 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Network Embedding in Apache Spark
Paper and Code
Jun 20, 2021
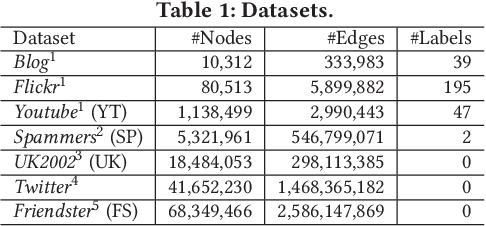
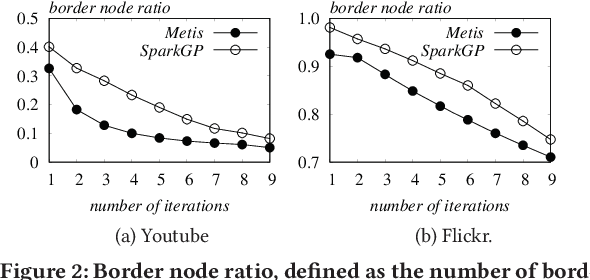
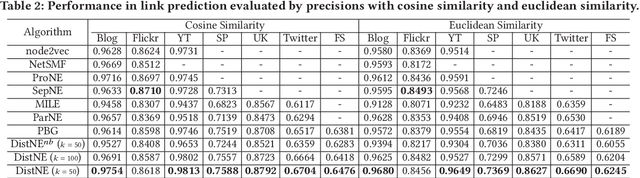
Network embedding has been widely used in social recommendation and network analysis, such as recommendation systems and anomaly detection with graphs. However, most of previous approaches cannot handle large graphs efficiently, due to that (i) computation on graphs is often costly and (ii) the size of graph or the intermediate results of vectors could be prohibitively large, rendering it difficult to be processed on a single machine. In this paper, we propose an efficient and effective distributed algorithm for network embedding on large graphs using Apache Spark, which recursively partitions a graph into several small-sized subgraphs to capture the internal and external structural information of nodes, and then computes the network embedding for each subgraph in parallel. Finally, by aggregating the outputs on all subgraphs, we obtain the embeddings of nodes in a linear cost. After that, we demonstrate in various experiments that our proposed approach is able to handle graphs with billions of edges within a few hours and is at least 4 times faster than the state-of-the-art approaches. Besides, it achieves up to $4.25\%$ and $4.27\%$ improvements on link prediction and node classification tasks respectively. In the end, we deploy the proposed algorithms in two online games of Tencent with the applications of friend recommendation and item recommendation, which improve the competitors by up to $91.11\%$ in running time and up to $12.80\%$ in the corresponding evaluation metrics.