 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMFuser: Multimodal Multi-Layer Feature Fuser for Fine-Grained Vision-Language Understanding
Oct 15, 2024
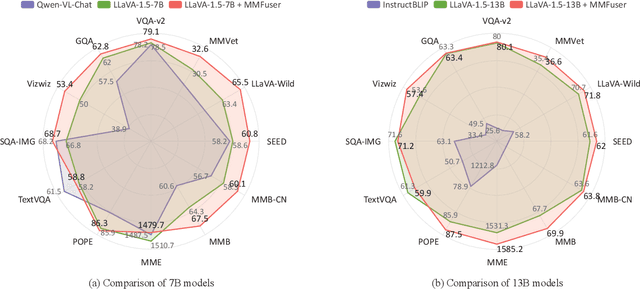
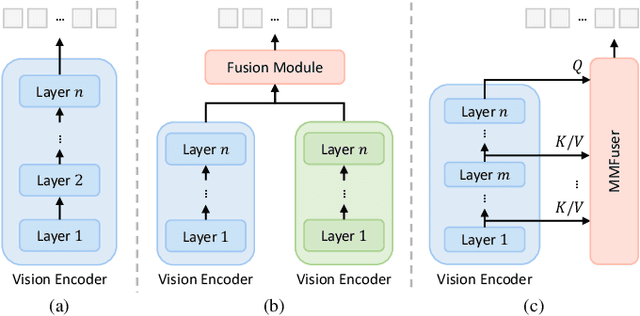
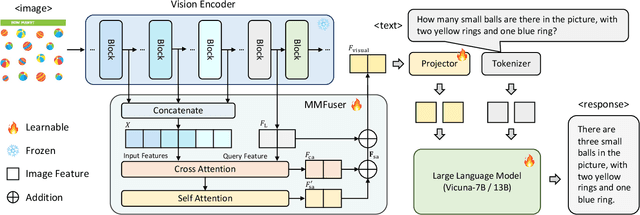
Despite significant advancements in Multimodal Large Language Models (MLLMs) for understanding complex human intentions through cross-modal interactions, capturing intricate image details remains challenging. Previous methods integrating multiple vision encoders to enhance visual detail introduce redundancy and computational overhead. We observe that most MLLMs utilize only the last-layer feature map of the vision encoder for visual representation, neglecting the rich fine-grained information in shallow feature maps. To address this issue, we propose \modelname, a simple yet effective multi-layer feature fuser that efficiently integrates deep and shallow features from Vision Transformers (ViTs). Specifically, it leverages semantically aligned deep features as queries to dynamically extract missing details from shallow features, thus preserving semantic alignment while enriching the representation with fine-grained information. Applied to the LLaVA-1.5 model, \modelname~achieves significant improvements in visual representation and benchmark performance, providing a more flexible and lightweight solution compared to multi-encoder ensemble methods. The code and model have been released at https://github.com/yuecao0119/MMFuser.
Incremental Few-Shot Semantic Segmentation via Embedding Adaptive-Update and Hyper-class Representation
Jul 26, 2022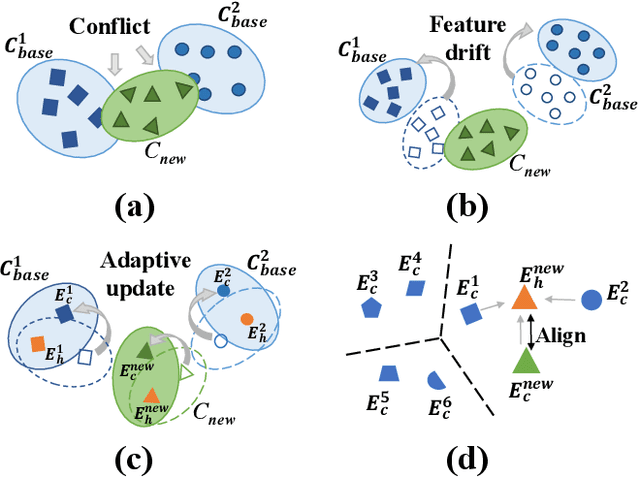

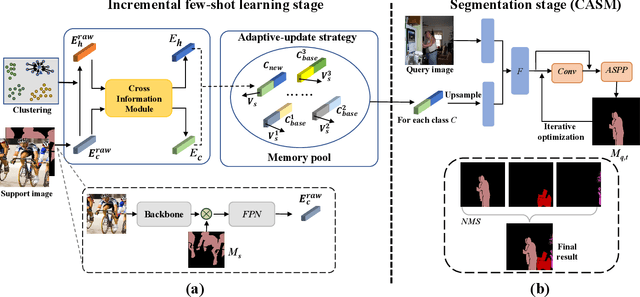

Incremental few-shot semantic segmentation (IFSS) targets at incrementally expanding model's capacity to segment new class of images supervised by only a few samples. However, features learned on old classes could significantly drift, causing catastrophic forgetting. Moreover, few samples for pixel-level segmentation on new classes lead to notorious overfitting issues in each learning session. In this paper, we explicitly represent class-based knowledge for semantic segmentation as a category embedding and a hyper-class embedding, where the former describes exclusive semantical properties, and the latter expresses hyper-class knowledge as class-shared semantic properties. Aiming to solve IFSS problems, we present EHNet, i.e., Embedding adaptive-update and Hyper-class representation Network from two aspects. First, we propose an embedding adaptive-update strategy to avoid feature drift, which maintains old knowledge by hyper-class representation, and adaptively update category embeddings with a class-attention scheme to involve new classes learned in individual sessions. Second, to resist overfitting issues caused by few training samples, a hyper-class embedding is learned by clustering all category embeddings for initialization and aligned with category embedding of the new class for enhancement, where learned knowledge assists to learn new knowledge, thus alleviating performance dependence on training data scale. Significantly, these two designs provide representation capability for classes with sufficient semantics and limited biases, enabling to perform segmentation tasks requiring high semantic dependence. Experiments on PASCAL-5i and COCO datasets show that EHNet achieves new state-of-the-art performance with remarkable advantages.