 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuleSmith: Multi-Agent LLMs for Automated Game Balancing
Feb 05, 2026Game balancing is a longstanding challenge requiring repeated playtesting, expert intuition, and extensive manual tuning. We introduce RuleSmith, the first framework that achieves automated game balancing by leveraging the reasoning capabilities of multi-agent LLMs. It couples a game engine, multi-agent LLMs self-play, and Bayesian optimization operating over a multi-dimensional rule space. As a proof of concept, we instantiate RuleSmith on CivMini, a simplified civilization-style game containing heterogeneous factions, economy systems, production rules, and combat mechanics, all governed by tunable parameters. LLM agents interpret textual rulebooks and game states to generate actions, to conduct fast evaluation of balance metrics such as win-rate disparities. To search the parameter landscape efficiently, we integrate Bayesian optimization with acquisition-based adaptive sampling and discrete projection: promising candidates receive more evaluation games for accurate assessment, while exploratory candidates receive fewer games for efficient exploration. Experiments show that RuleSmith converges to highly balanced configurations and provides interpretable rule adjustments that can be directly applied to downstream game systems. Our results illustrate that LLM simulation can serve as a powerful surrogate for automating design and balancing in complex multi-agent environments.
Tri-Ergon: Fine-grained Video-to-Audio Generation with Multi-modal Conditions and LUFS Control
Dec 29, 2024Video-to-audio (V2A) generation utilizes visual-only video features to produce realistic sounds that correspond to the scene. However, current V2A models often lack fine-grained control over the generated audio, especially in terms of loudness variation and the incorporation of multi-modal conditions. To overcome these limitations, we introduce Tri-Ergon, a diffusion-based V2A model that incorporates textual, auditory, and pixel-level visual prompts to enable detailed and semantically rich audio synthesis. Additionally, we introduce Loudness Units relative to Full Scale (LUFS) embedding, which allows for precise manual control of the loudness changes over time for individual audio channels, enabling our model to effectively address the intricate correlation of video and audio in real-world Foley workflows. Tri-Ergon is capable of creating 44.1 kHz high-fidelity stereo audio clips of varying lengths up to 60 seconds, which significantly outperforms existing state-of-the-art V2A methods that typically generate mono audio for a fixed duration.
PriorDiffusion: Leverage Language Prior in Diffusion Models for Monocular Depth Estimation
Nov 24, 2024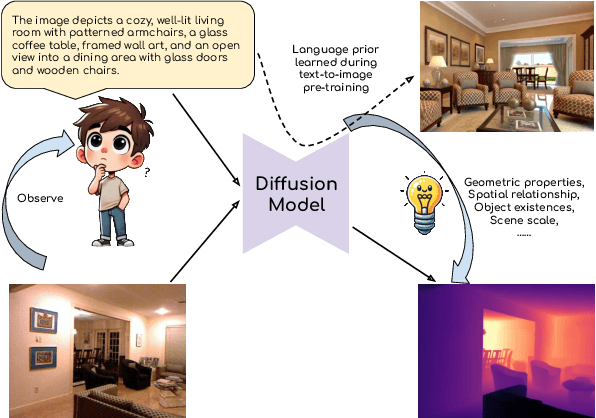
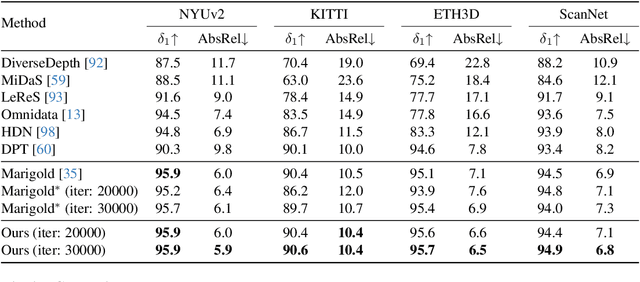
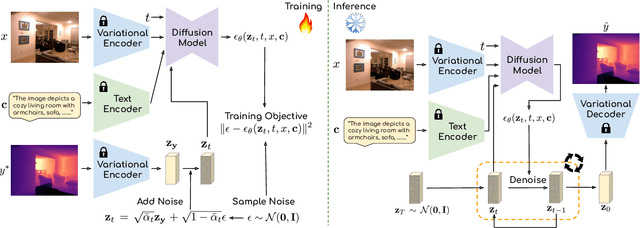
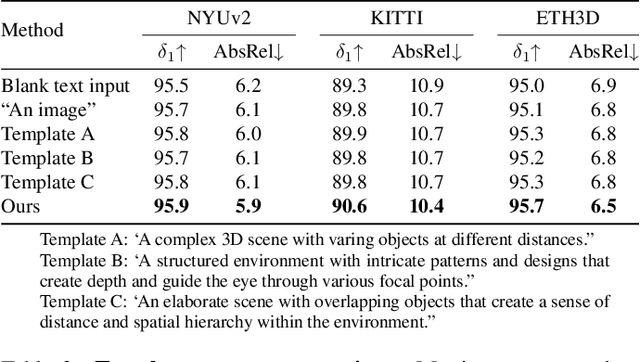
This paper explores the potential of leveraging language priors learned by text-to-image diffusion models to address ambiguity and visual nuisance in monocular depth estimation. Particularly, traditional monocular depth estimation suffers from inherent ambiguity due to the absence of stereo or multi-view depth cues, and nuisance due to lack of robustness of vision. We argue that language prior in diffusion models can enhance monocular depth estimation by leveraging the geometric prior aligned with the language description, which is learned during text-to-image pre-training. To generate images that reflect the text properly, the model must comprehend the size and shape of specified objects, their spatial relationship, and the scale of the scene. Thus, we propose PriorDiffusion, using a pre-trained text-to-image diffusion model that takes both image and text description that aligned with the scene to infer affine-invariant depth through a denoising process. We also show that language priors can guide the model's attention to specific regions and help it perceive the 3D scene in alignment with user intent. Simultaneously, it acts as a constraint to accelerate the convergence of the diffusion trajectory, since learning 3D properties from a condensed, low-dimensional language feature is more efficient compared with learning from a redundant, high-dimensional image feature. By training on HyperSim and Virtual KITTI, we achieve state-of-the-art zero-shot performance and a faster convergence speed, compared with other diffusion-based depth estimators, across NYUv2, KITTI, ETH3D, and ScanNet.
Differentiable Gaussian Representation for Incomplete CT Reconstruction
Nov 07, 2024Incomplete Computed Tomography (CT) benefits patients by reducing radiation exposure. However, reconstructing high-fidelity images from limited views or angles remains challenging due to the ill-posed nature of the problem. Deep Learning Reconstruction (DLR) methods have shown promise in enhancing image quality, but the paradox between training data diversity and high generalization ability remains unsolved. In this paper, we propose a novel Gaussian Representation for Incomplete CT Reconstruction (GRCT) without the usage of any neural networks or full-dose CT data. Specifically, we model the 3D volume as a set of learnable Gaussians, which are optimized directly from the incomplete sinogram. Our method can be applied to multiple views and angles without changing the architecture. Additionally, we propose a differentiable Fast CT Reconstruction method for efficient clinical usage. Extensive experiments on multiple datasets and settings demonstrate significant improvements in reconstruction quality metrics and high efficiency. We plan to release our code as open-source.
Differentiation Through Black-Box Quadratic Programming Solvers
Oct 10, 2024



In recent years, many deep learning approaches have incorporated layers that solve optimization problems (e.g., linear, quadratic, and semidefinite programs). Integrating these optimization problems as differentiable layers requires computing the derivatives of the optimization problem's solution with respect to its objective and constraints. This has so far prevented the use of state-of-the-art black-box numerical solvers within neural networks, as they lack a differentiable interface. To address this issue for one of the most common convex optimization problems -- quadratic programming (QP) -- we introduce dQP, a modular framework that enables plug-and-play differentiation for any QP solver, allowing seamless integration into neural networks and bi-level optimization tasks. Our solution is based on the core theoretical insight that knowledge of the active constraint set at the QP optimum allows for explicit differentiation. This insight reveals a unique relationship between the computation of the solution and its derivative, enabling efficient differentiation of any solver, that only requires the primal solution. Our implementation, which will be made publicly available, interfaces with an existing framework that supports over 15 state-of-the-art QP solvers, providing each with a fully differentiable backbone for immediate use as a differentiable layer in learning setups. To demonstrate the scalability and effectiveness of dQP, we evaluate it on a large benchmark dataset of QPs with varying structures. We compare dQP with existing differentiable QP methods, demonstrating its advantages across a range of problems, from challenging small and dense problems to large-scale sparse ones, including a novel bi-level geometry optimization problem.
RSA: Resolving Scale Ambiguities in Monocular Depth Estimators through Language Descriptions
Oct 03, 2024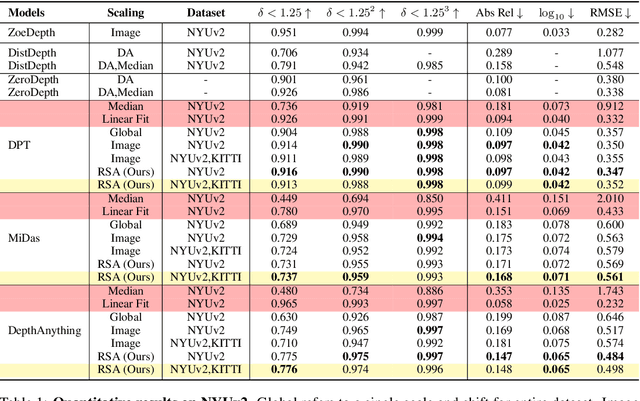
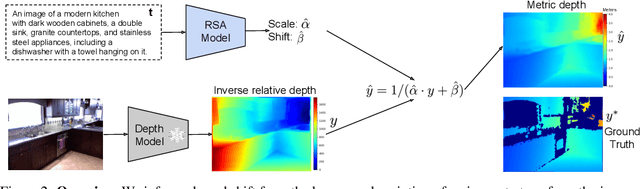
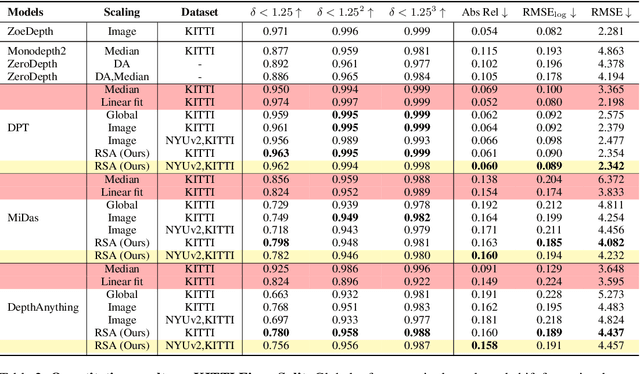

We propose a method for metric-scale monocular depth estimation. Inferring depth from a single image is an ill-posed problem due to the loss of scale from perspective projection during the image formation process. Any scale chosen is a bias, typically stemming from training on a dataset; hence, existing works have instead opted to use relative (normalized, inverse) depth. Our goal is to recover metric-scaled depth maps through a linear transformation. The crux of our method lies in the observation that certain objects (e.g., cars, trees, street signs) are typically found or associated with certain types of scenes (e.g., outdoor). We explore whether language descriptions can be used to transform relative depth predictions to those in metric scale. Our method, RSA, takes as input a text caption describing objects present in an image and outputs the parameters of a linear transformation which can be applied globally to a relative depth map to yield metric-scaled depth predictions. We demonstrate our method on recent general-purpose monocular depth models on indoors (NYUv2) and outdoors (KITTI). When trained on multiple datasets, RSA can serve as a general alignment module in zero-shot settings. Our method improves over common practices in aligning relative to metric depth and results in predictions that are comparable to an upper bound of fitting relative depth to ground truth via a linear transformation.
TextToucher: Fine-Grained Text-to-Touch Generation
Sep 09, 2024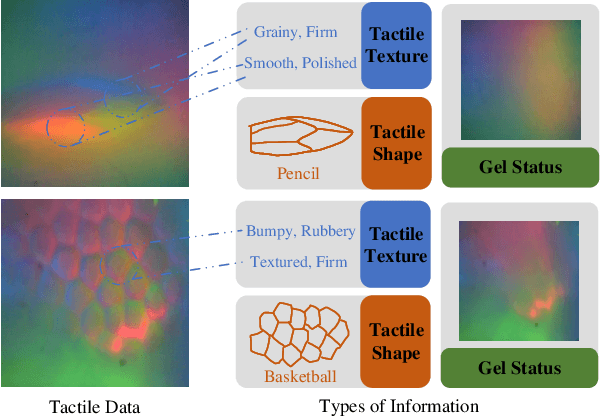

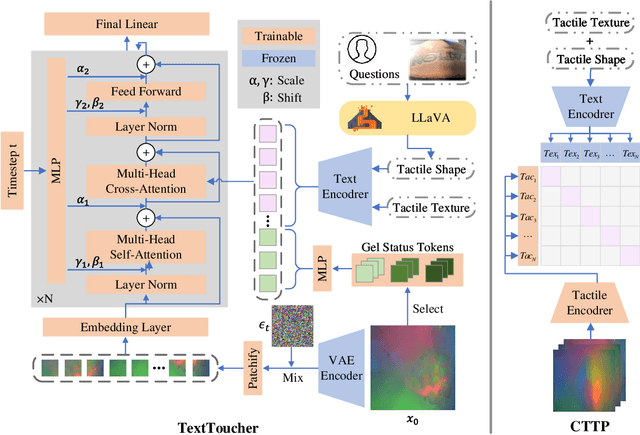
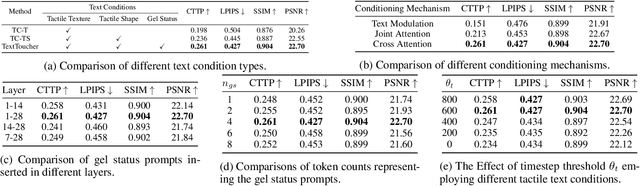
Tactile sensation plays a crucial role in the development of multi-modal large models and embodied intelligence. To collect tactile data with minimal cost as possible, a series of studies have attempted to generate tactile images by vision-to-touch image translation. However, compared to text modality, visual modality-driven tactile generation cannot accurately depict human tactile sensation. In this work, we analyze the characteristics of tactile images in detail from two granularities: object-level (tactile texture, tactile shape), and sensor-level (gel status). We model these granularities of information through text descriptions and propose a fine-grained Text-to-Touch generation method (TextToucher) to generate high-quality tactile samples. Specifically, we introduce a multimodal large language model to build the text sentences about object-level tactile information and employ a set of learnable text prompts to represent the sensor-level tactile information. To better guide the tactile generation process with the built text information, we fuse the dual grains of text information and explore various dual-grain text conditioning methods within the diffusion transformer architecture. Furthermore, we propose a Contrastive Text-Touch Pre-training (CTTP) metric to precisely evaluate the quality of text-driven generated tactile data. Extensive experiments demonstrate the superiority of our TextToucher method. The source codes will be available at \url{https://github.com/TtuHamg/TextToucher}.
NeuroBind: Towards Unified Multimodal Representations for Neural Signals
Jul 19, 2024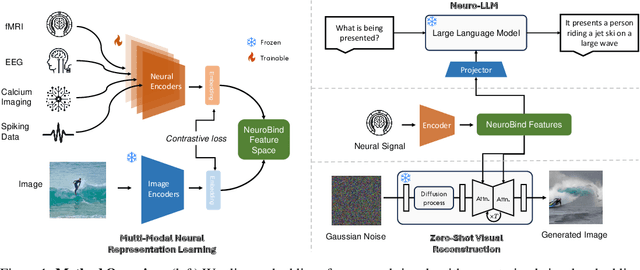
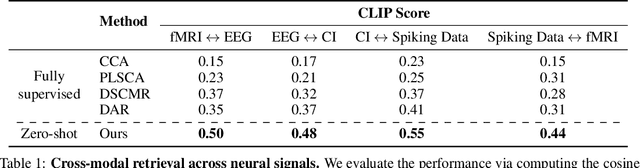

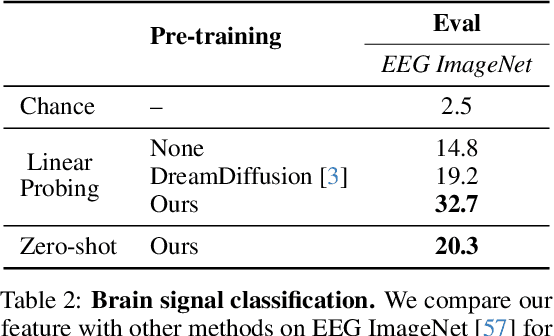
Understanding neural activity and information representation is crucial for advancing knowledge of brain function and cognition. Neural activity, measured through techniques like electrophysiology and neuroimaging, reflects various aspects of information processing. Recent advances in deep neural networks offer new approaches to analyzing these signals using pre-trained models. However, challenges arise due to discrepancies between different neural signal modalities and the limited scale of high-quality neural data. To address these challenges, we present NeuroBind, a general representation that unifies multiple brain signal types, including EEG, fMRI, calcium imaging, and spiking data. To achieve this, we align neural signals in these image-paired neural datasets to pre-trained vision-language embeddings. Neurobind is the first model that studies different neural modalities interconnectedly and is able to leverage high-resource modality models for various neuroscience tasks. We also showed that by combining information from different neural signal modalities, NeuroBind enhances downstream performance, demonstrating the effectiveness of the complementary strengths of different neural modalities. As a result, we can leverage multiple types of neural signals mapped to the same space to improve downstream tasks, and demonstrate the complementary strengths of different neural modalities. This approach holds significant potential for advancing neuroscience research, improving AI systems, and developing neuroprosthetics and brain-computer interfaces.
Towards Expressive Zero-Shot Speech Synthesis with Hierarchical Prosody Modeling
Jun 11, 2024



Recent research in zero-shot speech synthesis has made significant progress in speaker similarity. However, current efforts focus on timbre generalization rather than prosody modeling, which results in limited naturalness and expressiveness. To address this, we introduce a novel speech synthesis model trained on large-scale datasets, including both timbre and hierarchical prosody modeling. As timbre is a global attribute closely linked to expressiveness, we adopt a global vector to model speaker timbre while guiding prosody modeling. Besides, given that prosody contains both global consistency and local variations, we introduce a diffusion model as the pitch predictor and employ a prosody adaptor to model prosody hierarchically, further enhancing the prosody quality of the synthesized speech. Experimental results show that our model not only maintains comparable timbre quality to the baseline but also exhibits better naturalness and expressiveness.
Tactile-Augmented Radiance Fields
May 07, 2024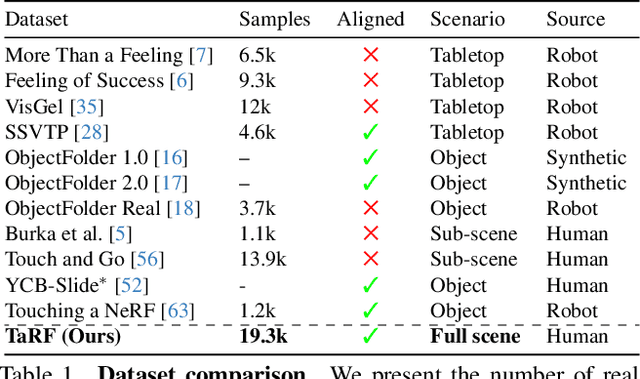

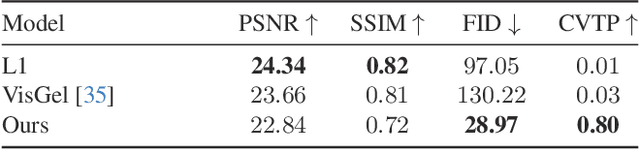

We present a scene representation, which we call a tactile-augmented radiance field (TaRF), that brings vision and touch into a shared 3D space. This representation can be used to estimate the visual and tactile signals for a given 3D position within a scene. We capture a scene's TaRF from a collection of photos and sparsely sampled touch probes. Our approach makes use of two insights: (i) common vision-based touch sensors are built on ordinary cameras and thus can be registered to images using methods from multi-view geometry, and (ii) visually and structurally similar regions of a scene share the same tactile features. We use these insights to register touch signals to a captured visual scene, and to train a conditional diffusion model that, provided with an RGB-D image rendered from a neural radiance field, generates its corresponding tactile signal. To evaluate our approach, we collect a dataset of TaRFs. This dataset contains more touch samples than previous real-world datasets, and it provides spatially aligned visual signals for each captured touch signal. We demonstrate the accuracy of our cross-modal generative model and the utility of the captured visual-tactile data on several downstream tasks. Project page: https://dou-yiming.github.io/TaRF