 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMORE: Multi-Organ Medical Image REconstruction Dataset
Oct 30, 2025CT reconstruction provides radiologists with images for diagnosis and treatment, yet current deep learning methods are typically limited to specific anatomies and datasets, hindering generalization ability to unseen anatomies and lesions. To address this, we introduce the Multi-Organ medical image REconstruction (MORE) dataset, comprising CT scans across 9 diverse anatomies with 15 lesion types. This dataset serves two key purposes: (1) enabling robust training of deep learning models on extensive, heterogeneous data, and (2) facilitating rigorous evaluation of model generalization for CT reconstruction. We further establish a strong baseline solution that outperforms prior approaches under these challenging conditions. Our results demonstrate that: (1) a comprehensive dataset helps improve the generalization capability of models, and (2) optimization-based methods offer enhanced robustness for unseen anatomies. The MORE dataset is freely accessible under CC-BY-NC 4.0 at our project page https://more-med.github.io/
Generating Negative Samples for Multi-Modal Recommendation
Jan 25, 2025Multi-modal recommender systems (MMRS) have gained significant attention due to their ability to leverage information from various modalities to enhance recommendation quality. However, existing negative sampling techniques often struggle to effectively utilize the multi-modal data, leading to suboptimal performance. In this paper, we identify two key challenges in negative sampling for MMRS: (1) producing cohesive negative samples contrasting with positive samples and (2) maintaining a balanced influence across different modalities. To address these challenges, we propose NegGen, a novel framework that utilizes multi-modal large language models (MLLMs) to generate balanced and contrastive negative samples. We design three different prompt templates to enable NegGen to analyze and manipulate item attributes across multiple modalities, and then generate negative samples that introduce better supervision signals and ensure modality balance. Furthermore, NegGen employs a causal learning module to disentangle the effect of intervened key features and irrelevant item attributes, enabling fine-grained learning of user preferences. Extensive experiments on real-world datasets demonstrate the superior performance of NegGen compared to state-of-the-art methods in both negative sampling and multi-modal recommendation.
Topology-Aware Popularity Debiasing via Simplicial Complexes
Nov 21, 2024Recommender systems (RS) play a critical role in delivering personalized content across various online platforms, leveraging collaborative filtering (CF) as a key technique to generate recommendations based on users' historical interaction data. Recent advancements in CF have been driven by the adoption of Graph Neural Networks (GNNs), which model user-item interactions as bipartite graphs, enabling the capture of high-order collaborative signals. Despite their success, GNN-based methods face significant challenges due to the inherent popularity bias in the user-item interaction graph's topology, leading to skewed recommendations that favor popular items over less-known ones. To address this challenge, we propose a novel topology-aware popularity debiasing framework, Test-time Simplicial Propagation (TSP), which incorporates simplicial complexes (SCs) to enhance the expressiveness of GNNs. Unlike traditional methods that focus on pairwise relationships, our approach captures multi-order relationships through SCs, providing a more comprehensive representation of user-item interactions. By enriching the neighborhoods of tail items and leveraging SCs for feature smoothing, TSP enables the propagation of multi-order collaborative signals and effectively mitigates biased propagation. Our TSP module is designed as a plug-and-play solution, allowing for seamless integration into pre-trained GNN-based models without the need for fine-tuning additional parameters. Extensive experiments on five real-world datasets demonstrate the superior performance of our method, particularly in long-tail recommendation tasks. Visualization results further confirm that TSP produces more uniform distributions of item representations, leading to fairer and more accurate recommendations.
Differentiable Gaussian Representation for Incomplete CT Reconstruction
Nov 07, 2024Incomplete Computed Tomography (CT) benefits patients by reducing radiation exposure. However, reconstructing high-fidelity images from limited views or angles remains challenging due to the ill-posed nature of the problem. Deep Learning Reconstruction (DLR) methods have shown promise in enhancing image quality, but the paradox between training data diversity and high generalization ability remains unsolved. In this paper, we propose a novel Gaussian Representation for Incomplete CT Reconstruction (GRCT) without the usage of any neural networks or full-dose CT data. Specifically, we model the 3D volume as a set of learnable Gaussians, which are optimized directly from the incomplete sinogram. Our method can be applied to multiple views and angles without changing the architecture. Additionally, we propose a differentiable Fast CT Reconstruction method for efficient clinical usage. Extensive experiments on multiple datasets and settings demonstrate significant improvements in reconstruction quality metrics and high efficiency. We plan to release our code as open-source.
NT-LLM: A Novel Node Tokenizer for Integrating Graph Structure into Large Language Models
Oct 14, 2024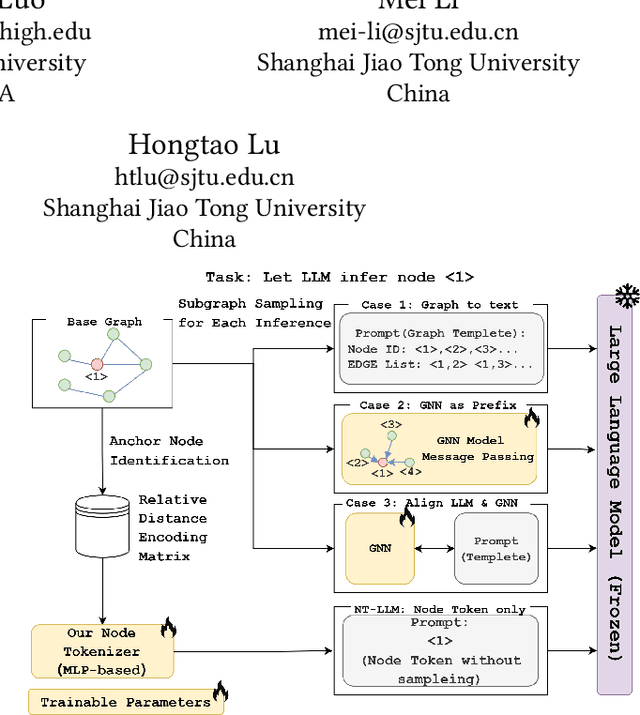

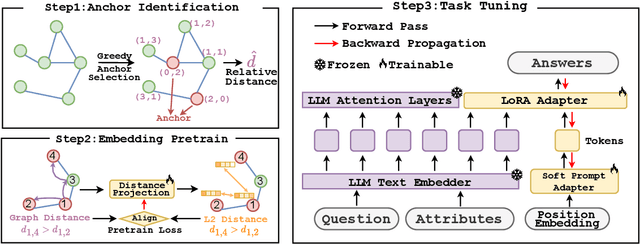

Graphs are a fundamental data structure for representing relationships in real-world scenarios. With the success of Large Language Models (LLMs) across various natural language processing (NLP) tasks, there has been growing interest in integrating LLMs for graph learning. However, applying LLMs to graph-related tasks poses significant challenges, as these models are not inherently designed to capture the complex structural information present in graphs. Existing approaches address this challenge through two strategies: the chain of tasks approach, which uses Graph Neural Networks (GNNs) to encode the graph structure so that LLMs are relieved from understanding spatial positions; and Graph-to-Text Conversion, which translates graph structures into semantic text representations that LLMs can process. Despite their progress, these methods often struggle to fully preserve the topological information of graphs or require extensive computational resources, limiting their practical applicability. In this work, we introduce Node Tokenizer for Large Language Models (NT-LLM), a novel framework that efficiently encodes graph structures by selecting key nodes as anchors and representing each node based on its relative distance to these anchors. This position-anchored encoding effectively captures the graph topology, enabling enhanced reasoning capabilities in LLMs over graph data. Additionally, we implement a task-specific tuning procedure to further improve structural understanding within LLMs. Through extensive empirical evaluations, NT-LLM demonstrates significant performance improvements across a variety of graph-related tasks.
Towards Personalized Federated Multi-scenario Multi-task Recommendation
Jun 27, 2024



In modern recommender system applications, such as e-commerce, predicting multiple targets like click-through rate (CTR) and post-view click-through \& conversion rate (CTCVR) is common. Multi-task recommender systems are gaining traction in research and practical use. Existing multi-task recommender systems tackle diverse business scenarios, merging and modeling these scenarios unlocks shared knowledge to boost overall performance. As new and more complex real-world recommendation scenarios have emerged, data privacy issues make it difficult to train a single global multi-task recommendation model that processes multiple separate scenarios. In this paper, we propose a novel framework for personalized federated multi-scenario multi-task recommendation, called PF-MSMTrec. We assign each scenario to a dedicated client, with each client utilizing the Mixture-of-Experts (MMoE) structure. Our proposed method aims to tackle the unique challenge posed by multiple optimization conflicts in this setting. We introduce a bottom-up joint learning mechanism. Firstly, we design a parameter template to decouple the parameters of the expert network. Thus, scenario parameters are shared knowledge for federated parameter aggregation, while task-specific parameters are personalized local parameters. Secondly, we conduct personalized federated learning for the parameters of each expert network through a federated communication round, utilizing three modules: federated batch normalization, conflict coordination, and personalized aggregation. Finally, we perform another round of personalized federated parameter aggregation on the task tower network to obtain the prediction results for multiple tasks. We conduct extensive experiments on two public datasets, and the results demonstrate that our proposed method surpasses state-of-the-art methods.