 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetricGrids: Arbitrary Nonlinear Approximation with Elementary Metric Grids based Implicit Neural Representation
Mar 13, 2025
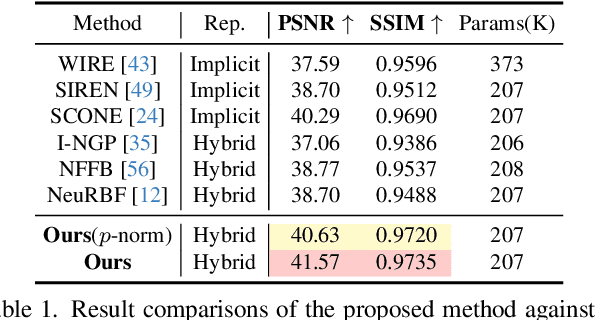

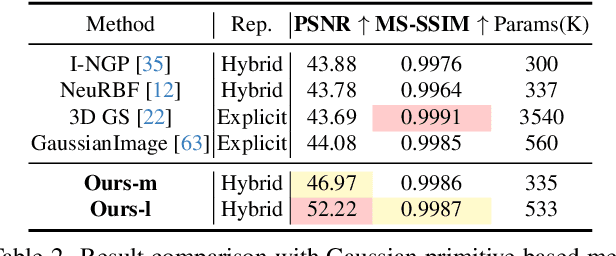
This paper presents MetricGrids, a novel grid-based neural representation that combines elementary metric grids in various metric spaces to approximate complex nonlinear signals. While grid-based representations are widely adopted for their efficiency and scalability, the existing feature grids with linear indexing for continuous-space points can only provide degenerate linear latent space representations, and such representations cannot be adequately compensated to represent complex nonlinear signals by the following compact decoder. To address this problem while keeping the simplicity of a regular grid structure, our approach builds upon the standard grid-based paradigm by constructing multiple elementary metric grids as high-order terms to approximate complex nonlinearities, following the Taylor expansion principle. Furthermore, we enhance model compactness with hash encoding based on different sparsities of the grids to prevent detrimental hash collisions, and a high-order extrapolation decoder to reduce explicit grid storage requirements. experimental results on both 2D and 3D reconstructions demonstrate the superior fitting and rendering accuracy of the proposed method across diverse signal types, validating its robustness and generalizability. Code is available at https://github.com/wangshu31/MetricGrids}{https://github.com/wangshu31/MetricGrids.
Approximately Invertible Neural Network for Learned Image Compression
Aug 30, 2024



Learned image compression have attracted considerable interests in recent years. It typically comprises an analysis transform, a synthesis transform, quantization and an entropy coding model. The analysis transform and synthesis transform are used to encode an image to latent feature and decode the quantized feature to reconstruct the image, and can be regarded as coupled transforms. However, the analysis transform and synthesis transform are designed independently in the existing methods, making them unreliable in high-quality image compression. Inspired by the invertible neural networks in generative modeling, invertible modules are used to construct the coupled analysis and synthesis transforms. Considering the noise introduced in the feature quantization invalidates the invertible process, this paper proposes an Approximately Invertible Neural Network (A-INN) framework for learned image compression. It formulates the rate-distortion optimization in lossy image compression when using INN with quantization, which differentiates from using INN for generative modelling. Generally speaking, A-INN can be used as the theoretical foundation for any INN based lossy compression method. Based on this formulation, A-INN with a progressive denoising module (PDM) is developed to effectively reduce the quantization noise in the decoding. Moreover, a Cascaded Feature Recovery Module (CFRM) is designed to learn high-dimensional feature recovery from low-dimensional ones to further reduce the noise in feature channel compression. In addition, a Frequency-enhanced Decomposition and Synthesis Module (FDSM) is developed by explicitly enhancing the high-frequency components in an image to address the loss of high-frequency information inherent in neural network based image compression. Extensive experiments demonstrate that the proposed A-INN outperforms the existing learned image compression methods.
Unsupervised Spatial-Temporal Feature Enrichment and Fidelity Preservation Network for Skeleton based Action Recognition
Jan 25, 2024Unsupervised skeleton based action recognition has achieved remarkable progress recently. Existing unsupervised learning methods suffer from severe overfitting problem, and thus small networks are used, significantly reducing the representation capability. To address this problem, the overfitting mechanism behind the unsupervised learning for skeleton based action recognition is first investigated. It is observed that the skeleton is already a relatively high-level and low-dimension feature, but not in the same manifold as the features for action recognition. Simply applying the existing unsupervised learning method may tend to produce features that discriminate the different samples instead of action classes, resulting in the overfitting problem. To solve this problem, this paper presents an Unsupervised spatial-temporal Feature Enrichment and Fidelity Preservation framework (U-FEFP) to generate rich distributed features that contain all the information of the skeleton sequence. A spatial-temporal feature transformation subnetwork is developed using spatial-temporal graph convolutional network and graph convolutional gate recurrent unit network as the basic feature extraction network. The unsupervised Bootstrap Your Own Latent based learning is used to generate rich distributed features and the unsupervised pretext task based learning is used to preserve the information of the skeleton sequence. The two unsupervised learning ways are collaborated as U-FEFP to produce robust and discriminative representations. Experimental results on three widely used benchmarks, namely NTU-RGB+D-60, NTU-RGB+D-120 and PKU-MMD dataset, demonstrate that the proposed U-FEFP achieves the best performance compared with the state-of-the-art unsupervised learning methods. t-SNE illustrations further validate that U-FEFP can learn more discriminative features for unsupervised skeleton based action recognition.
Spatial-Temporal Transformer based Video Compression Framework
Sep 21, 2023Learned video compression (LVC) has witnessed remarkable advancements in recent years. Similar as the traditional video coding, LVC inherits motion estimation/compensation, residual coding and other modules, all of which are implemented with neural networks (NNs). However, within the framework of NNs and its training mechanism using gradient backpropagation, most existing works often struggle to consistently generate stable motion information, which is in the form of geometric features, from the input color features. Moreover, the modules such as the inter-prediction and residual coding are independent from each other, making it inefficient to fully reduce the spatial-temporal redundancy. To address the above problems, in this paper, we propose a novel Spatial-Temporal Transformer based Video Compression (STT-VC) framework. It contains a Relaxed Deformable Transformer (RDT) with Uformer based offsets estimation for motion estimation and compensation, a Multi-Granularity Prediction (MGP) module based on multi-reference frames for prediction refinement, and a Spatial Feature Distribution prior based Transformer (SFD-T) for efficient temporal-spatial joint residual compression. Specifically, RDT is developed to stably estimate the motion information between frames by thoroughly investigating the relationship between the similarity based geometric motion feature extraction and self-attention. MGP is designed to fuse the multi-reference frame information by effectively exploring the coarse-grained prediction feature generated with the coded motion information. SFD-T is to compress the residual information by jointly exploring the spatial feature distributions in both residual and temporal prediction to further reduce the spatial-temporal redundancy. Experimental results demonstrate that our method achieves the best result with 13.5% BD-Rate saving over VTM.
A Global Appearance and Local Coding Distortion based Fusion Framework for CNN based Filtering in Video Coding
Jun 24, 2021

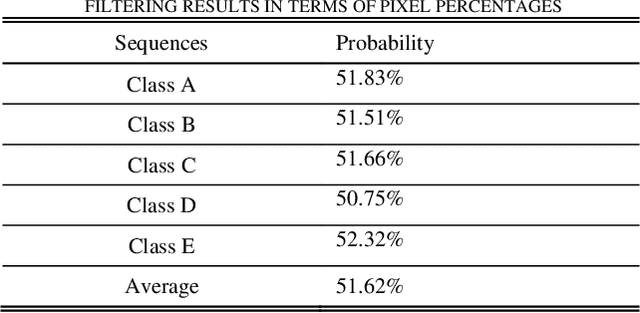
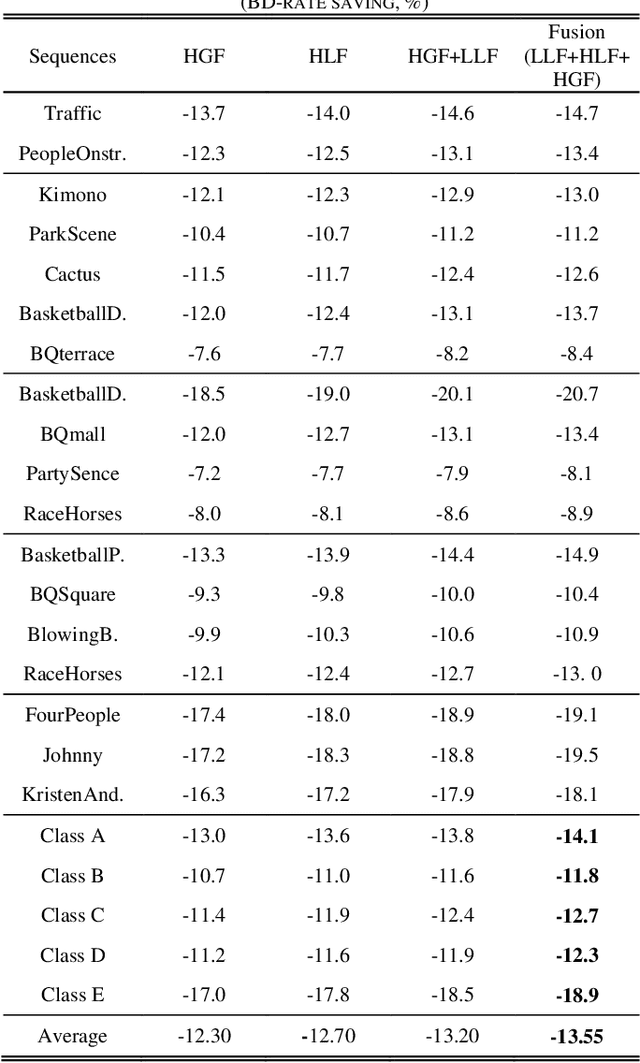
In-loop filtering is used in video coding to process the reconstructed frame in order to remove blocking artifacts. With the development of convolutional neural networks (CNNs), CNNs have been explored for in-loop filtering considering it can be treated as an image de-noising task. However, in addition to being a distorted image, the reconstructed frame is also obtained by a fixed line of block based encoding operations in video coding. It carries coding-unit based coding distortion of some similar characteristics. Therefore, in this paper, we address the filtering problem from two aspects, global appearance restoration for disrupted texture and local coding distortion restoration caused by fixed pipeline of coding. Accordingly, a three-stream global appearance and local coding distortion based fusion network is developed with a high-level global feature stream, a high-level local feature stream and a low-level local feature stream. Ablation study is conducted to validate the necessity of different features, demonstrating that the global features and local features can complement each other in filtering and achieve better performance when combined. To the best of our knowledge, we are the first one that clearly characterizes the video filtering process from the above global appearance and local coding distortion restoration aspects with experimental verification, providing a clear pathway to developing filter techniques. Experimental results demonstrate that the proposed method significantly outperforms the existing single-frame based methods and achieves 13.5%, 11.3%, 11.7% BD-Rate saving on average for AI, LDP and RA configurations, respectively, compared with the HEVC reference software.
A Two-stream Neural Network for Pose-based Hand Gesture Recognition
Jan 22, 2021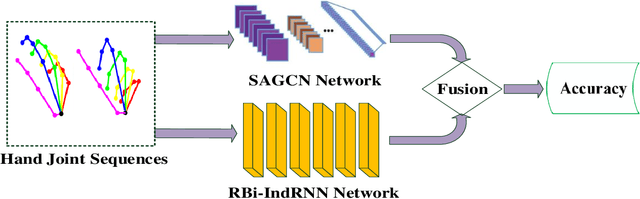
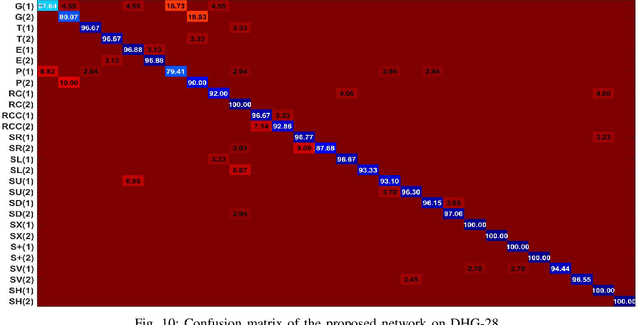

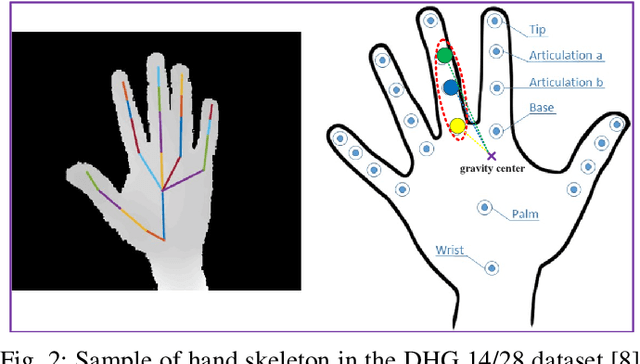
Pose based hand gesture recognition has been widely studied in the recent years. Compared with full body action recognition, hand gesture involves joints that are more spatially closely distributed with stronger collaboration. This nature requires a different approach from action recognition to capturing the complex spatial features. Many gesture categories, such as "Grab" and "Pinch", have very similar motion or temporal patterns posing a challenge on temporal processing. To address these challenges, this paper proposes a two-stream neural network with one stream being a self-attention based graph convolutional network (SAGCN) extracting the short-term temporal information and hierarchical spatial information, and the other being a residual-connection enhanced bidirectional Independently Recurrent Neural Network (RBi-IndRNN) for extracting long-term temporal information. The self-attention based graph convolutional network has a dynamic self-attention mechanism to adaptively exploit the relationships of all hand joints in addition to the fixed topology and local feature extraction in the GCN. On the other hand, the residual-connection enhanced Bi-IndRNN extends an IndRNN with the capability of bidirectional processing for temporal modelling. The two streams are fused together for recognition. The Dynamic Hand Gesture dataset and First-Person Hand Action dataset are used to validate its effectiveness, and our method achieves state-of-the-art performance.
A Framework of Combining Short-Term Spatial/Frequency Feature Extraction and Long-Term IndRNN for Activity Recognition
Nov 06, 2020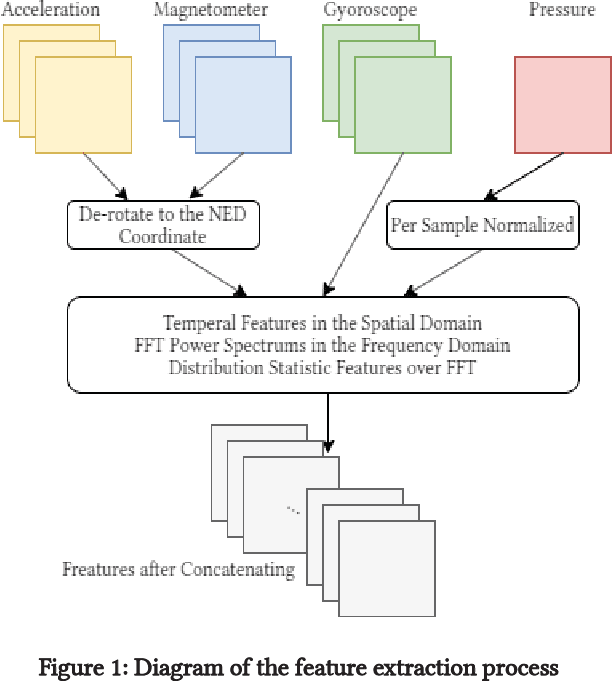
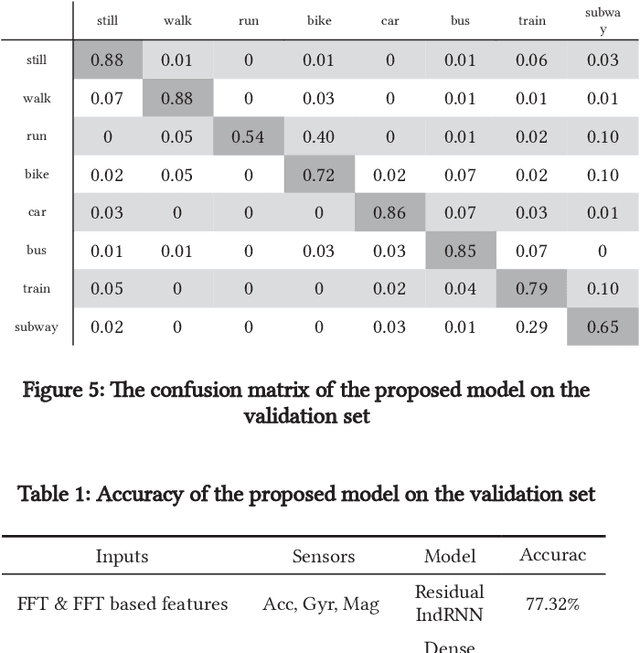
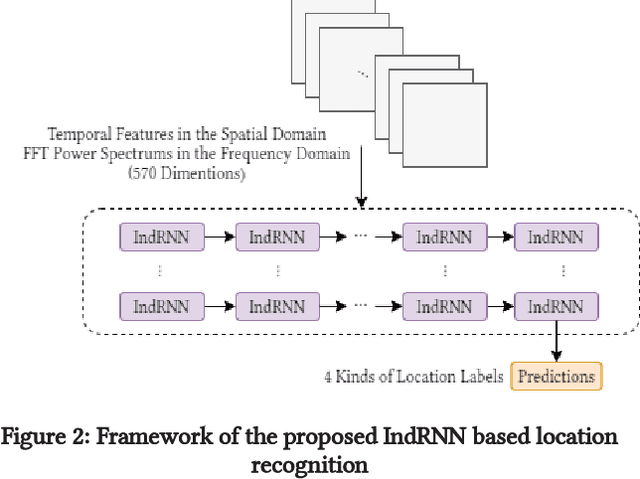

Smartphone sensors based human activity recognition is attracting increasing interests nowadays with the popularization of smartphones. With the high sampling rates of smartphone sensors, it is a highly long-range temporal recognition problem, especially with the large intra-class distances such as the smartphones carried at different locations such as in the bag or on the body, and the small inter-class distances such as taking train or subway. To address this problem, we propose a new framework of combining short-term spatial/frequency feature extraction and a long-term Independently Recurrent Neural Network (IndRNN) for activity recognition. Considering the periodic characteristics of the sensor data, short-term temporal features are first extracted in the spatial and frequency domains. Then the IndRNN, which is able to capture long-term patterns, is used to further obtain the long-term features for classification. In view of the large differences when the smartphone is carried at different locations, a group based location recognition is first developed to pinpoint the location of the smartphone. The Sussex-Huawei Locomotion (SHL) dataset from the SHL Challenge is used for evaluation. An earlier version of the proposed method has won the second place award in the SHL Challenge 2020 (the first place if not considering multiple models fusion approach). The proposed method is further improved in this paper and achieves 80.72$\%$ accuracy, better than the existing methods using a single model.
Deep Independently Recurrent Neural Network (IndRNN)
Oct 21, 2019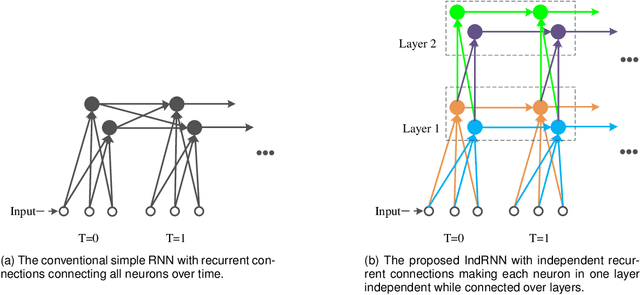

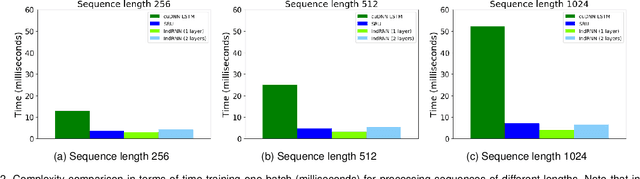
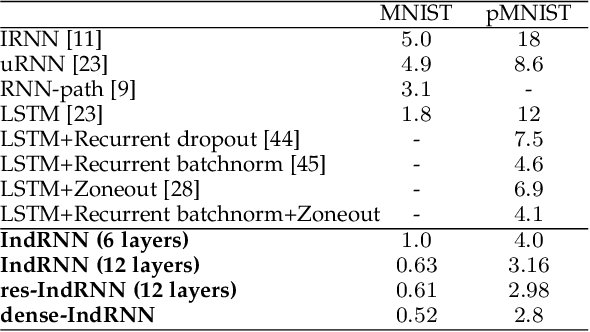
Recurrent neural networks (RNNs) are known to be difficult to train due to the gradient vanishing and exploding problems and thus difficult to learn long-term patterns. Long short-term memory (LSTM) was developed to address these problems, but the use of hyperbolic tangent and the sigmoid activation functions results in gradient decay over layers. Consequently, construction of an efficiently trainable deep RNN is challenging. Moreover, training of LSTM is very compute-intensive as the recurrent connection using matrix product is conducted at every time step. To address these problems, this paper proposes a new type of RNNs with the recurrent connection formulated as Hadamard product, referred to as independently recurrent neural network (IndRNN), where neurons in the same layer are independent of each other and connected across layers. The gradient vanishing and exploding problems are solved in IndRNN by simply regulating the recurrent weights, and thus long-term dependencies can be learned. Moreover, an IndRNN can work with non-saturated activation functions such as ReLU and be still trained robustly. Different deeper IndRNN architectures, including the basic stacked IndRNN, residual IndRNN and densely connected IndRNN, have been investigated, all of which can be much deeper than the existing RNNs. Furthermore, IndRNN reduces the computation at each time step and can be over 10 times faster than the LSTM. The code is made publicly available at https://github.com/Sunnydreamrain/IndRNN_pytorch. Experimental results have shown that the proposed IndRNN is able to process very long sequences (over 5000 time steps), can be used to construct very deep networks (the 21 layers residual IndRNN and deep densely connected IndRNN used in the experiment for example). Better performances have been achieved on various tasks with IndRNNs compared with the traditional RNN and LSTM.
Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN
May 22, 2018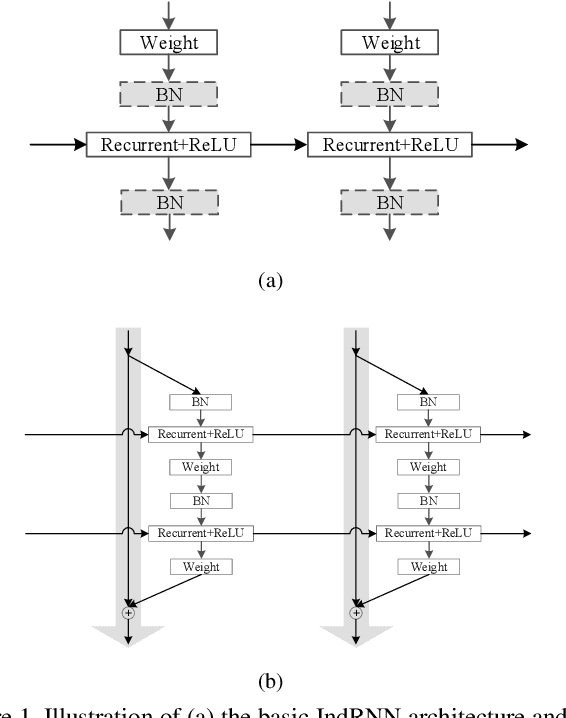
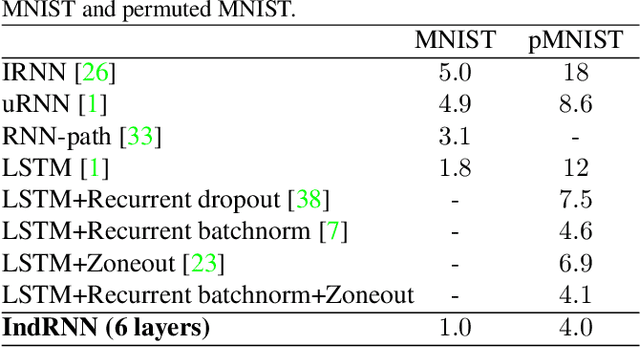
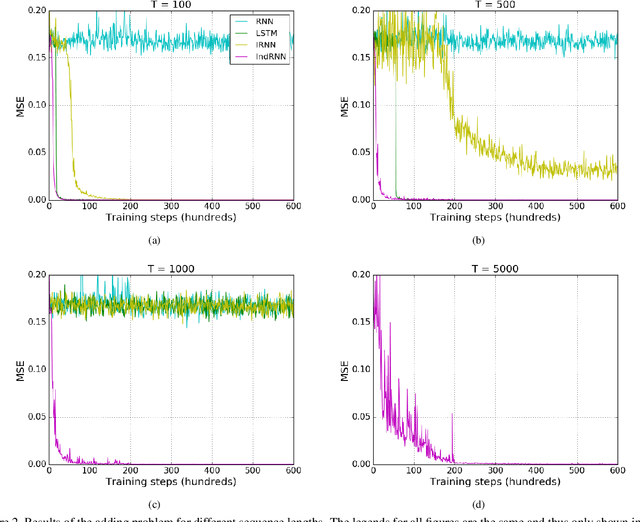
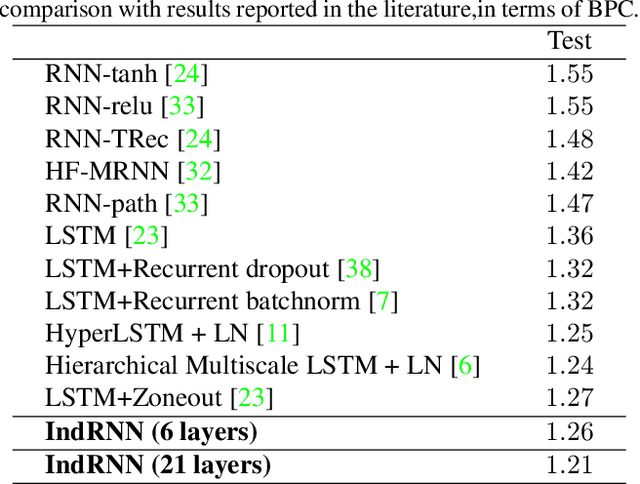
Recurrent neural networks (RNNs) have been widely used for processing sequential data. However, RNNs are commonly difficult to train due to the well-known gradient vanishing and exploding problems and hard to learn long-term patterns. Long short-term memory (LSTM) and gated recurrent unit (GRU) were developed to address these problems, but the use of hyperbolic tangent and the sigmoid action functions results in gradient decay over layers. Consequently, construction of an efficiently trainable deep network is challenging. In addition, all the neurons in an RNN layer are entangled together and their behaviour is hard to interpret. To address these problems, a new type of RNN, referred to as independently recurrent neural network (IndRNN), is proposed in this paper, where neurons in the same layer are independent of each other and they are connected across layers. We have shown that an IndRNN can be easily regulated to prevent the gradient exploding and vanishing problems while allowing the network to learn long-term dependencies. Moreover, an IndRNN can work with non-saturated activation functions such as relu (rectified linear unit) and be still trained robustly. Multiple IndRNNs can be stacked to construct a network that is deeper than the existing RNNs. Experimental results have shown that the proposed IndRNN is able to process very long sequences (over 5000 time steps), can be used to construct very deep networks (21 layers used in the experiment) and still be trained robustly. Better performances have been achieved on various tasks by using IndRNNs compared with the traditional RNN and LSTM. The code is available at https://github.com/Sunnydreamrain/IndRNN_Theano_Lasagne.
A Fully Trainable Network with RNN-based Pooling
Jun 16, 2017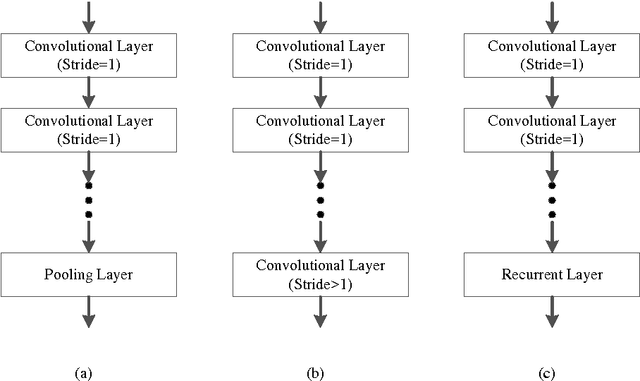
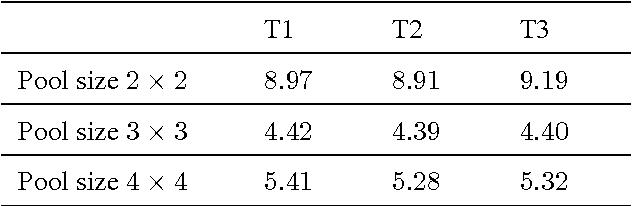
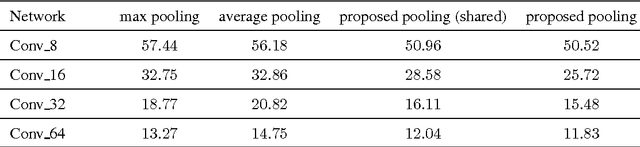
Pooling is an important component in convolutional neural networks (CNNs) for aggregating features and reducing computational burden. Compared with other components such as convolutional layers and fully connected layers which are completely learned from data, the pooling component is still handcrafted such as max pooling and average pooling. This paper proposes a learnable pooling function using recurrent neural networks (RNN) so that the pooling can be fully adapted to data and other components of the network, leading to an improved performance. Such a network with learnable pooling function is referred to as a fully trainable network (FTN). Experimental results have demonstrated that the proposed RNN-based pooling can well approximate the existing pooling functions and improve the performance of the network. Especially for small networks, the proposed FTN can improve the performance by seven percentage points in terms of error rate on the CIFAR-10 dataset compared with the traditional CNN.