 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerialVLA: A Vision-Language-Action Model for UAV Navigation via Minimalist End-to-End Control
Mar 15, 2026Vision-Language Navigation (VLN) for Unmanned Aerial Vehicles (UAVs) demands complex visual interpretation and continuous control in dynamic 3D environments. Existing hierarchical approaches rely on dense oracle guidance or auxiliary object detectors, creating semantic gaps and limiting genuine autonomy. We propose AerialVLA, a minimalist end-to-end Vision-Language-Action framework mapping raw visual observations and fuzzy linguistic instructions directly to continuous physical control signals. First, we introduce a streamlined dual-view perception strategy that reduces visual redundancy while preserving essential cues for forward navigation and precise grounding, which additionally facilitates future simulation-to-reality transfer. To reclaim genuine autonomy, we deploy a fuzzy directional prompting mechanism derived solely from onboard sensors, completely eliminating the dependency on dense oracle guidance. Ultimately, we formulate a unified control space that integrates continuous 3-Degree-of-Freedom (3-DoF) kinematic commands with an intrinsic landing signal, freeing the agent from external object detectors for precision landing. Extensive experiments on the TravelUAV benchmark demonstrate that AerialVLA achieves state-of-the-art performance in seen environments. Furthermore, it exhibits superior generalization in unseen scenarios by achieving nearly three times the success rate of leading baselines, validating that a minimalist, autonomy-centric paradigm captures more robust visual-motor representations than complex modular systems.
Bringing RGB and IR Together: Hierarchical Multi-Modal Enhancement for Robust Transmission Line Detection
Jan 25, 2025Ensuring a stable power supply in rural areas relies heavily on effective inspection of power equipment, particularly transmission lines (TLs). However, detecting TLs from aerial imagery can be challenging when dealing with misalignments between visible light (RGB) and infrared (IR) images, as well as mismatched high- and low-level features in convolutional networks. To address these limitations, we propose a novel Hierarchical Multi-Modal Enhancement Network (HMMEN) that integrates RGB and IR data for robust and accurate TL detection. Our method introduces two key components: (1) a Mutual Multi-Modal Enhanced Block (MMEB), which fuses and enhances hierarchical RGB and IR feature maps in a coarse-to-fine manner, and (2) a Feature Alignment Block (FAB) that corrects misalignments between decoder outputs and IR feature maps by leveraging deformable convolutions. We employ MobileNet-based encoders for both RGB and IR inputs to accommodate edge-computing constraints and reduce computational overhead. Experimental results on diverse weather and lighting conditionsfog, night, snow, and daytimedemonstrate the superiority and robustness of our approach compared to state-of-the-art methods, resulting in fewer false positives, enhanced boundary delineation, and better overall detection performance. This framework thus shows promise for practical large-scale power line inspections with unmanned aerial vehicles.
Networked Integrated Sensing and Communications for 6G Wireless Systems
May 26, 2024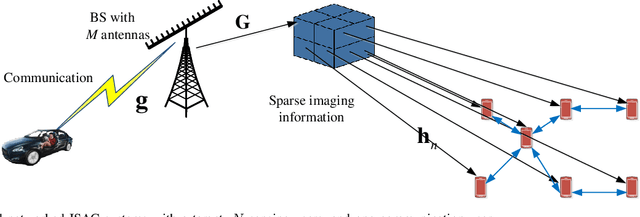
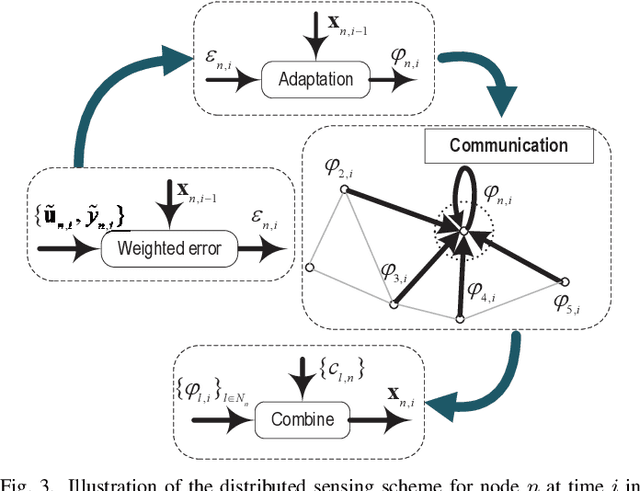
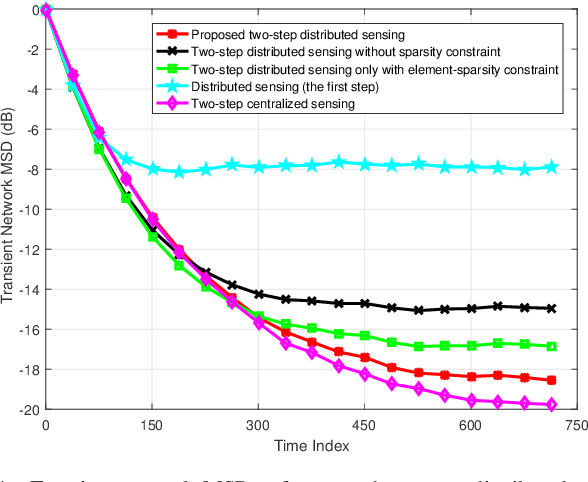
Integrated sensing and communication (ISAC) is envisioned as a key pillar for enabling the upcoming sixth generation (6G) communication systems, requiring not only reliable communication functionalities but also highly accurate environmental sensing capabilities. In this paper, we design a novel networked ISAC framework to explore the collaboration among multiple users for environmental sensing. Specifically, multiple users can serve as powerful sensors, capturing back scattered signals from a target at various angles to facilitate reliable computational imaging. Centralized sensing approaches are extremely sensitive to the capability of the leader node because it requires the leader node to process the signals sent by all the users. To this end, we propose a two-step distributed cooperative sensing algorithm that allows low-dimensional intermediate estimate exchange among neighboring users, thus eliminating the reliance on the centralized leader node and improving the robustness of sensing. This way, multiple users can cooperatively sense a target by exploiting the block-wise environment sparsity and the interference cancellation technique. Furthermore, we analyze the mean square error of the proposed distributed algorithm as a networked sensing performance metric and propose a beamforming design for the proposed network ISAC scheme to maximize the networked sensing accuracy and communication performance subject to a transmit power constraint. Simulation results validate the effectiveness of the proposed algorithm compared with the state-of-the-art algorithms.
Multi-modal Instance Refinement for Cross-domain Action Recognition
Nov 24, 2023
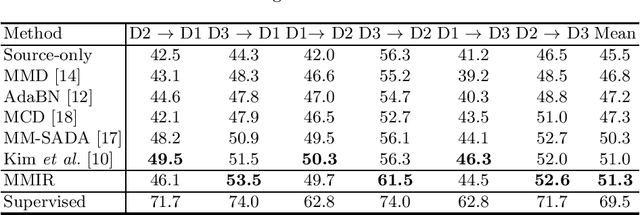


Unsupervised cross-domain action recognition aims at adapting the model trained on an existing labeled source domain to a new unlabeled target domain. Most existing methods solve the task by directly aligning the feature distributions of source and target domains. However, this would cause negative transfer during domain adaptation due to some negative training samples in both domains. In the source domain, some training samples are of low-relevance to target domain due to the difference in viewpoints, action styles, etc. In the target domain, there are some ambiguous training samples that can be easily classified as another type of action under the case of source domain. The problem of negative transfer has been explored in cross-domain object detection, while it remains under-explored in cross-domain action recognition. Therefore, we propose a Multi-modal Instance Refinement (MMIR) method to alleviate the negative transfer based on reinforcement learning. Specifically, a reinforcement learning agent is trained in both domains for every modality to refine the training data by selecting out negative samples from each domain. Our method finally outperforms several other state-of-the-art baselines in cross-domain action recognition on the benchmark EPIC-Kitchens dataset, which demonstrates the advantage of MMIR in reducing negative transfer.
Incremental Few-Shot Semantic Segmentation via Embedding Adaptive-Update and Hyper-class Representation
Jul 26, 2022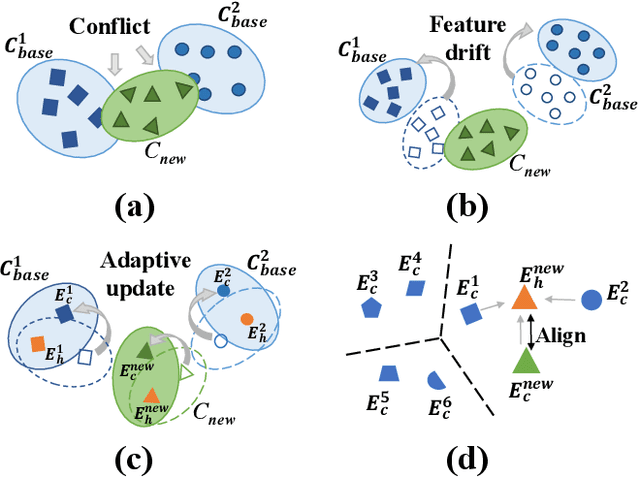

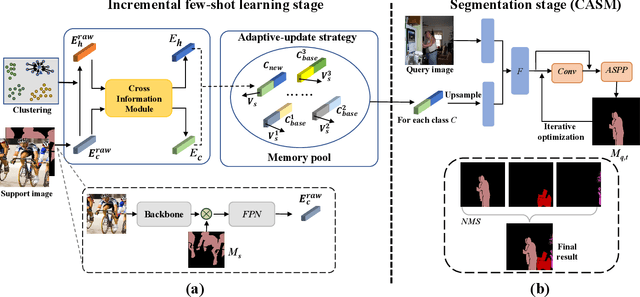

Incremental few-shot semantic segmentation (IFSS) targets at incrementally expanding model's capacity to segment new class of images supervised by only a few samples. However, features learned on old classes could significantly drift, causing catastrophic forgetting. Moreover, few samples for pixel-level segmentation on new classes lead to notorious overfitting issues in each learning session. In this paper, we explicitly represent class-based knowledge for semantic segmentation as a category embedding and a hyper-class embedding, where the former describes exclusive semantical properties, and the latter expresses hyper-class knowledge as class-shared semantic properties. Aiming to solve IFSS problems, we present EHNet, i.e., Embedding adaptive-update and Hyper-class representation Network from two aspects. First, we propose an embedding adaptive-update strategy to avoid feature drift, which maintains old knowledge by hyper-class representation, and adaptively update category embeddings with a class-attention scheme to involve new classes learned in individual sessions. Second, to resist overfitting issues caused by few training samples, a hyper-class embedding is learned by clustering all category embeddings for initialization and aligned with category embedding of the new class for enhancement, where learned knowledge assists to learn new knowledge, thus alleviating performance dependence on training data scale. Significantly, these two designs provide representation capability for classes with sufficient semantics and limited biases, enabling to perform segmentation tasks requiring high semantic dependence. Experiments on PASCAL-5i and COCO datasets show that EHNet achieves new state-of-the-art performance with remarkable advantages.
Deep Image: A precious image based deep learning method for online malware detection in IoT Environment
Apr 04, 2022
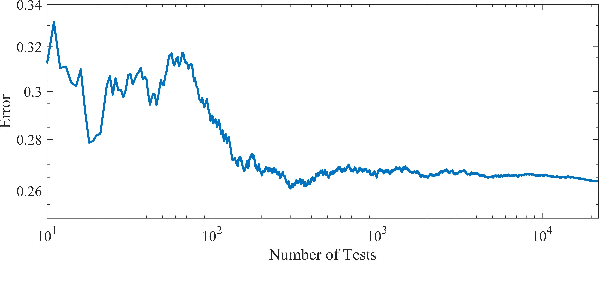
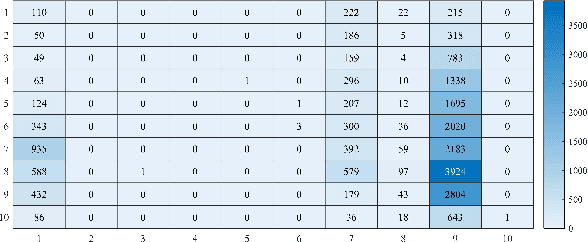
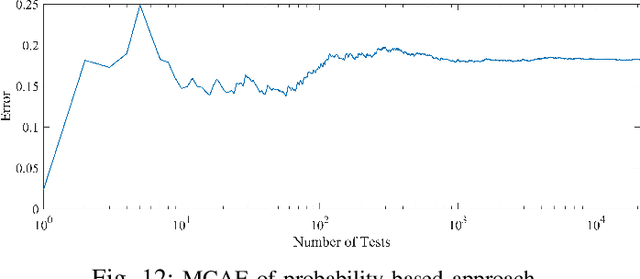
The volume of malware and the number of attacks in IoT devices are rising everyday, which encourages security professionals to continually enhance their malware analysis tools. Researchers in the field of cyber security have extensively explored the usage of sophisticated analytics and the efficiency of malware detection. With the introduction of new malware kinds and attack routes, security experts confront considerable challenges in developing efficient malware detection and analysis solutions. In this paper, a different view of malware analysis is considered and the risk level of each sample feature is computed, and based on that the risk level of that sample is calculated. In this way, a criterion is introduced that is used together with accuracy and FPR criteria for malware analysis in IoT environment. In this paper, three malware detection methods based on visualization techniques called the clustering approach, the probabilistic approach, and the deep learning approach are proposed. Then, in addition to the usual machine learning criteria namely accuracy and FPR, a proposed criterion based on the risk of samples has also been used for comparison, with the results showing that the deep learning approach performed better in detecting malware
Large Scale Global Optimization Algorithms for IoT Networks: A Comparative Study
Feb 22, 2021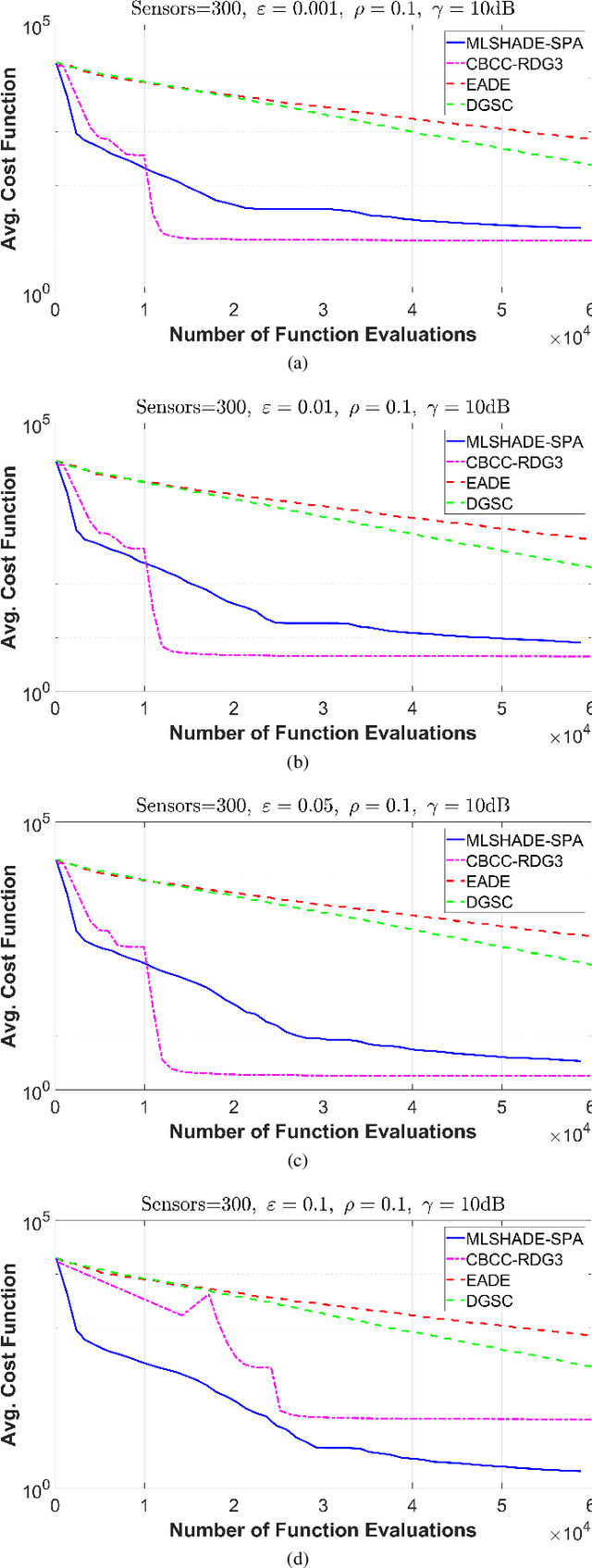
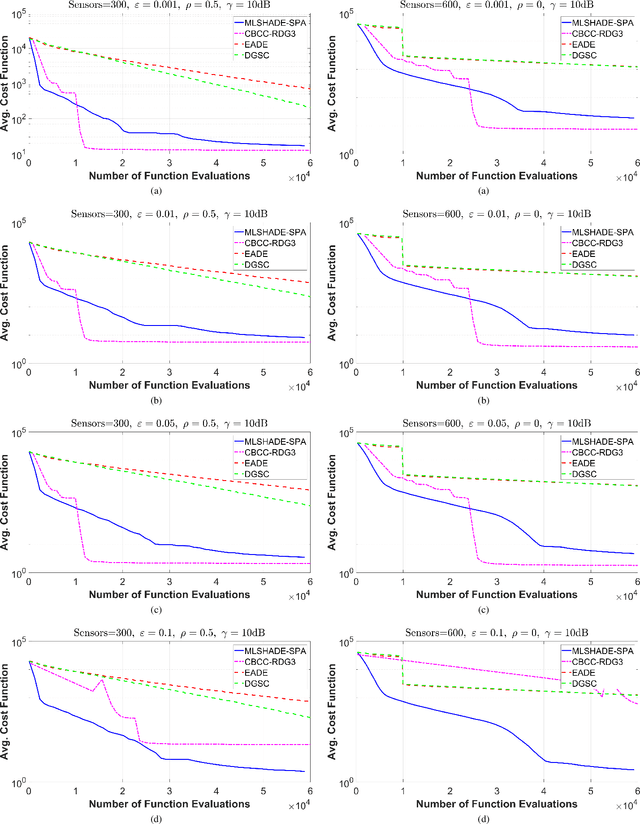
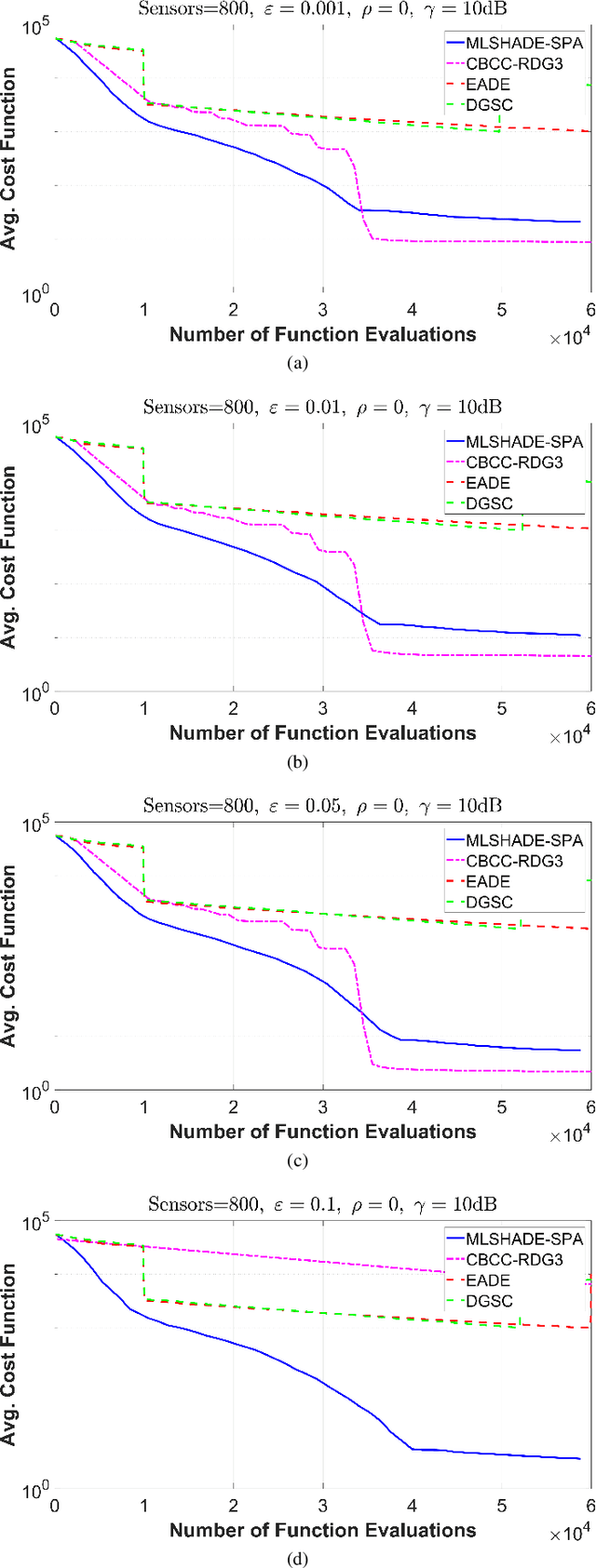
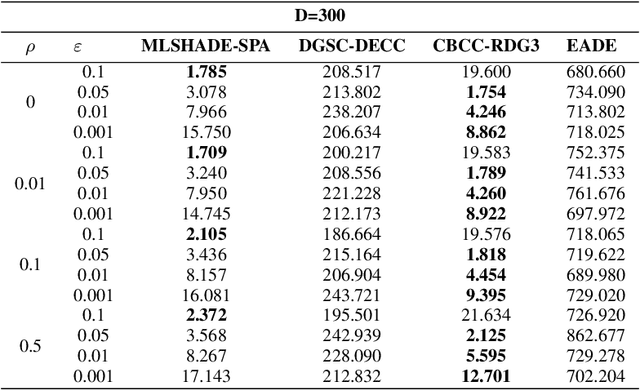
The advent of Internet of Things (IoT) has bring a new era in communication technology by expanding the current inter-networking services and enabling the machine-to-machine communication. IoT massive deployments will create the problem of optimal power allocation. The objective of the optimization problem is to obtain a feasible solution that minimizes the total power consumption of the WSN, when the error probability at the fusion center meets certain criteria. This work studies the optimization of a wireless sensor network (WNS) at higher dimensions by focusing to the power allocation of decentralized detection. More specifically, we apply and compare four algorithms designed to tackle Large scale global optimization (LGSO) problems. These are the memetic linear population size reduction and semi-parameter adaptation (MLSHADE-SPA), the contribution-based cooperative coevolution recursive differential grouping (CBCC-RDG3), the differential grouping with spectral clustering-differential evolution cooperative coevolution (DGSC-DECC), and the enhanced adaptive differential evolution (EADE). To the best of the authors knowledge, this is the first time that LGSO algorithms are applied to the optimal power allocation problem in IoT networks. We evaluate the algorithms performance in several different cases by applying them in cases with 300, 600 and 800 dimensions.
Perceptual Image Super-Resolution with Progressive Adversarial Network
Mar 19, 2020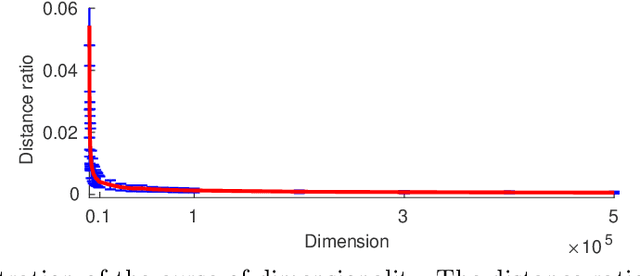
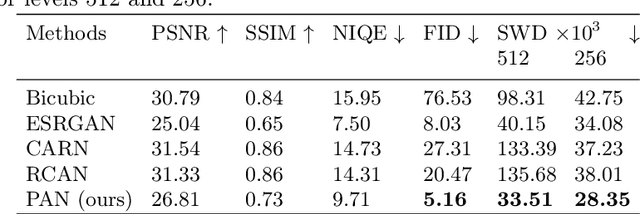
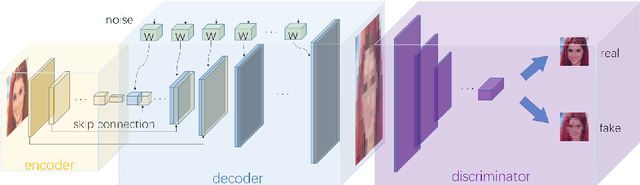
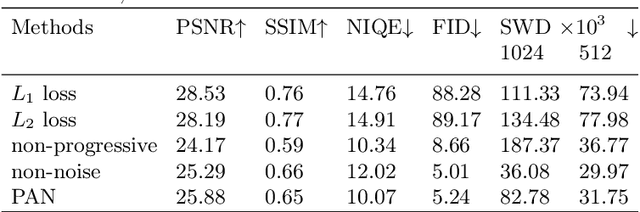
Single Image Super-Resolution (SISR) aims to improve resolution of small-size low-quality image from a single one. With popularity of consumer electronics in our daily life, this topic has become more and more attractive. In this paper, we argue that the curse of dimensionality is the underlying reason of limiting the performance of state-of-the-art algorithms. To address this issue, we propose Progressive Adversarial Network (PAN) that is capable of coping with this difficulty for domain-specific image super-resolution. The key principle of PAN is that we do not apply any distance-based reconstruction errors as the loss to be optimized, thus free from the restriction of the curse of dimensionality. To maintain faithful reconstruction precision, we resort to U-Net and progressive growing of neural architecture. The low-level features in encoder can be transferred into decoder to enhance textural details with U-Net. Progressive growing enhances image resolution gradually, thereby preserving precision of recovered image. Moreover, to obtain high-fidelity outputs, we leverage the framework of the powerful StyleGAN to perform adversarial learning. Without the curse of dimensionality, our model can super-resolve large-size images with remarkable photo-realistic details and few distortions. Extensive experiments demonstrate the superiority of our algorithm over state-of-the-arts both quantitatively and qualitatively.
A Matrix-in-matrix Neural Network for Image Super Resolution
Mar 19, 2019
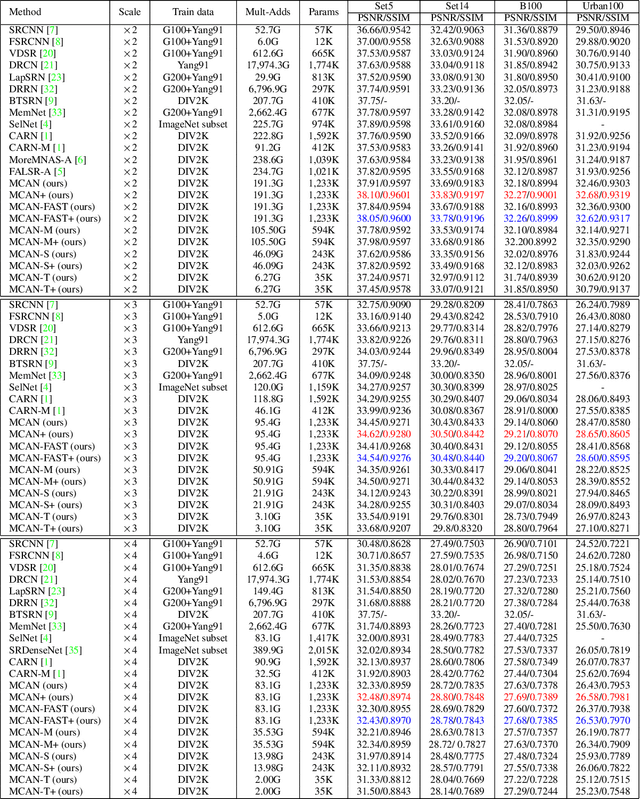
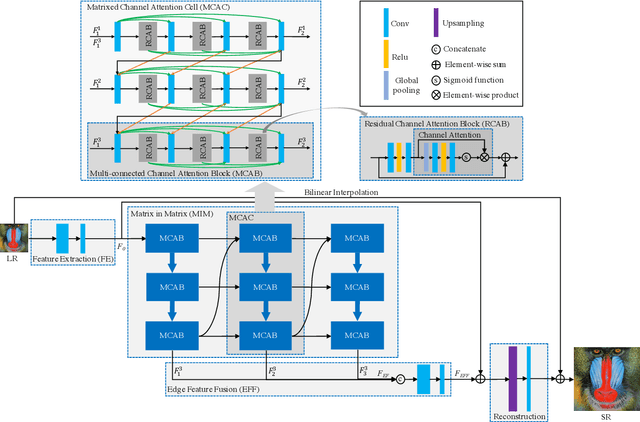
In recent years, deep learning methods have achieved impressive results with higher peak signal-to-noise ratio in single image super-resolution (SISR) tasks by utilizing deeper layers. However, their application is quite limited since they require high computing power. In addition, most of the existing methods rarely take full advantage of the intermediate features which are helpful for restoration. To address these issues, we propose a moderate-size SISR net work named matrixed channel attention network (MCAN) by constructing a matrix ensemble of multi-connected channel attention blocks (MCAB). Several models of different sizes are released to meet various practical requirements. Conclusions can be drawn from our extensive benchmark experiments that the proposed models achieve better performance with much fewer multiply-adds and parameters. Our models will be made publicly available.
Bootstrapping Face Detection with Hard Negative Examples
Aug 07, 2016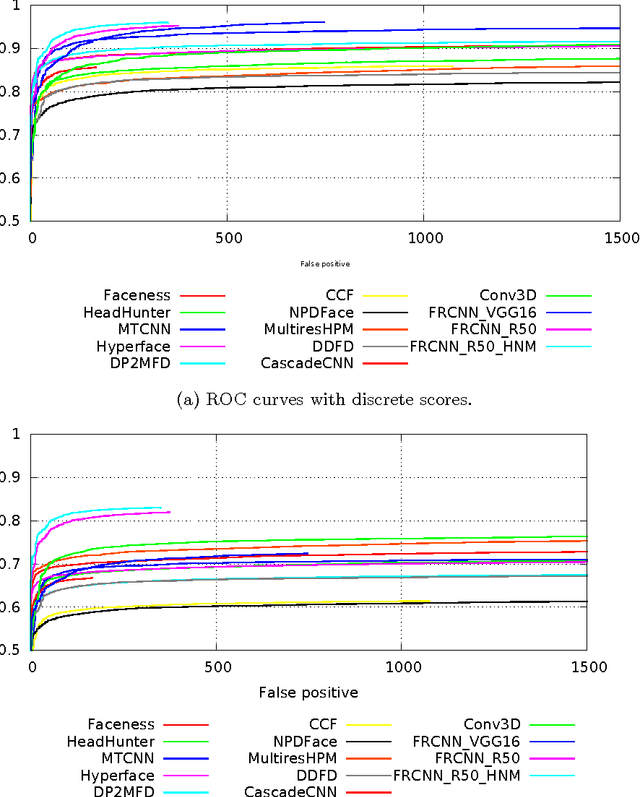
Recently significant performance improvement in face detection was made possible by deeply trained convolutional networks. In this report, a novel approach for training state-of-the-art face detector is described. The key is to exploit the idea of hard negative mining and iteratively update the Faster R-CNN based face detector with the hard negatives harvested from a large set of background examples. We demonstrate that our face detector outperforms state-of-the-art detectors on the FDDB dataset, which is the de facto standard for evaluating face detection algorithms.