 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetricGrids: Arbitrary Nonlinear Approximation with Elementary Metric Grids based Implicit Neural Representation
Mar 13, 2025
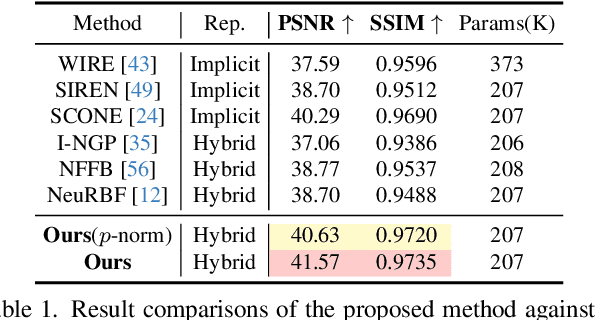

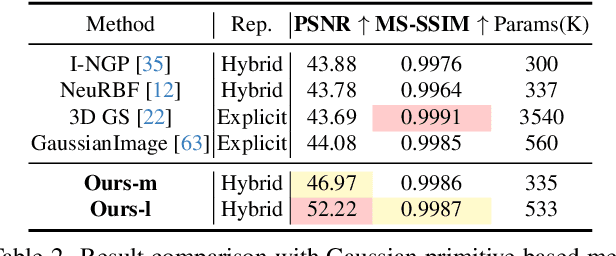
This paper presents MetricGrids, a novel grid-based neural representation that combines elementary metric grids in various metric spaces to approximate complex nonlinear signals. While grid-based representations are widely adopted for their efficiency and scalability, the existing feature grids with linear indexing for continuous-space points can only provide degenerate linear latent space representations, and such representations cannot be adequately compensated to represent complex nonlinear signals by the following compact decoder. To address this problem while keeping the simplicity of a regular grid structure, our approach builds upon the standard grid-based paradigm by constructing multiple elementary metric grids as high-order terms to approximate complex nonlinearities, following the Taylor expansion principle. Furthermore, we enhance model compactness with hash encoding based on different sparsities of the grids to prevent detrimental hash collisions, and a high-order extrapolation decoder to reduce explicit grid storage requirements. experimental results on both 2D and 3D reconstructions demonstrate the superior fitting and rendering accuracy of the proposed method across diverse signal types, validating its robustness and generalizability. Code is available at https://github.com/wangshu31/MetricGrids}{https://github.com/wangshu31/MetricGrids.
Approximately Invertible Neural Network for Learned Image Compression
Aug 30, 2024



Learned image compression have attracted considerable interests in recent years. It typically comprises an analysis transform, a synthesis transform, quantization and an entropy coding model. The analysis transform and synthesis transform are used to encode an image to latent feature and decode the quantized feature to reconstruct the image, and can be regarded as coupled transforms. However, the analysis transform and synthesis transform are designed independently in the existing methods, making them unreliable in high-quality image compression. Inspired by the invertible neural networks in generative modeling, invertible modules are used to construct the coupled analysis and synthesis transforms. Considering the noise introduced in the feature quantization invalidates the invertible process, this paper proposes an Approximately Invertible Neural Network (A-INN) framework for learned image compression. It formulates the rate-distortion optimization in lossy image compression when using INN with quantization, which differentiates from using INN for generative modelling. Generally speaking, A-INN can be used as the theoretical foundation for any INN based lossy compression method. Based on this formulation, A-INN with a progressive denoising module (PDM) is developed to effectively reduce the quantization noise in the decoding. Moreover, a Cascaded Feature Recovery Module (CFRM) is designed to learn high-dimensional feature recovery from low-dimensional ones to further reduce the noise in feature channel compression. In addition, a Frequency-enhanced Decomposition and Synthesis Module (FDSM) is developed by explicitly enhancing the high-frequency components in an image to address the loss of high-frequency information inherent in neural network based image compression. Extensive experiments demonstrate that the proposed A-INN outperforms the existing learned image compression methods.
Towards Personalized Federated Multi-scenario Multi-task Recommendation
Jun 27, 2024



In modern recommender system applications, such as e-commerce, predicting multiple targets like click-through rate (CTR) and post-view click-through \& conversion rate (CTCVR) is common. Multi-task recommender systems are gaining traction in research and practical use. Existing multi-task recommender systems tackle diverse business scenarios, merging and modeling these scenarios unlocks shared knowledge to boost overall performance. As new and more complex real-world recommendation scenarios have emerged, data privacy issues make it difficult to train a single global multi-task recommendation model that processes multiple separate scenarios. In this paper, we propose a novel framework for personalized federated multi-scenario multi-task recommendation, called PF-MSMTrec. We assign each scenario to a dedicated client, with each client utilizing the Mixture-of-Experts (MMoE) structure. Our proposed method aims to tackle the unique challenge posed by multiple optimization conflicts in this setting. We introduce a bottom-up joint learning mechanism. Firstly, we design a parameter template to decouple the parameters of the expert network. Thus, scenario parameters are shared knowledge for federated parameter aggregation, while task-specific parameters are personalized local parameters. Secondly, we conduct personalized federated learning for the parameters of each expert network through a federated communication round, utilizing three modules: federated batch normalization, conflict coordination, and personalized aggregation. Finally, we perform another round of personalized federated parameter aggregation on the task tower network to obtain the prediction results for multiple tasks. We conduct extensive experiments on two public datasets, and the results demonstrate that our proposed method surpasses state-of-the-art methods.
UNIDEAL: Curriculum Knowledge Distillation Federated Learning
Sep 16, 2023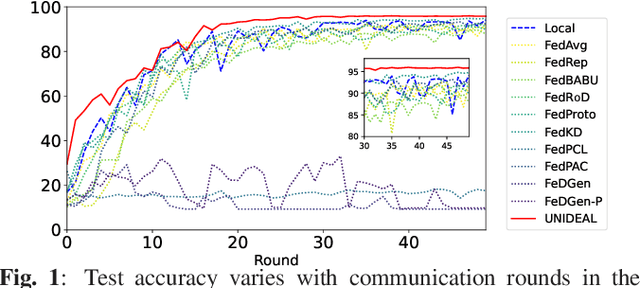
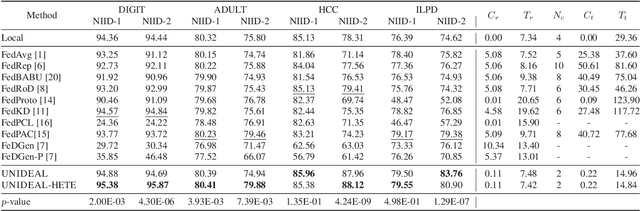

Federated Learning (FL) has emerged as a promising approach to enable collaborative learning among multiple clients while preserving data privacy. However, cross-domain FL tasks, where clients possess data from different domains or distributions, remain a challenging problem due to the inherent heterogeneity. In this paper, we present UNIDEAL, a novel FL algorithm specifically designed to tackle the challenges of cross-domain scenarios and heterogeneous model architectures. The proposed method introduces Adjustable Teacher-Student Mutual Evaluation Curriculum Learning, which significantly enhances the effectiveness of knowledge distillation in FL settings. We conduct extensive experiments on various datasets, comparing UNIDEAL with state-of-the-art baselines. Our results demonstrate that UNIDEAL achieves superior performance in terms of both model accuracy and communication efficiency. Additionally, we provide a convergence analysis of the algorithm, showing a convergence rate of O(1/T) under non-convex conditions.
Completely Heterogeneous Federated Learning
Oct 28, 2022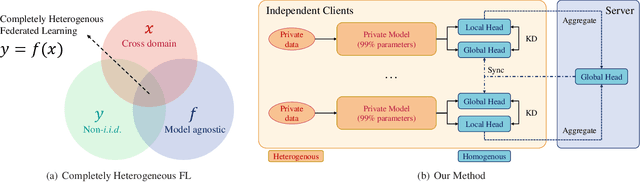
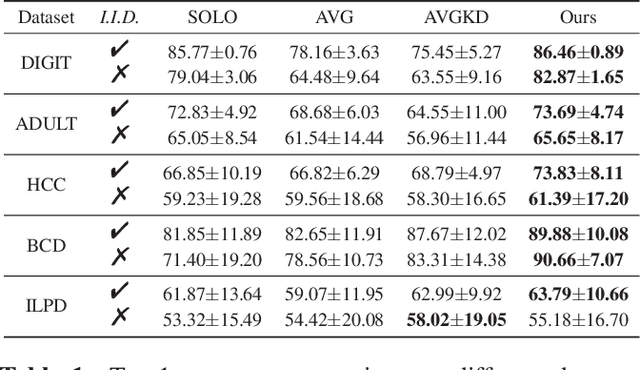

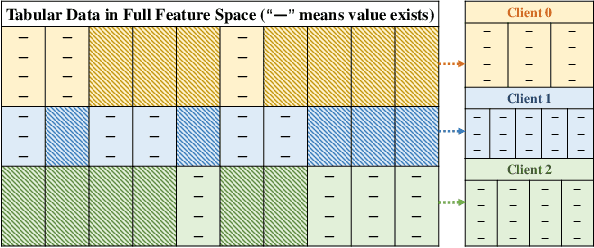
Federated learning (FL) faces three major difficulties: cross-domain, heterogeneous models, and non-i.i.d. labels scenarios. Existing FL methods fail to handle the above three constraints at the same time, and the level of privacy protection needs to be lowered (e.g., the model architecture and data category distribution can be shared). In this work, we propose the challenging "completely heterogeneous" scenario in FL, which refers to that each client will not expose any private information including feature space, model architecture, and label distribution. We then devise an FL framework based on parameter decoupling and data-free knowledge distillation to solve the problem. Experiments show that our proposed method achieves high performance in completely heterogeneous scenarios where other approaches fail.