 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoDepth: Unsupervised Continual Depth Completion with Prototypes
Mar 17, 2025



We present ProtoDepth, a novel prototype-based approach for continual learning of unsupervised depth completion, the multimodal 3D reconstruction task of predicting dense depth maps from RGB images and sparse point clouds. The unsupervised learning paradigm is well-suited for continual learning, as ground truth is not needed. However, when training on new non-stationary distributions, depth completion models will catastrophically forget previously learned information. We address forgetting by learning prototype sets that adapt the latent features of a frozen pretrained model to new domains. Since the original weights are not modified, ProtoDepth does not forget when test-time domain identity is known. To extend ProtoDepth to the challenging setting where the test-time domain identity is withheld, we propose to learn domain descriptors that enable the model to select the appropriate prototype set for inference. We evaluate ProtoDepth on benchmark dataset sequences, where we reduce forgetting compared to baselines by 52.2% for indoor and 53.2% for outdoor to achieve the state of the art.
PriorDiffusion: Leverage Language Prior in Diffusion Models for Monocular Depth Estimation
Nov 24, 2024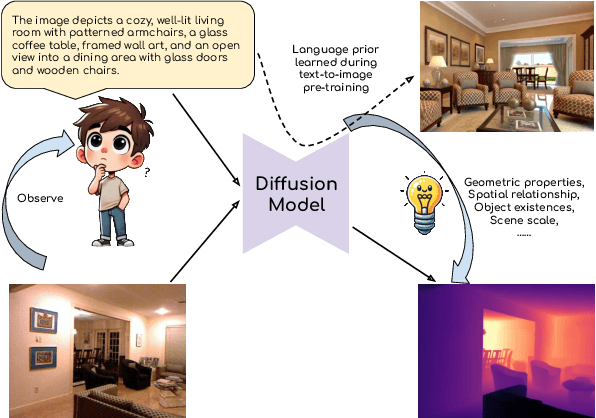
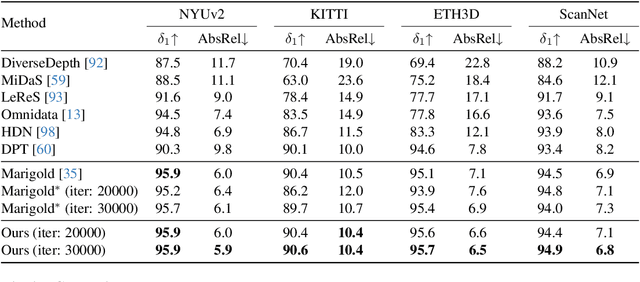
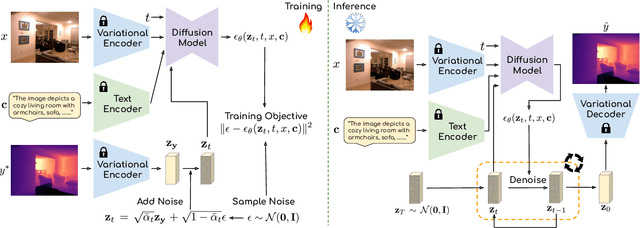
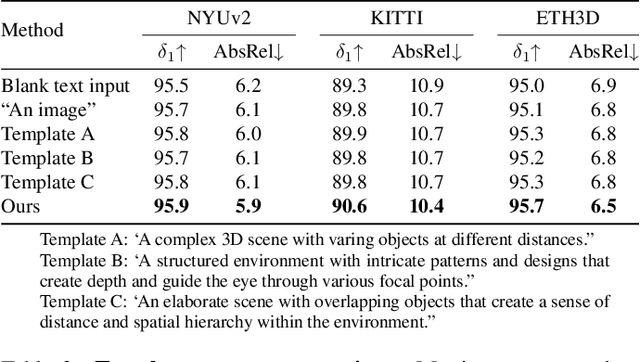
This paper explores the potential of leveraging language priors learned by text-to-image diffusion models to address ambiguity and visual nuisance in monocular depth estimation. Particularly, traditional monocular depth estimation suffers from inherent ambiguity due to the absence of stereo or multi-view depth cues, and nuisance due to lack of robustness of vision. We argue that language prior in diffusion models can enhance monocular depth estimation by leveraging the geometric prior aligned with the language description, which is learned during text-to-image pre-training. To generate images that reflect the text properly, the model must comprehend the size and shape of specified objects, their spatial relationship, and the scale of the scene. Thus, we propose PriorDiffusion, using a pre-trained text-to-image diffusion model that takes both image and text description that aligned with the scene to infer affine-invariant depth through a denoising process. We also show that language priors can guide the model's attention to specific regions and help it perceive the 3D scene in alignment with user intent. Simultaneously, it acts as a constraint to accelerate the convergence of the diffusion trajectory, since learning 3D properties from a condensed, low-dimensional language feature is more efficient compared with learning from a redundant, high-dimensional image feature. By training on HyperSim and Virtual KITTI, we achieve state-of-the-art zero-shot performance and a faster convergence speed, compared with other diffusion-based depth estimators, across NYUv2, KITTI, ETH3D, and ScanNet.