 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiftFormer: Lifting and Frame Theory Based Monocular Depth Estimation Using Depth and Edge Oriented Subspace Representation
Apr 08, 2026Monocular depth estimation (MDE) has attracted increasing interest in the past few years, owing to its important role in 3D vision. MDE is the estimation of a depth map from a monocular image/video to represent the 3D structure of a scene, which is a highly ill-posed problem. To solve this problem, in this paper, we propose a LiftFormer based on lifting theory topology, for constructing an intermediate subspace that bridges the image color features and depth values, and a subspace that enhances the depth prediction around edges. MDE is formulated by transforming the depth value prediction problem into depth-oriented geometric representation (DGR) subspace feature representation, thus bridging the learning from color values to geometric depth values. A DGR subspace is constructed based on frame theory by using linearly dependent vectors in accordance with depth bins to provide a redundant and robust representation. The image spatial features are transformed into the DGR subspace, where these features correspond directly to the depth values. Moreover, considering that edges usually present sharp changes in a depth map and tend to be erroneously predicted, an edge-aware representation (ER) subspace is constructed, where depth features are transformed and further used to enhance the local features around edges. The experimental results demonstrate that our LiftFormer achieves state-of-the-art performance on widely used datasets, and an ablation study validates the effectiveness of both proposed lifting modules in our LiftFormer.
Spectral Discrepancy and Cross-modal Semantic Consistency Learning for Object Detection in Hyperspectral Image
Dec 20, 2025Hyperspectral images with high spectral resolution provide new insights into recognizing subtle differences in similar substances. However, object detection in hyperspectral images faces significant challenges in intra- and inter-class similarity due to the spatial differences in hyperspectral inter-bands and unavoidable interferences, e.g., sensor noises and illumination. To alleviate the hyperspectral inter-bands inconsistencies and redundancy, we propose a novel network termed \textbf{S}pectral \textbf{D}iscrepancy and \textbf{C}ross-\textbf{M}odal semantic consistency learning (SDCM), which facilitates the extraction of consistent information across a wide range of hyperspectral bands while utilizing the spectral dimension to pinpoint regions of interest. Specifically, we leverage a semantic consistency learning (SCL) module that utilizes inter-band contextual cues to diminish the heterogeneity of information among bands, yielding highly coherent spectral dimension representations. On the other hand, we incorporate a spectral gated generator (SGG) into the framework that filters out the redundant data inherent in hyperspectral information based on the importance of the bands. Then, we design the spectral discrepancy aware (SDA) module to enrich the semantic representation of high-level information by extracting pixel-level spectral features. Extensive experiments on two hyperspectral datasets demonstrate that our proposed method achieves state-of-the-art performance when compared with other ones.
MetricGrids: Arbitrary Nonlinear Approximation with Elementary Metric Grids based Implicit Neural Representation
Mar 13, 2025
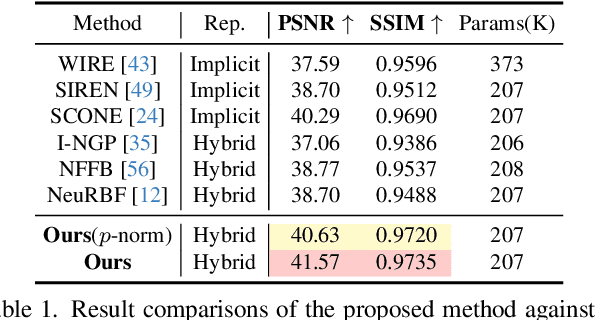

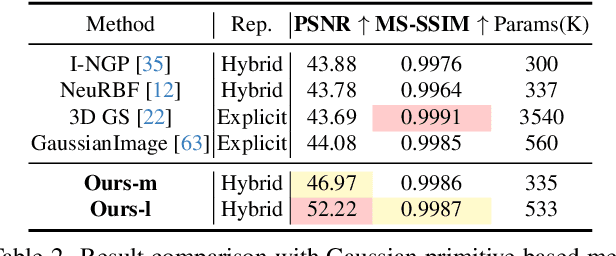
This paper presents MetricGrids, a novel grid-based neural representation that combines elementary metric grids in various metric spaces to approximate complex nonlinear signals. While grid-based representations are widely adopted for their efficiency and scalability, the existing feature grids with linear indexing for continuous-space points can only provide degenerate linear latent space representations, and such representations cannot be adequately compensated to represent complex nonlinear signals by the following compact decoder. To address this problem while keeping the simplicity of a regular grid structure, our approach builds upon the standard grid-based paradigm by constructing multiple elementary metric grids as high-order terms to approximate complex nonlinearities, following the Taylor expansion principle. Furthermore, we enhance model compactness with hash encoding based on different sparsities of the grids to prevent detrimental hash collisions, and a high-order extrapolation decoder to reduce explicit grid storage requirements. experimental results on both 2D and 3D reconstructions demonstrate the superior fitting and rendering accuracy of the proposed method across diverse signal types, validating its robustness and generalizability. Code is available at https://github.com/wangshu31/MetricGrids}{https://github.com/wangshu31/MetricGrids.
Unsupervised Spatial-Temporal Feature Enrichment and Fidelity Preservation Network for Skeleton based Action Recognition
Jan 25, 2024Unsupervised skeleton based action recognition has achieved remarkable progress recently. Existing unsupervised learning methods suffer from severe overfitting problem, and thus small networks are used, significantly reducing the representation capability. To address this problem, the overfitting mechanism behind the unsupervised learning for skeleton based action recognition is first investigated. It is observed that the skeleton is already a relatively high-level and low-dimension feature, but not in the same manifold as the features for action recognition. Simply applying the existing unsupervised learning method may tend to produce features that discriminate the different samples instead of action classes, resulting in the overfitting problem. To solve this problem, this paper presents an Unsupervised spatial-temporal Feature Enrichment and Fidelity Preservation framework (U-FEFP) to generate rich distributed features that contain all the information of the skeleton sequence. A spatial-temporal feature transformation subnetwork is developed using spatial-temporal graph convolutional network and graph convolutional gate recurrent unit network as the basic feature extraction network. The unsupervised Bootstrap Your Own Latent based learning is used to generate rich distributed features and the unsupervised pretext task based learning is used to preserve the information of the skeleton sequence. The two unsupervised learning ways are collaborated as U-FEFP to produce robust and discriminative representations. Experimental results on three widely used benchmarks, namely NTU-RGB+D-60, NTU-RGB+D-120 and PKU-MMD dataset, demonstrate that the proposed U-FEFP achieves the best performance compared with the state-of-the-art unsupervised learning methods. t-SNE illustrations further validate that U-FEFP can learn more discriminative features for unsupervised skeleton based action recognition.
A Two-stream Neural Network for Pose-based Hand Gesture Recognition
Jan 22, 2021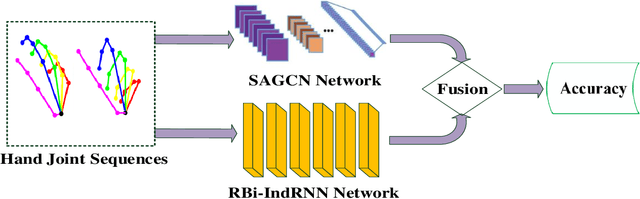
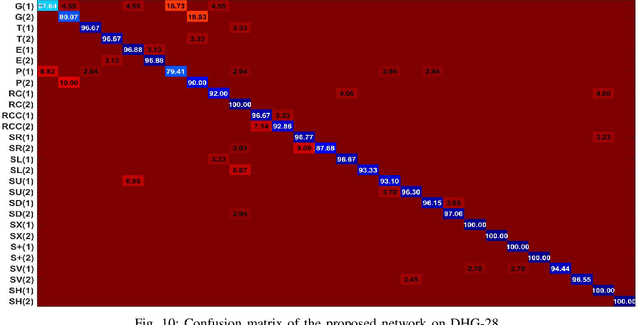

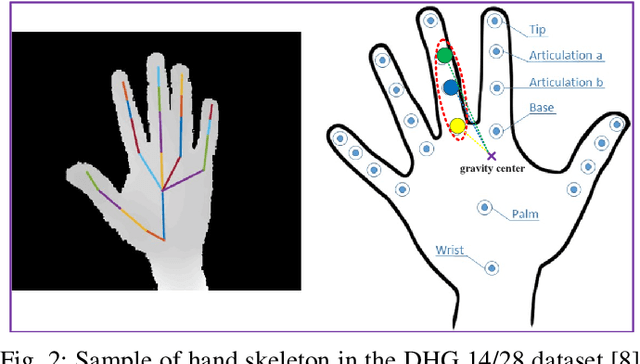
Pose based hand gesture recognition has been widely studied in the recent years. Compared with full body action recognition, hand gesture involves joints that are more spatially closely distributed with stronger collaboration. This nature requires a different approach from action recognition to capturing the complex spatial features. Many gesture categories, such as "Grab" and "Pinch", have very similar motion or temporal patterns posing a challenge on temporal processing. To address these challenges, this paper proposes a two-stream neural network with one stream being a self-attention based graph convolutional network (SAGCN) extracting the short-term temporal information and hierarchical spatial information, and the other being a residual-connection enhanced bidirectional Independently Recurrent Neural Network (RBi-IndRNN) for extracting long-term temporal information. The self-attention based graph convolutional network has a dynamic self-attention mechanism to adaptively exploit the relationships of all hand joints in addition to the fixed topology and local feature extraction in the GCN. On the other hand, the residual-connection enhanced Bi-IndRNN extends an IndRNN with the capability of bidirectional processing for temporal modelling. The two streams are fused together for recognition. The Dynamic Hand Gesture dataset and First-Person Hand Action dataset are used to validate its effectiveness, and our method achieves state-of-the-art performance.
A Framework of Combining Short-Term Spatial/Frequency Feature Extraction and Long-Term IndRNN for Activity Recognition
Nov 06, 2020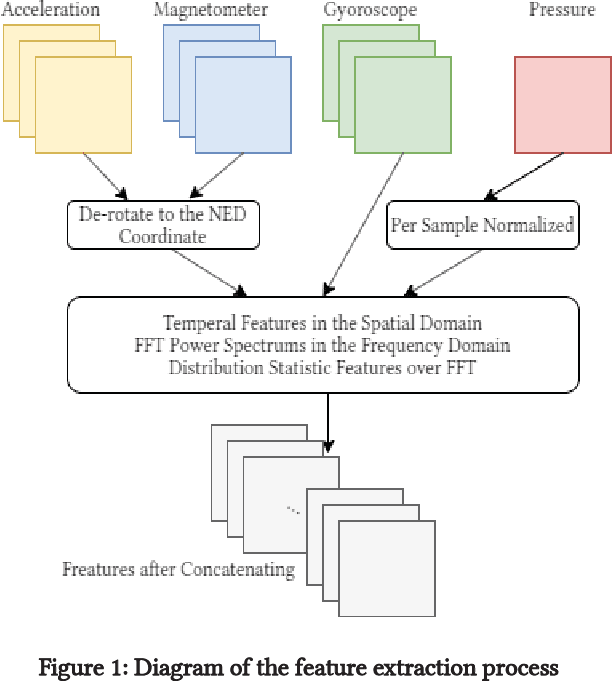
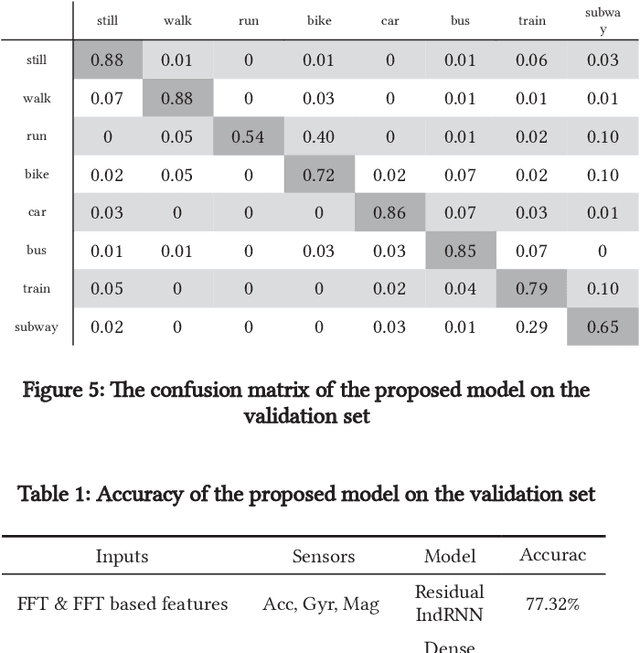
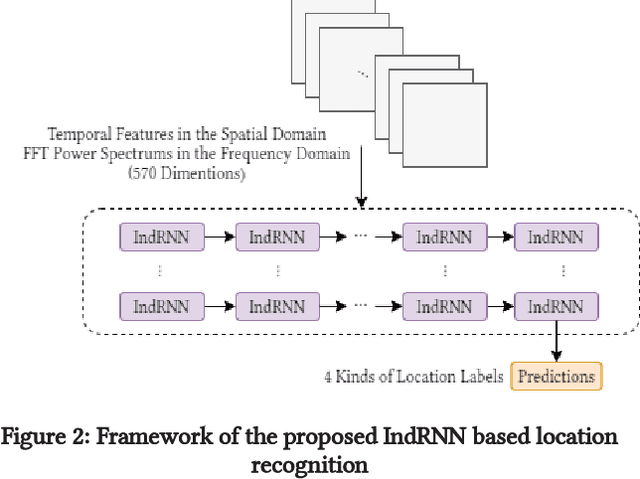

Smartphone sensors based human activity recognition is attracting increasing interests nowadays with the popularization of smartphones. With the high sampling rates of smartphone sensors, it is a highly long-range temporal recognition problem, especially with the large intra-class distances such as the smartphones carried at different locations such as in the bag or on the body, and the small inter-class distances such as taking train or subway. To address this problem, we propose a new framework of combining short-term spatial/frequency feature extraction and a long-term Independently Recurrent Neural Network (IndRNN) for activity recognition. Considering the periodic characteristics of the sensor data, short-term temporal features are first extracted in the spatial and frequency domains. Then the IndRNN, which is able to capture long-term patterns, is used to further obtain the long-term features for classification. In view of the large differences when the smartphone is carried at different locations, a group based location recognition is first developed to pinpoint the location of the smartphone. The Sussex-Huawei Locomotion (SHL) dataset from the SHL Challenge is used for evaluation. An earlier version of the proposed method has won the second place award in the SHL Challenge 2020 (the first place if not considering multiple models fusion approach). The proposed method is further improved in this paper and achieves 80.72$\%$ accuracy, better than the existing methods using a single model.
Skeleton-based Action Recognition Using LSTM and CNN
Jul 06, 2017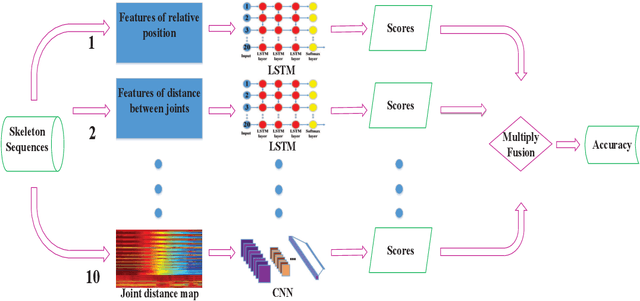
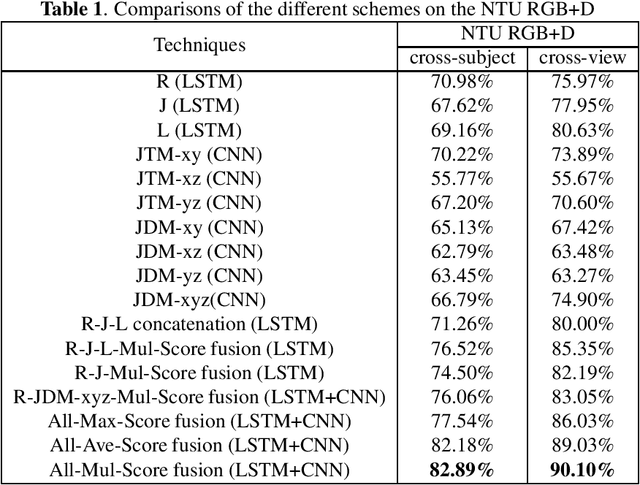
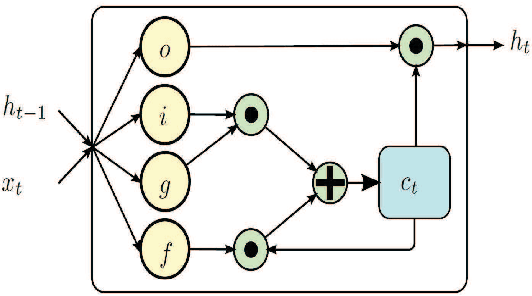
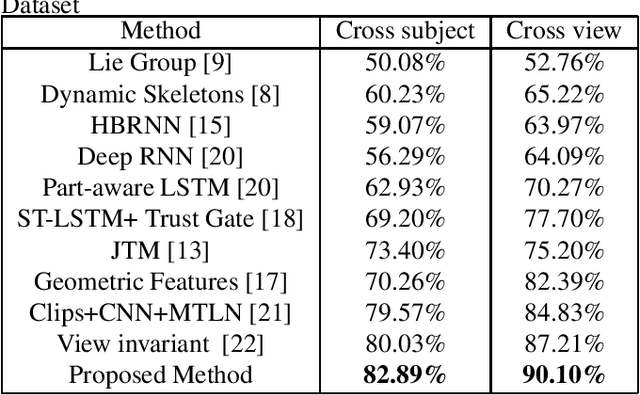
Recent methods based on 3D skeleton data have achieved outstanding performance due to its conciseness, robustness, and view-independent representation. With the development of deep learning, Convolutional Neural Networks (CNN) and Long Short Term Memory (LSTM)-based learning methods have achieved promising performance for action recognition. However, for CNN-based methods, it is inevitable to loss temporal information when a sequence is encoded into images. In order to capture as much spatial-temporal information as possible, LSTM and CNN are adopted to conduct effective recognition with later score fusion. In addition, experimental results show that the score fusion between CNN and LSTM performs better than that between LSTM and LSTM for the same feature. Our method achieved state-of-the-art results on NTU RGB+D datasets for 3D human action analysis. The proposed method achieved 87.40% in terms of accuracy and ranked $1^{st}$ place in Large Scale 3D Human Activity Analysis Challenge in Depth Videos.
Action Recognition Based on Joint Trajectory Maps with Convolutional Neural Networks
Dec 30, 2016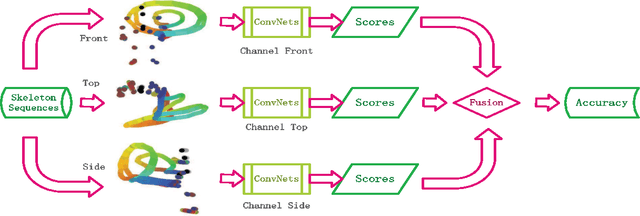
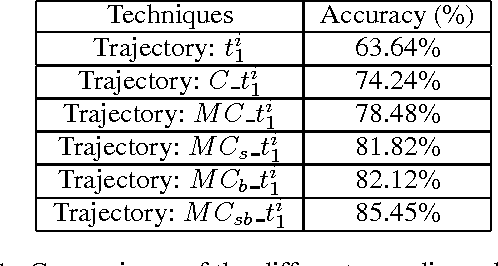


Convolutional Neural Networks (ConvNets) have recently shown promising performance in many computer vision tasks, especially image-based recognition. How to effectively apply ConvNets to sequence-based data is still an open problem. This paper proposes an effective yet simple method to represent spatio-temporal information carried in $3D$ skeleton sequences into three $2D$ images by encoding the joint trajectories and their dynamics into color distribution in the images, referred to as Joint Trajectory Maps (JTM), and adopts ConvNets to learn the discriminative features for human action recognition. Such an image-based representation enables us to fine-tune existing ConvNets models for the classification of skeleton sequences without training the networks afresh. The three JTMs are generated in three orthogonal planes and provide complimentary information to each other. The final recognition is further improved through multiply score fusion of the three JTMs. The proposed method was evaluated on four public benchmark datasets, the large NTU RGB+D Dataset, MSRC-12 Kinect Gesture Dataset (MSRC-12), G3D Dataset and UTD Multimodal Human Action Dataset (UTD-MHAD) and achieved the state-of-the-art results.