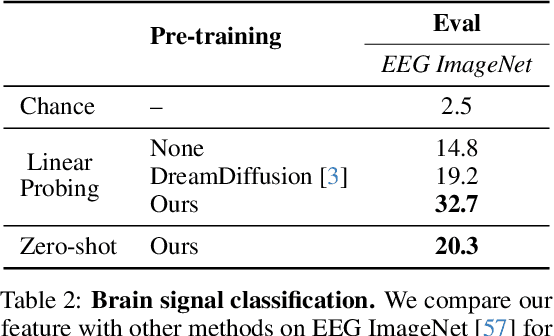
Understanding neural activity and information representation is crucial for advancing knowledge of brain function and cognition. Neural activity, measured through techniques like electrophysiology and neuroimaging, reflects various aspects of information processing. Recent advances in deep neural networks offer new approaches to analyzing these signals using pre-trained models. However, challenges arise due to discrepancies between different neural signal modalities and the limited scale of high-quality neural data. To address these challenges, we present NeuroBind, a general representation that unifies multiple brain signal types, including EEG, fMRI, calcium imaging, and spiking data. To achieve this, we align neural signals in these image-paired neural datasets to pre-trained vision-language embeddings. Neurobind is the first model that studies different neural modalities interconnectedly and is able to leverage high-resource modality models for various neuroscience tasks. We also showed that by combining information from different neural signal modalities, NeuroBind enhances downstream performance, demonstrating the effectiveness of the complementary strengths of different neural modalities. As a result, we can leverage multiple types of neural signals mapped to the same space to improve downstream tasks, and demonstrate the complementary strengths of different neural modalities. This approach holds significant potential for advancing neuroscience research, improving AI systems, and developing neuroprosthetics and brain-computer interfaces.
WorDepth: Variational Language Prior for Monocular Depth Estimation
Apr 05, 2024



Three-dimensional (3D) reconstruction from a single image is an ill-posed problem with inherent ambiguities, i.e. scale. Predicting a 3D scene from text description(s) is similarly ill-posed, i.e. spatial arrangements of objects described. We investigate the question of whether two inherently ambiguous modalities can be used in conjunction to produce metric-scaled reconstructions. To test this, we focus on monocular depth estimation, the problem of predicting a dense depth map from a single image, but with an additional text caption describing the scene. To this end, we begin by encoding the text caption as a mean and standard deviation; using a variational framework, we learn the distribution of the plausible metric reconstructions of 3D scenes corresponding to the text captions as a prior. To "select" a specific reconstruction or depth map, we encode the given image through a conditional sampler that samples from the latent space of the variational text encoder, which is then decoded to the output depth map. Our approach is trained alternatingly between the text and image branches: in one optimization step, we predict the mean and standard deviation from the text description and sample from a standard Gaussian, and in the other, we sample using a (image) conditional sampler. Once trained, we directly predict depth from the encoded text using the conditional sampler. We demonstrate our approach on indoor (NYUv2) and outdoor (KITTI) scenarios, where we show that language can consistently improve performance in both.
Binding Touch to Everything: Learning Unified Multimodal Tactile Representations
Jan 31, 2024The ability to associate touch with other modalities has huge implications for humans and computational systems. However, multimodal learning with touch remains challenging due to the expensive data collection process and non-standardized sensor outputs. We introduce UniTouch, a unified tactile model for vision-based touch sensors connected to multiple modalities, including vision, language, and sound. We achieve this by aligning our UniTouch embeddings to pretrained image embeddings already associated with a variety of other modalities. We further propose learnable sensor-specific tokens, allowing the model to learn from a set of heterogeneous tactile sensors, all at the same time. UniTouch is capable of conducting various touch sensing tasks in the zero-shot setting, from robot grasping prediction to touch image question answering. To the best of our knowledge, UniTouch is the first to demonstrate such capabilities. Project page: https://cfeng16.github.io/UniTouch/
iQuery: Instruments as Queries for Audio-Visual Sound Separation
Dec 08, 2022

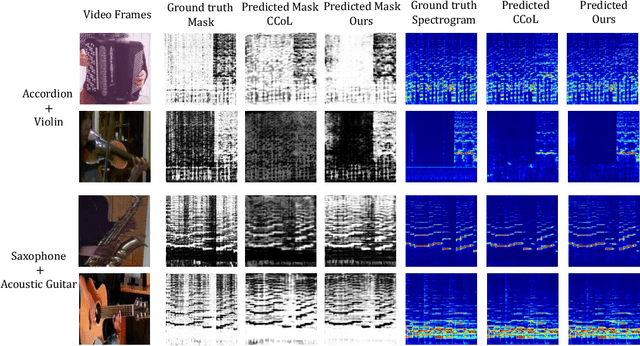

Current audio-visual separation methods share a standard architecture design where an audio encoder-decoder network is fused with visual encoding features at the encoder bottleneck. This design confounds the learning of multi-modal feature encoding with robust sound decoding for audio separation. To generalize to a new instrument: one must finetune the entire visual and audio network for all musical instruments. We re-formulate visual-sound separation task and propose Instrument as Query (iQuery) with a flexible query expansion mechanism. Our approach ensures cross-modal consistency and cross-instrument disentanglement. We utilize "visually named" queries to initiate the learning of audio queries and use cross-modal attention to remove potential sound source interference at the estimated waveforms. To generalize to a new instrument or event class, drawing inspiration from the text-prompt design, we insert an additional query as an audio prompt while freezing the attention mechanism. Experimental results on three benchmarks demonstrate that our iQuery improves audio-visual sound source separation performance.
PointCLIP V2: Adapting CLIP for Powerful 3D Open-world Learning
Nov 21, 2022



Contrastive Language-Image Pre-training (CLIP) has shown promising open-world performance on 2D image tasks, while its transferred capacity on 3D point clouds, i.e., PointCLIP, is still far from satisfactory. In this work, we propose PointCLIP V2, a powerful 3D open-world learner, to fully unleash the potential of CLIP on 3D point cloud data. First, we introduce a realistic shape projection module to generate more realistic depth maps for CLIP's visual encoder, which is quite efficient and narrows the domain gap between projected point clouds with natural images. Second, we leverage large-scale language models to automatically design a more descriptive 3D-semantic prompt for CLIP's textual encoder, instead of the previous hand-crafted one. Without introducing any training in 3D domains, our approach significantly surpasses PointCLIP by +42.90%, +40.44%, and +28.75% accuracy on three datasets for zero-shot 3D classification. Furthermore, PointCLIP V2 can be extended to few-shot classification, zero-shot part segmentation, and zero-shot 3D object detection in a simple manner, demonstrating our superior generalization ability for 3D open-world learning. Code will be available at https://github.com/yangyangyang127/PointCLIP_V2.