 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-field Beam Training under Multi-path Channels: A Hybrid Learning-and-Optimization Approach
Mar 26, 2026For extremely large-scale arrays (XL-arrays), the discrete Fourier transform (DFT) codebook, conventionally used in the far-field, has recently been employed for near-field beam training. However, most existing methods rely on the line-of-sight (LoS) dominant channel assumption, which may suffer degraded communication performance when applied to the general multi-path scenario due to the more complex received signal power pattern at the user. To address this issue, we propose in this paper a new hybrid learning-and-optimization-based beam training method that first leverages deep learning (DL) to obtain coarse channel parameter estimates, and then refines them via a model-based optimization algorithm, hence achieving high-accuracy estimation with low computational complexity. Specifically, in the first stage, a tailored U-Net architecture is developed to learn the non-linear mapping from the received power pattern to coarse estimates of the angles and ranges of multi-path components. In particular, the inherent permutation ambiguity in multi-path parameter matching is effectively resolved by a permutation invariant training (PIT) strategy, while the unknown number of paths is estimated based on defined path existence logits. In the second stage, we further propose an efficient particle swarm optimization method to refine the angular and range parameters within a confined search region; in the meanwhile, a Gerchberg-Saxton algorithm is used to retrieve multi-path channel gains from the received power pattern. Last, numerical results demonstrate that the proposed hybrid design significantly outperforms various benchmarks in terms of parameter estimation accuracy and achievable rate, yet with low computational complexity.
StreetTree: A Large-Scale Global Benchmark for Fine-Grained Tree Species Classification
Feb 22, 2026The fine-grained classification of street trees is a crucial task for urban planning, streetscape management, and the assessment of urban ecosystem services. However, progress in this field has been significantly hindered by the lack of large-scale, geographically diverse, and publicly available benchmark datasets specifically designed for street trees. To address this critical gap, we introduce StreetTree, the world's first large-scale benchmark dataset dedicated to fine-grained street tree classification. The dataset contains over 12 million images covering more than 8,300 common street tree species, collected from urban streetscapes across 133 countries spanning five continents, and supplemented with expert-verified observational data. StreetTree poses substantial challenges for pretrained vision models under complex urban environments: high inter-species visual similarity, long-tailed natural distributions, significant intra-class variations caused by seasonal changes, and diverse imaging conditions such as lighting, occlusions from buildings, and varying camera angles. In addition, we provide a hierarchical taxonomy (order-family-genus-species) to support research in hierarchical classification and representation learning. Through extensive experiments with various visual models, we establish strong baselines and reveal the limitations of existing methods in handling such real-world complexities. We believe that StreetTree will serve as a key resource for the refined management and research of urban street trees, while also driving new advancements at the intersection of computer vision and urban science.
Near-field Target Localization: Effect of Hardware Impairments
Dec 25, 2025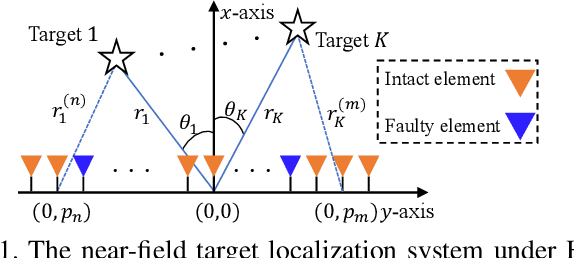
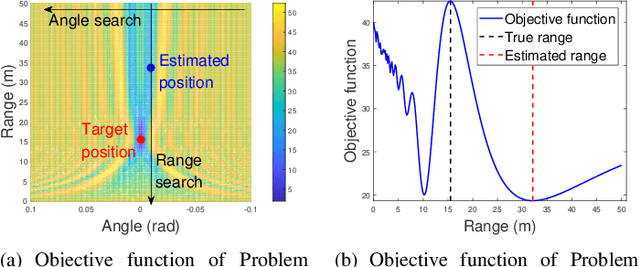
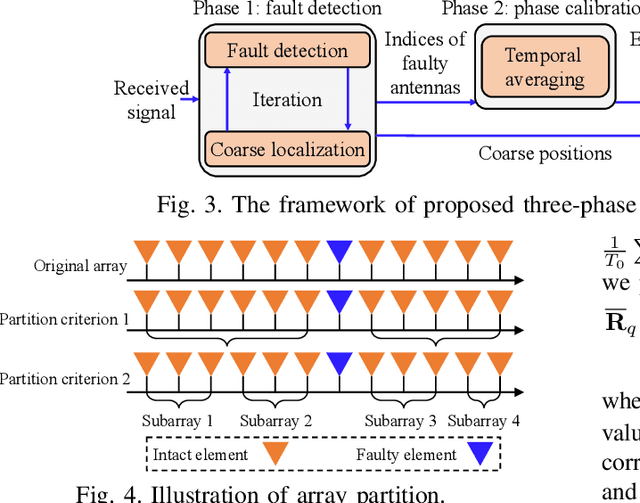
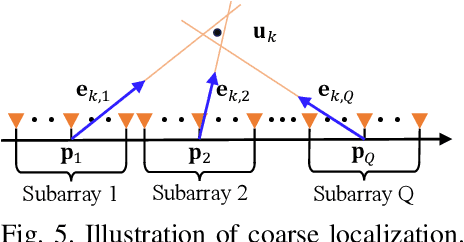
The prior works on near-field target localization have mostly assumed ideal hardware models and thus suffer from two limitations in practice. First, extremely large-scale arrays (XL-arrays) usually face a variety of hardware impairments (HIs) that may introduce unknown phase and/or amplitude errors. Second, the existing block coordinate descent (BCD)-based methods for joint estimation of the HI indicator, channel gain, angle, and range may induce considerable target localization error when the target is very close to the XL-array. To address these issues, we propose in this paper a new three-phase HI-aware near-field localization method, by efficiently detecting faulty antennas and estimating the positions of targets. Specifically, we first determine faulty antennas by using compressed sensing (CS) methods and improve detection accuracy based on coarse target localization. Then, a dedicated phase calibration method is designed to correct phase errors induced by detected faulty antennas. Subsequently, an efficient near-field localization method is devised to accurately estimate the positions of targets based on the full XL-array with phase calibration. Additionally, we resort to the misspecified Cramer-Rao bound (MCRB) to quantify the performance loss caused by HIs. Last, numerical results demonstrate that our proposed method significantly reduces the localization errors as compared to various benchmark schemes, especially for the case with a short target range and/or a high fault probability.
R^3-VQA: "Read the Room" by Video Social Reasoning
May 07, 2025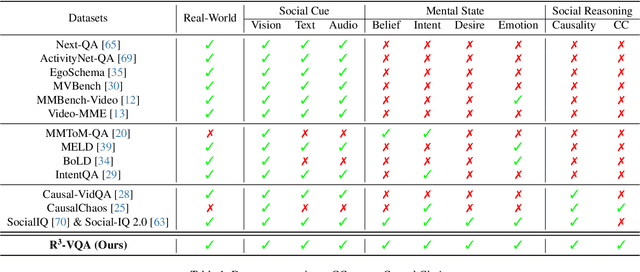
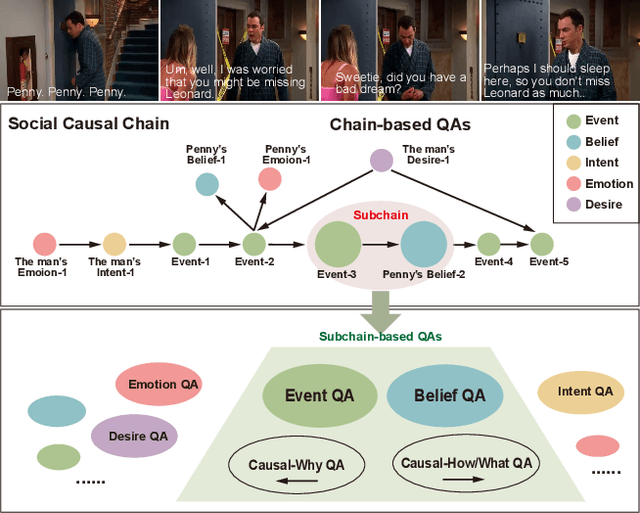
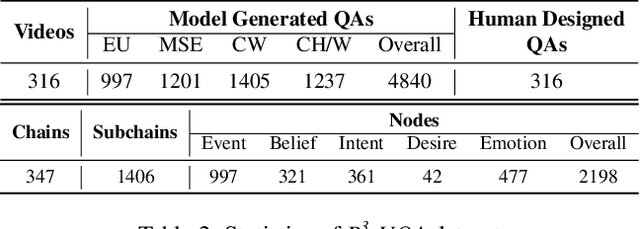

"Read the room" is a significant social reasoning capability in human daily life. Humans can infer others' mental states from subtle social cues. Previous social reasoning tasks and datasets lack complexity (e.g., simple scenes, basic interactions, incomplete mental state variables, single-step reasoning, etc.) and fall far short of the challenges present in real-life social interactions. In this paper, we contribute a valuable, high-quality, and comprehensive video dataset named R^3-VQA with precise and fine-grained annotations of social events and mental states (i.e., belief, intent, desire, and emotion) as well as corresponding social causal chains in complex social scenarios. Moreover, we include human-annotated and model-generated QAs. Our task R^3-VQA includes three aspects: Social Event Understanding, Mental State Estimation, and Social Causal Reasoning. As a benchmark, we comprehensively evaluate the social reasoning capabilities and consistencies of current state-of-the-art large vision-language models (LVLMs). Comprehensive experiments show that (i) LVLMs are still far from human-level consistent social reasoning in complex social scenarios; (ii) Theory of Mind (ToM) prompting can help LVLMs perform better on social reasoning tasks. We provide some of our dataset and codes in supplementary material and will release our full dataset and codes upon acceptance.
Unstructured Text Enhanced Open-domain Dialogue System: A Systematic Survey
Nov 14, 2024



Incorporating external knowledge into dialogue generation has been proven to benefit the performance of an open-domain Dialogue System (DS), such as generating informative or stylized responses, controlling conversation topics. In this article, we study the open-domain DS that uses unstructured text as external knowledge sources (\textbf{U}nstructured \textbf{T}ext \textbf{E}nhanced \textbf{D}ialogue \textbf{S}ystem, \textbf{UTEDS}). The existence of unstructured text entails distinctions between UTEDS and traditional data-driven DS and we aim to analyze these differences. We first give the definition of the UTEDS related concepts, then summarize the recently released datasets and models. We categorize UTEDS into Retrieval and Generative models and introduce them from the perspective of model components. The retrieval models consist of Fusion, Matching, and Ranking modules, while the generative models comprise Dialogue and Knowledge Encoding, Knowledge Selection, and Response Generation modules. We further summarize the evaluation methods utilized in UTEDS and analyze the current models' performance. At last, we discuss the future development trends of UTEDS, hoping to inspire new research in this field.
* 45 pages, 3 Figures, 11 Tables
Policy-driven Knowledge Selection and Response Generation for Document-grounded Dialogue
Oct 21, 2024

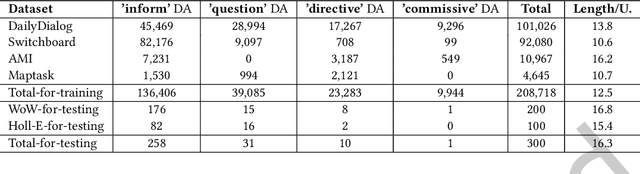

Document-grounded dialogue (DGD) uses documents as external knowledge for dialogue generation. Correctly understanding the dialogue context is crucial for selecting knowledge from the document and generating proper responses. In this paper, we propose using a dialogue policy to help the dialogue understanding in DGD. Our dialogue policy consists of two kinds of guiding signals: utterance function and topic transfer intent. The utterance function reflects the purpose and style of an utterance, and the topic transfer intent reflects the topic and content of an utterance. We propose a novel framework exploiting our dialogue policy for two core tasks in DGD, namely knowledge selection (KS) and response generation (RG). The framework consists of two modules: the Policy planner leverages policy-aware dialogue representation to select knowledge and predict the policy of the response; the generator uses policy/knowledge-aware dialogue representation for response generation. Our policy-driven model gets state-of-the-art performance on three public benchmarks and we provide a detailed analysis of the experimental results. Our code/data will be released on GitHub.
* 29 pages, 9 figures, 14 tables, TOIS 2024
KeyVideoLLM: Towards Large-scale Video Keyframe Selection
Jul 03, 2024Recently, with the rise of web videos, managing and understanding large-scale video datasets has become increasingly important. Video Large Language Models (VideoLLMs) have emerged in recent years due to their strong video understanding capabilities. However, training and inference processes for VideoLLMs demand vast amounts of data, presenting significant challenges to data management, particularly regarding efficiency, robustness, and effectiveness. In this work, we present KeyVideoLLM, a text-video frame similarity-based keyframe selection method designed to manage VideoLLM data efficiently, robustly, and effectively. Specifically, KeyVideoLLM achieves a remarkable data compression rate of up to 60.9 times, substantially lowering disk space requirements, which proves its high efficiency. Additionally, it maintains a 100% selection success rate across all video formats and scales, enhances processing speed by up to 200 times compared to existing keyframe selection methods, and does not require hyperparameter tuning. Beyond its outstanding efficiency and robustness, KeyVideoLLM further improves model performance in video question-answering tasks during both training and inference stages. Notably, it consistently achieved the state-of-the-art (SoTA) experimental results on diverse datasets.
GenderBias-\emph{VL}: Benchmarking Gender Bias in Vision Language Models via Counterfactual Probing
Jun 30, 2024Large Vision-Language Models (LVLMs) have been widely adopted in various applications; however, they exhibit significant gender biases. Existing benchmarks primarily evaluate gender bias at the demographic group level, neglecting individual fairness, which emphasizes equal treatment of similar individuals. This research gap limits the detection of discriminatory behaviors, as individual fairness offers a more granular examination of biases that group fairness may overlook. For the first time, this paper introduces the GenderBias-\emph{VL} benchmark to evaluate occupation-related gender bias in LVLMs using counterfactual visual questions under individual fairness criteria. To construct this benchmark, we first utilize text-to-image diffusion models to generate occupation images and their gender counterfactuals. Subsequently, we generate corresponding textual occupation options by identifying stereotyped occupation pairs with high semantic similarity but opposite gender proportions in real-world statistics. This method enables the creation of large-scale visual question counterfactuals to expose biases in LVLMs, applicable in both multimodal and unimodal contexts through modifying gender attributes in specific modalities. Overall, our GenderBias-\emph{VL} benchmark comprises 34,581 visual question counterfactual pairs, covering 177 occupations. Using our benchmark, we extensively evaluate 15 commonly used open-source LVLMs (\eg, LLaVA) and state-of-the-art commercial APIs, including GPT-4o and Gemini-Pro. Our findings reveal widespread gender biases in existing LVLMs. Our benchmark offers: (1) a comprehensive dataset for occupation-related gender bias evaluation; (2) an up-to-date leaderboard on LVLM biases; and (3) a nuanced understanding of the biases presented by these models. \footnote{The dataset and code are available at the \href{https://genderbiasvl.github.io/}{website}.}
Networked Integrated Sensing and Communications for 6G Wireless Systems
May 26, 2024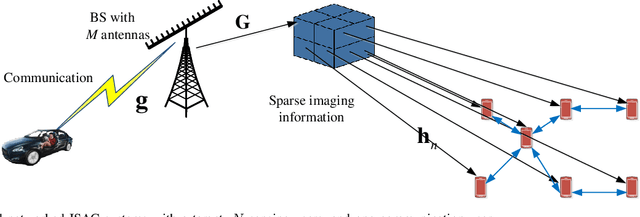
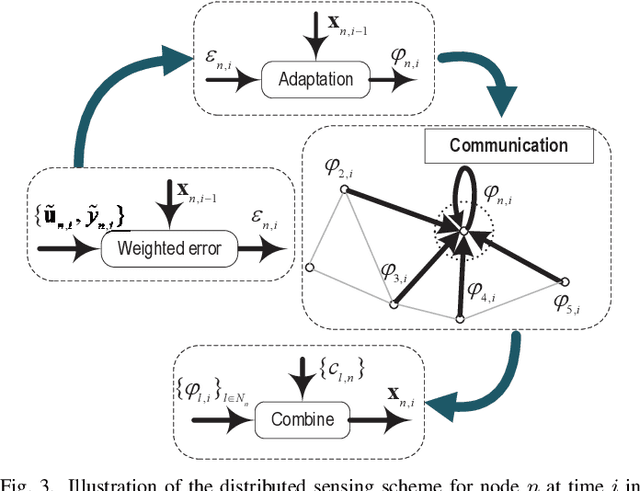
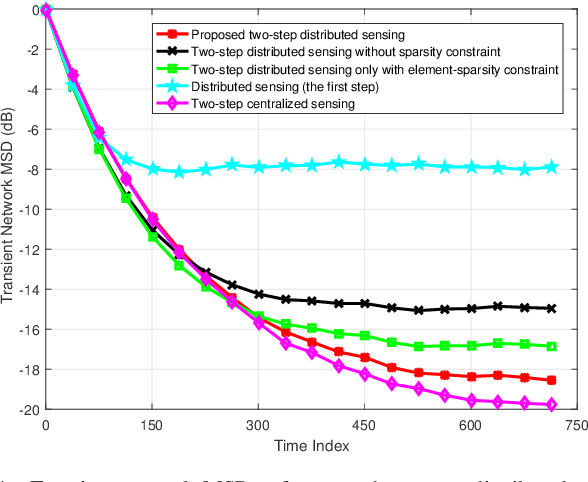
Integrated sensing and communication (ISAC) is envisioned as a key pillar for enabling the upcoming sixth generation (6G) communication systems, requiring not only reliable communication functionalities but also highly accurate environmental sensing capabilities. In this paper, we design a novel networked ISAC framework to explore the collaboration among multiple users for environmental sensing. Specifically, multiple users can serve as powerful sensors, capturing back scattered signals from a target at various angles to facilitate reliable computational imaging. Centralized sensing approaches are extremely sensitive to the capability of the leader node because it requires the leader node to process the signals sent by all the users. To this end, we propose a two-step distributed cooperative sensing algorithm that allows low-dimensional intermediate estimate exchange among neighboring users, thus eliminating the reliance on the centralized leader node and improving the robustness of sensing. This way, multiple users can cooperatively sense a target by exploiting the block-wise environment sparsity and the interference cancellation technique. Furthermore, we analyze the mean square error of the proposed distributed algorithm as a networked sensing performance metric and propose a beamforming design for the proposed network ISAC scheme to maximize the networked sensing accuracy and communication performance subject to a transmit power constraint. Simulation results validate the effectiveness of the proposed algorithm compared with the state-of-the-art algorithms.
Evaluating and Modeling Social Intelligence: A Comparative Study of Human and AI Capabilities
May 20, 2024



Facing the current debate on whether Large Language Models (LLMs) attain near-human intelligence levels (Mitchell & Krakauer, 2023; Bubeck et al., 2023; Kosinski, 2023; Shiffrin & Mitchell, 2023; Ullman, 2023), the current study introduces a benchmark for evaluating social intelligence, one of the most distinctive aspects of human cognition. We developed a comprehensive theoretical framework for social dynamics and introduced two evaluation tasks: Inverse Reasoning (IR) and Inverse Inverse Planning (IIP). Our approach also encompassed a computational model based on recursive Bayesian inference, adept at elucidating diverse human behavioral patterns. Extensive experiments and detailed analyses revealed that humans surpassed the latest GPT models in overall performance, zero-shot learning, one-shot generalization, and adaptability to multi-modalities. Notably, GPT models demonstrated social intelligence only at the most basic order (order = 0), in stark contrast to human social intelligence (order >= 2). Further examination indicated a propensity of LLMs to rely on pattern recognition for shortcuts, casting doubt on their possession of authentic human-level social intelligence. Our codes, dataset, appendix and human data are released at https://github.com/bigai-ai/Evaluate-n-Model-Social-Intelligence.