 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemMachine: A Ground-Truth-Preserving Memory System for Personalized AI Agents
Apr 06, 2026Large Language Model (LLM) agents require persistent memory to maintain personalization, factual continuity, and long-horizon reasoning, yet standard context-window and retrieval-augmented generation (RAG) pipelines degrade over multi-session interactions. We present MemMachine, an open-source memory system that integrates short-term, long-term episodic, and profile memory within a ground-truth-preserving architecture that stores entire conversational episodes and reduces lossy LLM-based extraction. MemMachine uses contextualized retrieval that expands nucleus matches with surrounding context, improving recall when relevant evidence spans multiple dialogue turns. Across benchmarks, MemMachine achieves strong accuracy-efficiency tradeoffs: on LoCoMo it reaches 0.9169 using gpt4.1-mini; on LongMemEvalS (ICLR 2025), a six-dimension ablation yields 93.0 percent accuracy, with retrieval-stage optimizations -- retrieval depth tuning (+4.2 percent), context formatting (+2.0 percent), search prompt design (+1.8 percent), and query bias correction (+1.4 percent) -- outperforming ingestion-stage gains such as sentence chunking (+0.8 percent). GPT-5-mini exceeds GPT-5 by 2.6 percent when paired with optimized prompts, making it the most cost-efficient setup. Compared to Mem0, MemMachine uses roughly 80 percent fewer input tokens under matched conditions. A companion Retrieval Agent adaptively routes queries among direct retrieval, parallel decomposition, or iterative chain-of-query strategies, achieving 93.2 percent on HotpotQA-hard and 92.6 percent on WikiMultiHop under randomized-noise conditions. These results show that preserving episodic ground truth while layering adaptive retrieval yields robust, efficient long-term memory for personalized LLM agents.
LLM+Graph@VLDB'2025 Workshop Summary
Apr 03, 2026The integration of large language models (LLMs) with graph-structured data has become a pivotal and fast evolving research frontier, drawing strong interest from both academia and industry. The 2nd LLM+Graph Workshop, co-located with the 51st International Conference on Very Large Data Bases (VLDB 2025) in London, focused on advancing algorithms and systems that bridge LLMs, graph data management, and graph machine learning for practical applications. This report highlights the key research directions, challenges, and innovative solutions presented by the workshop's speakers.
Adapting SAM to Nuclei Instance Segmentation and Classification via Cooperative Fine-Grained Refinement
Mar 30, 2026Nuclei instance segmentation is critical in computational pathology for cancer diagnosis and prognosis. Recently, the Segment Anything Model has demonstrated exceptional performance in various segmentation tasks, leveraging its rich priors and powerful global context modeling capabilities derived from large-scale pre-training on natural images. However, directly applying SAM to the medical imaging domain faces significant limitations: it lacks sufficient perception of the local structural features that are crucial for nuclei segmentation, and full fine-tuning for downstream tasks requires substantial computational costs. To efficiently transfer SAM's robust prior knowledge to nuclei instance segmentation while supplementing its task-aware local perception, we propose a parameter-efficient fine-tuning framework, named Cooperative Fine-Grained Refinement of SAM, consisting of three core components: 1) a Multi-scale Adaptive Local-aware Adapter, which enables effective capability transfer by augmenting the frozen SAM backbone with minimal parameters and instilling a powerful perception of local structures through dynamically generated, multi-scale convolutional kernels; 2) a Hierarchical Modulated Fusion Module, which dynamically aggregates multi-level encoder features to preserve fine-grained spatial details; and 3) a Boundary-Guided Mask Refinement, which integrates multi-context boundary cues with semantic features through explicit supervision, producing a boundary-focused signal to refine initial mask predictions for sharper delineation. These three components work cooperatively to enhance local perception, preserve spatial details, and refine boundaries, enabling SAM to perform accurate nuclei instance segmentation directly.
VecFormer: Towards Efficient and Generalizable Graph Transformer with Graph Token Attention
Feb 23, 2026Graph Transformer has demonstrated impressive capabilities in the field of graph representation learning. However, existing approaches face two critical challenges: (1) most models suffer from exponentially increasing computational complexity, making it difficult to scale to large graphs; (2) attention mechanisms based on node-level operations limit the flexibility of the model and result in poor generalization performance in out-of-distribution (OOD) scenarios. To address these issues, we propose \textbf{VecFormer} (the \textbf{Vec}tor Quantized Graph Trans\textbf{former}), an efficient and highly generalizable model for node classification, particularly under OOD settings. VecFormer adopts a two-stage training paradigm. In the first stage, two codebooks are used to reconstruct the node features and the graph structure, aiming to learn the rich semantic \texttt{Graph Codes}. In the second stage, attention mechanisms are performed at the \texttt{Graph Token} level based on the transformed cross codebook, reducing computational complexity while enhancing the model's generalization capability. Extensive experiments on datasets of various sizes demonstrate that VecFormer outperforms the existing Graph Transformer in both performance and speed.
Integrated Exploration and Sequential Manipulation on Scene Graph with LLM-based Situated Replanning
Feb 04, 2026In partially known environments, robots must combine exploration to gather information with task planning for efficient execution. To address this challenge, we propose EPoG, an Exploration-based sequential manipulation Planning framework on Scene Graphs. EPoG integrates a graph-based global planner with a Large Language Model (LLM)-based situated local planner, continuously updating a belief graph using observations and LLM predictions to represent known and unknown objects. Action sequences are generated by computing graph edit operations between the goal and belief graphs, ordered by temporal dependencies and movement costs. This approach seamlessly combines exploration and sequential manipulation planning. In ablation studies across 46 realistic household scenes and 5 long-horizon daily object transportation tasks, EPoG achieved a success rate of 91.3%, reducing travel distance by 36.1% on average. Furthermore, a physical mobile manipulator successfully executed complex tasks in unknown and dynamic environments, demonstrating EPoG's potential for real-world applications.
HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
Dec 10, 2025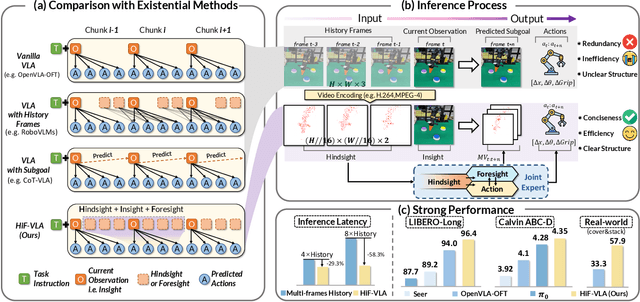
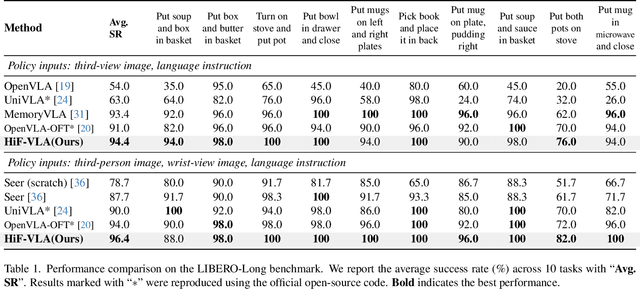
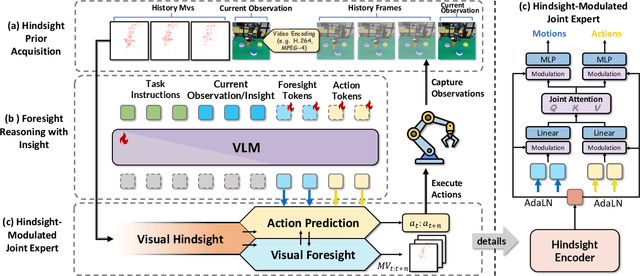
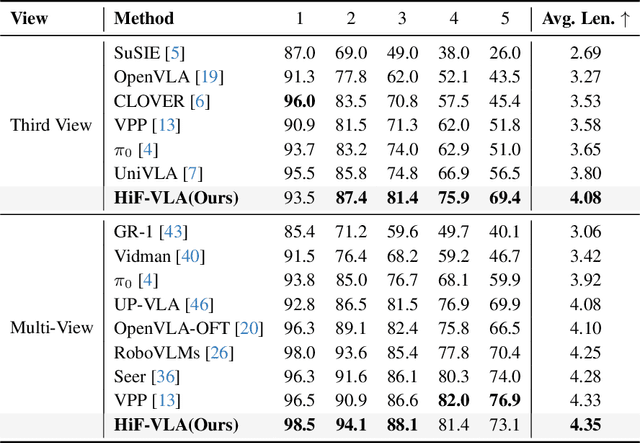
Vision-Language-Action (VLA) models have recently enabled robotic manipulation by grounding visual and linguistic cues into actions. However, most VLAs assume the Markov property, relying only on the current observation and thus suffering from temporal myopia that degrades long-horizon coherence. In this work, we view motion as a more compact and informative representation of temporal context and world dynamics, capturing inter-state changes while filtering static pixel-level noise. Building on this idea, we propose HiF-VLA (Hindsight, Insight, and Foresight for VLAs), a unified framework that leverages motion for bidirectional temporal reasoning. HiF-VLA encodes past dynamics through hindsight priors, anticipates future motion via foresight reasoning, and integrates both through a hindsight-modulated joint expert to enable a ''think-while-acting'' paradigm for long-horizon manipulation. As a result, HiF-VLA surpasses strong baselines on LIBERO-Long and CALVIN ABC-D benchmarks, while incurring negligible additional inference latency. Furthermore, HiF-VLA achieves substantial improvements in real-world long-horizon manipulation tasks, demonstrating its broad effectiveness in practical robotic settings.
Semi-Supervised State-Space Model with Dynamic Stacking Filter for Real-World Video Deraining
May 22, 2025

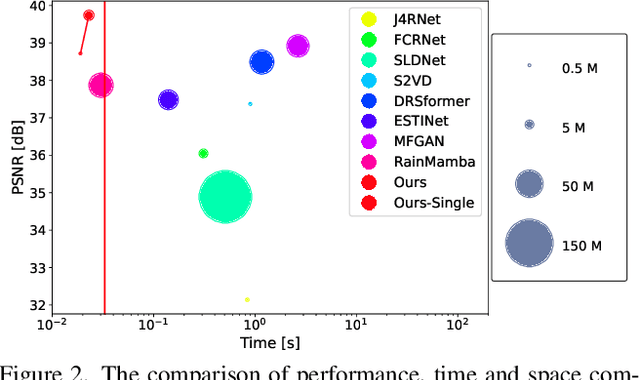

Significant progress has been made in video restoration under rainy conditions over the past decade, largely propelled by advancements in deep learning. Nevertheless, existing methods that depend on paired data struggle to generalize effectively to real-world scenarios, primarily due to the disparity between synthetic and authentic rain effects. To address these limitations, we propose a dual-branch spatio-temporal state-space model to enhance rain streak removal in video sequences. Specifically, we design spatial and temporal state-space model layers to extract spatial features and incorporate temporal dependencies across frames, respectively. To improve multi-frame feature fusion, we derive a dynamic stacking filter, which adaptively approximates statistical filters for superior pixel-wise feature refinement. Moreover, we develop a median stacking loss to enable semi-supervised learning by generating pseudo-clean patches based on the sparsity prior of rain. To further explore the capacity of deraining models in supporting other vision-based tasks in rainy environments, we introduce a novel real-world benchmark focused on object detection and tracking in rainy conditions. Our method is extensively evaluated across multiple benchmarks containing numerous synthetic and real-world rainy videos, consistently demonstrating its superiority in quantitative metrics, visual quality, efficiency, and its utility for downstream tasks.
ChainMarks: Securing DNN Watermark with Cryptographic Chain
May 08, 2025



With the widespread deployment of deep neural network (DNN) models, dynamic watermarking techniques are being used to protect the intellectual property of model owners. However, recent studies have shown that existing watermarking schemes are vulnerable to watermark removal and ambiguity attacks. Besides, the vague criteria for determining watermark presence further increase the likelihood of such attacks. In this paper, we propose a secure DNN watermarking scheme named ChainMarks, which generates secure and robust watermarks by introducing a cryptographic chain into the trigger inputs and utilizes a two-phase Monte Carlo method for determining watermark presence. First, ChainMarks generates trigger inputs as a watermark dataset by repeatedly applying a hash function over a secret key, where the target labels associated with trigger inputs are generated from the digital signature of model owner. Then, the watermarked model is produced by training a DNN over both the original and watermark datasets. To verify watermarks, we compare the predicted labels of trigger inputs with the target labels and determine ownership with a more accurate decision threshold that considers the classification probability of specific models. Experimental results show that ChainMarks exhibits higher levels of robustness and security compared to state-of-the-art watermarking schemes. With a better marginal utility, ChainMarks provides a higher probability guarantee of watermark presence in DNN models with the same level of watermark accuracy.
R^3-VQA: "Read the Room" by Video Social Reasoning
May 07, 2025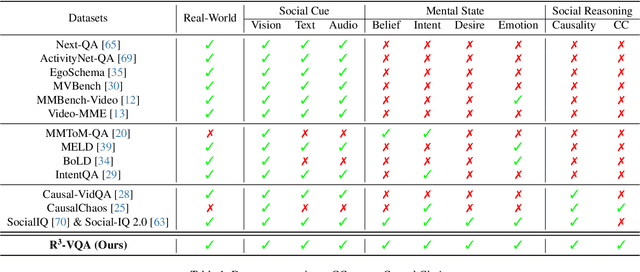
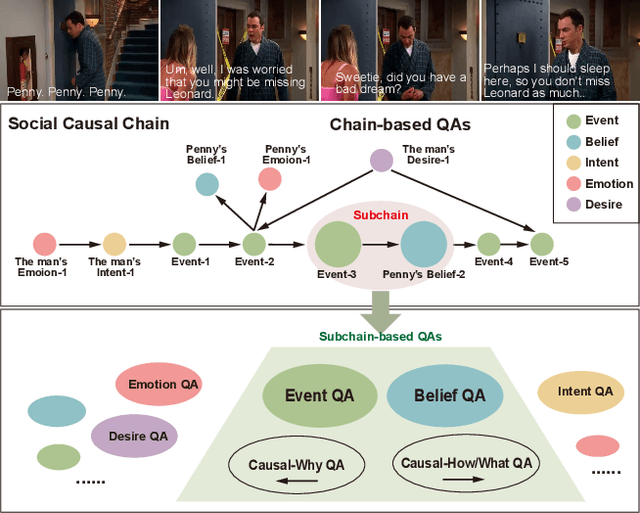
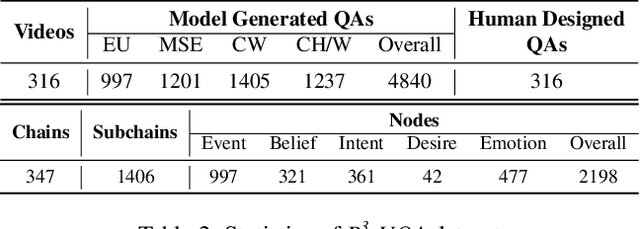

"Read the room" is a significant social reasoning capability in human daily life. Humans can infer others' mental states from subtle social cues. Previous social reasoning tasks and datasets lack complexity (e.g., simple scenes, basic interactions, incomplete mental state variables, single-step reasoning, etc.) and fall far short of the challenges present in real-life social interactions. In this paper, we contribute a valuable, high-quality, and comprehensive video dataset named R^3-VQA with precise and fine-grained annotations of social events and mental states (i.e., belief, intent, desire, and emotion) as well as corresponding social causal chains in complex social scenarios. Moreover, we include human-annotated and model-generated QAs. Our task R^3-VQA includes three aspects: Social Event Understanding, Mental State Estimation, and Social Causal Reasoning. As a benchmark, we comprehensively evaluate the social reasoning capabilities and consistencies of current state-of-the-art large vision-language models (LVLMs). Comprehensive experiments show that (i) LVLMs are still far from human-level consistent social reasoning in complex social scenarios; (ii) Theory of Mind (ToM) prompting can help LVLMs perform better on social reasoning tasks. We provide some of our dataset and codes in supplementary material and will release our full dataset and codes upon acceptance.
DMPT: Decoupled Modality-aware Prompt Tuning for Multi-modal Object Re-identification
Apr 15, 2025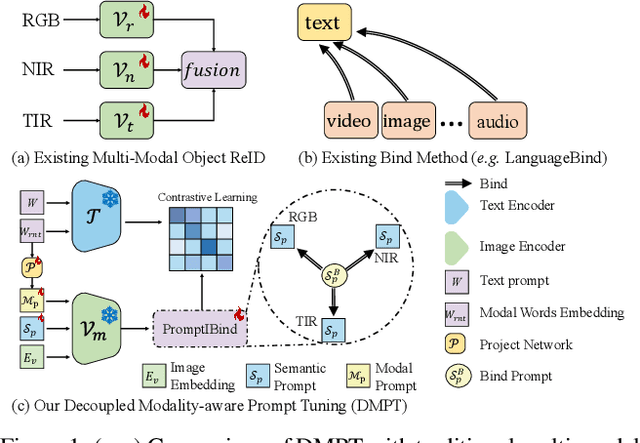
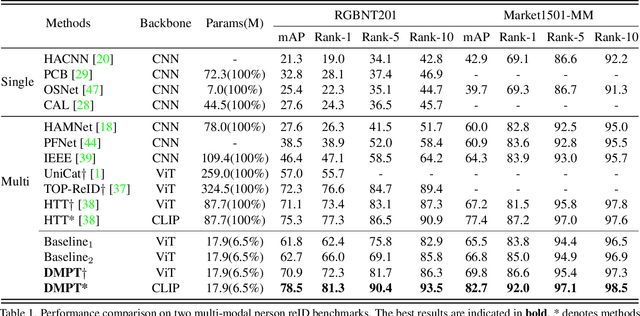
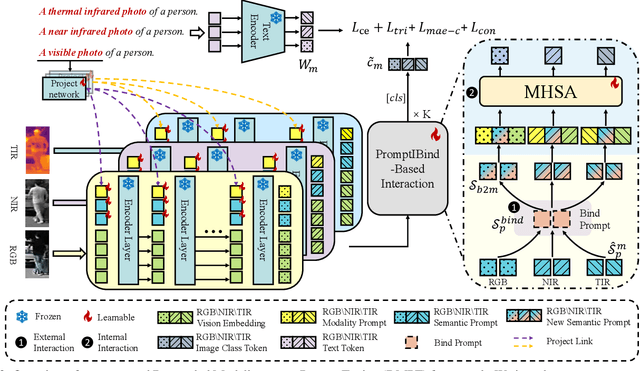
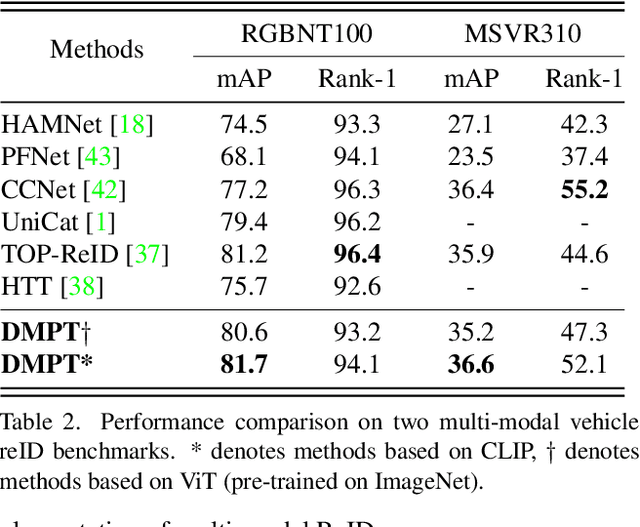
Current multi-modal object re-identification approaches based on large-scale pre-trained backbones (i.e., ViT) have displayed remarkable progress and achieved excellent performance. However, these methods usually adopt the standard full fine-tuning paradigm, which requires the optimization of considerable backbone parameters, causing extensive computational and storage requirements. In this work, we propose an efficient prompt-tuning framework tailored for multi-modal object re-identification, dubbed DMPT, which freezes the main backbone and only optimizes several newly added decoupled modality-aware parameters. Specifically, we explicitly decouple the visual prompts into modality-specific prompts which leverage prior modality knowledge from a powerful text encoder and modality-independent semantic prompts which extract semantic information from multi-modal inputs, such as visible, near-infrared, and thermal-infrared. Built upon the extracted features, we further design a Prompt Inverse Bind (PromptIBind) strategy that employs bind prompts as a medium to connect the semantic prompt tokens of different modalities and facilitates the exchange of complementary multi-modal information, boosting final re-identification results. Experimental results on multiple common benchmarks demonstrate that our DMPT can achieve competitive results to existing state-of-the-art methods while requiring only 6.5% fine-tuning of the backbone parameters.