 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNILC: Discovering New Intents with LLM-assisted Clustering
Nov 08, 2025New intent discovery (NID) seeks to recognize both new and known intents from unlabeled user utterances, which finds prevalent use in practical dialogue systems. Existing works towards NID mainly adopt a cascaded architecture, wherein the first stage focuses on encoding the utterances into informative text embeddings beforehand, while the latter is to group similar embeddings into clusters (i.e., intents), typically by K-Means. However, such a cascaded pipeline fails to leverage the feedback from both steps for mutual refinement, and, meanwhile, the embedding-only clustering overlooks nuanced textual semantics, leading to suboptimal performance. To bridge this gap, this paper proposes NILC, a novel clustering framework specially catered for effective NID. Particularly, NILC follows an iterative workflow, in which clustering assignments are judiciously updated by carefully refining cluster centroids and text embeddings of uncertain utterances with the aid of large language models (LLMs). Specifically, NILC first taps into LLMs to create additional semantic centroids for clusters, thereby enriching the contextual semantics of the Euclidean centroids of embeddings. Moreover, LLMs are then harnessed to augment hard samples (ambiguous or terse utterances) identified from clusters via rewriting for subsequent cluster correction. Further, we inject supervision signals through non-trivial techniques seeding and soft must links for more accurate NID in the semi-supervised setting. Extensive experiments comparing NILC against multiple recent baselines under both unsupervised and semi-supervised settings showcase that NILC can achieve significant performance improvements over six benchmark datasets of diverse domains consistently.
Community-Aware Social Community Recommendation
Aug 07, 2025Social recommendation, which seeks to leverage social ties among users to alleviate the sparsity issue of user-item interactions, has emerged as a popular technique for elevating personalized services in recommender systems. Despite being effective, existing social recommendation models are mainly devised for recommending regular items such as blogs, images, and products, and largely fail for community recommendations due to overlooking the unique characteristics of communities. Distinctly, communities are constituted by individuals, who present high dynamicity and relate to rich structural patterns in social networks. To our knowledge, limited research has been devoted to comprehensively exploiting this information for recommending communities. To bridge this gap, this paper presents CASO, a novel and effective model specially designed for social community recommendation. Under the hood, CASO harnesses three carefully-crafted encoders for user embedding, wherein two of them extract community-related global and local structures from the social network via social modularity maximization and social closeness aggregation, while the third one captures user preferences using collaborative filtering with observed user-community affiliations. To further eliminate feature redundancy therein, we introduce a mutual exclusion between social and collaborative signals. Finally, CASO includes a community detection loss in the model optimization, thereby producing community-aware embeddings for communities. Our extensive experiments evaluating CASO against nine strong baselines on six real-world social networks demonstrate its consistent and remarkable superiority over the state of the art in terms of community recommendation performance.
FROG: Effective Friend Recommendation in Online Games via Modality-aware User Preferences
Apr 13, 2025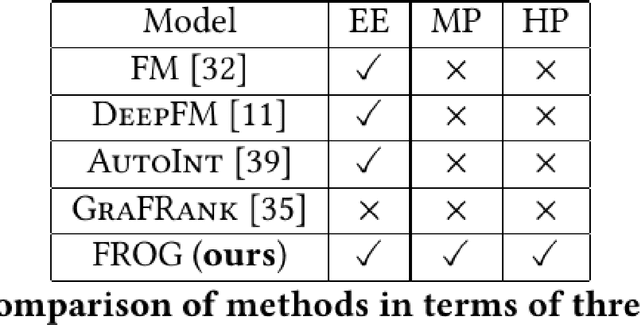
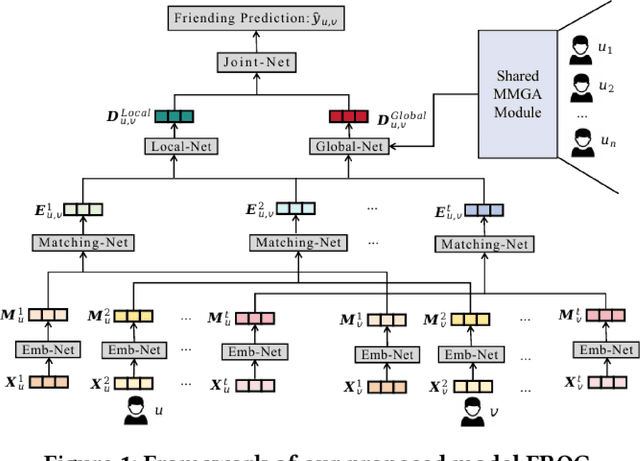

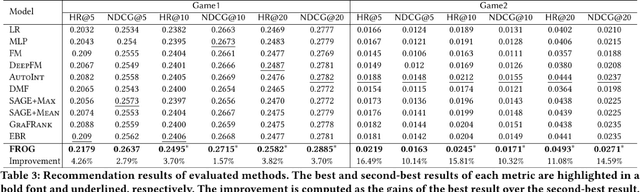
Due to the convenience of mobile devices, the online games have become an important part for user entertainments in reality, creating a demand for friend recommendation in online games. However, none of existing approaches can effectively incorporate the multi-modal user features (\emph{e.g.}, images and texts) with the structural information in the friendship graph, due to the following limitations: (1) some of them ignore the high-order structural proximity between users, (2) some fail to learn the pairwise relevance between users at modality-specific level, and (3) some cannot capture both the local and global user preferences on different modalities. By addressing these issues, in this paper, we propose an end-to-end model \textsc{FROG} that better models the user preferences on potential friends. Comprehensive experiments on both offline evaluation and online deployment at \kw{Tencent} have demonstrated the superiority of \textsc{FROG} over existing approaches.
NT-LLM: A Novel Node Tokenizer for Integrating Graph Structure into Large Language Models
Oct 14, 2024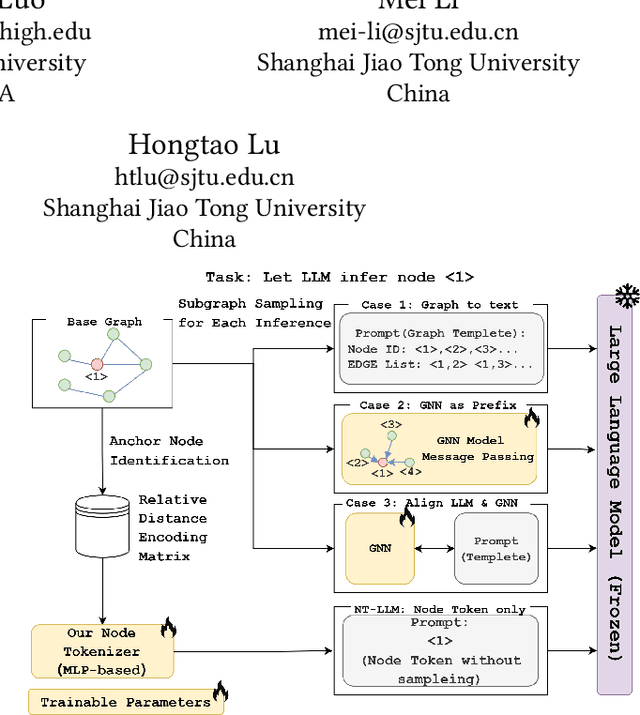

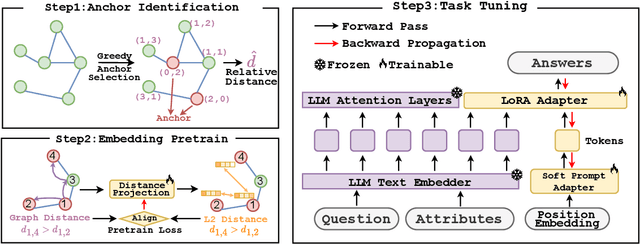

Graphs are a fundamental data structure for representing relationships in real-world scenarios. With the success of Large Language Models (LLMs) across various natural language processing (NLP) tasks, there has been growing interest in integrating LLMs for graph learning. However, applying LLMs to graph-related tasks poses significant challenges, as these models are not inherently designed to capture the complex structural information present in graphs. Existing approaches address this challenge through two strategies: the chain of tasks approach, which uses Graph Neural Networks (GNNs) to encode the graph structure so that LLMs are relieved from understanding spatial positions; and Graph-to-Text Conversion, which translates graph structures into semantic text representations that LLMs can process. Despite their progress, these methods often struggle to fully preserve the topological information of graphs or require extensive computational resources, limiting their practical applicability. In this work, we introduce Node Tokenizer for Large Language Models (NT-LLM), a novel framework that efficiently encodes graph structures by selecting key nodes as anchors and representing each node based on its relative distance to these anchors. This position-anchored encoding effectively captures the graph topology, enabling enhanced reasoning capabilities in LLMs over graph data. Additionally, we implement a task-specific tuning procedure to further improve structural understanding within LLMs. Through extensive empirical evaluations, NT-LLM demonstrates significant performance improvements across a variety of graph-related tasks.
Large-Scale Network Embedding in Apache Spark
Jun 20, 2021
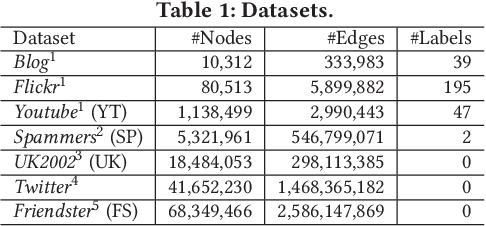
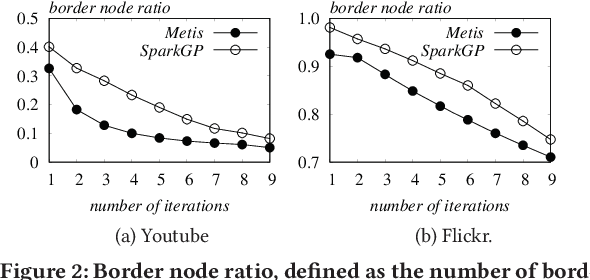
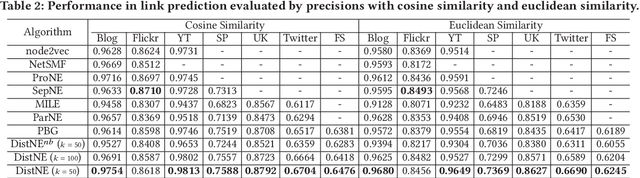
Network embedding has been widely used in social recommendation and network analysis, such as recommendation systems and anomaly detection with graphs. However, most of previous approaches cannot handle large graphs efficiently, due to that (i) computation on graphs is often costly and (ii) the size of graph or the intermediate results of vectors could be prohibitively large, rendering it difficult to be processed on a single machine. In this paper, we propose an efficient and effective distributed algorithm for network embedding on large graphs using Apache Spark, which recursively partitions a graph into several small-sized subgraphs to capture the internal and external structural information of nodes, and then computes the network embedding for each subgraph in parallel. Finally, by aggregating the outputs on all subgraphs, we obtain the embeddings of nodes in a linear cost. After that, we demonstrate in various experiments that our proposed approach is able to handle graphs with billions of edges within a few hours and is at least 4 times faster than the state-of-the-art approaches. Besides, it achieves up to $4.25\%$ and $4.27\%$ improvements on link prediction and node classification tasks respectively. In the end, we deploy the proposed algorithms in two online games of Tencent with the applications of friend recommendation and item recommendation, which improve the competitors by up to $91.11\%$ in running time and up to $12.80\%$ in the corresponding evaluation metrics.
Effective and Efficient Network Embedding Initialization via Graph Partitioning
Aug 28, 2019
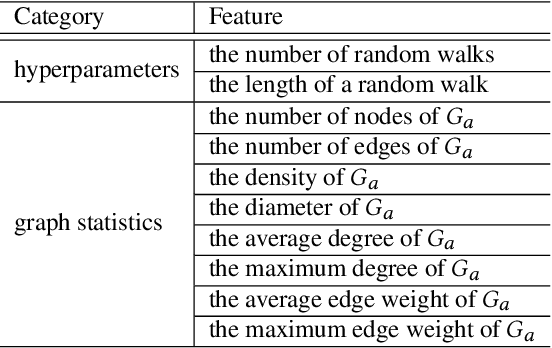
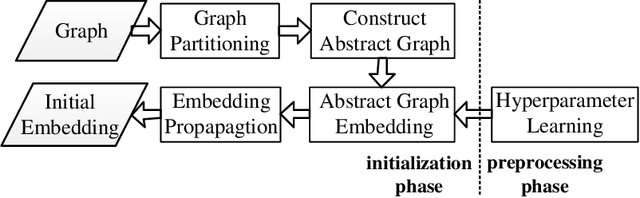
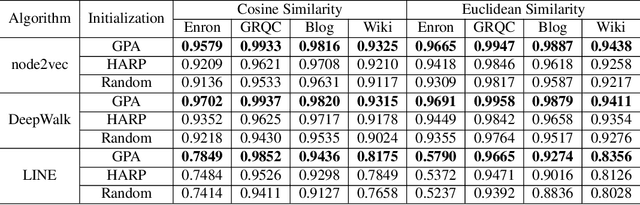
Network embedding has been intensively studied in the literature and widely used in various applications, such as link prediction and node classification. While previous work focus on the design of new algorithms or are tailored for various problem settings, the discussion of initialization strategies in the learning process is often missed. In this work, we address this important issue of initialization for network embedding that could dramatically improve the performance of the algorithms on both effectiveness and efficiency. Specifically, we first exploit the graph partition technique that divides the graph into several disjoint subsets, and then construct an abstract graph based on the partitions. We obtain the initialization of the embedding for each node in the graph by computing the network embedding on the abstract graph, which is much smaller than the input graph, and then propagating the embedding among the nodes in the input graph. With extensive experiments on various datasets, we demonstrate that our initialization technique significantly improves the performance of the state-of-the-art algorithms on the evaluations of link prediction and node classification by up to 7.76% and 8.74% respectively. Besides, we show that the technique of initialization reduces the running time of the state-of-the-arts by at least 20%.