 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Recognition Based on Joint Trajectory Maps with Convolutional Neural Networks
Paper and Code
Dec 30, 2016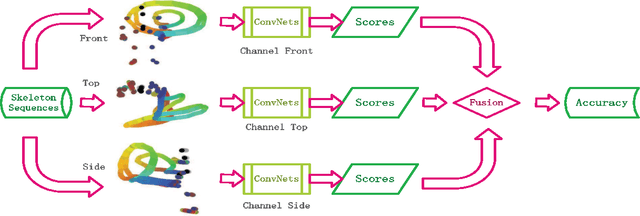
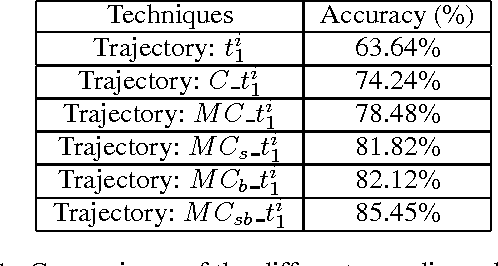


Convolutional Neural Networks (ConvNets) have recently shown promising performance in many computer vision tasks, especially image-based recognition. How to effectively apply ConvNets to sequence-based data is still an open problem. This paper proposes an effective yet simple method to represent spatio-temporal information carried in $3D$ skeleton sequences into three $2D$ images by encoding the joint trajectories and their dynamics into color distribution in the images, referred to as Joint Trajectory Maps (JTM), and adopts ConvNets to learn the discriminative features for human action recognition. Such an image-based representation enables us to fine-tune existing ConvNets models for the classification of skeleton sequences without training the networks afresh. The three JTMs are generated in three orthogonal planes and provide complimentary information to each other. The final recognition is further improved through multiply score fusion of the three JTMs. The proposed method was evaluated on four public benchmark datasets, the large NTU RGB+D Dataset, MSRC-12 Kinect Gesture Dataset (MSRC-12), G3D Dataset and UTD Multimodal Human Action Dataset (UTD-MHAD) and achieved the state-of-the-art results.