 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrMoE: Mixture of Experts with De-stylization Learning for Cross-Scene and Cross-Domain Correspondence Pruning
Jul 16, 2025Establishing reliable correspondences between image pairs is a fundamental task in computer vision, underpinning applications such as 3D reconstruction and visual localization. Although recent methods have made progress in pruning outliers from dense correspondence sets, they often hypothesize consistent visual domains and overlook the challenges posed by diverse scene structures. In this paper, we propose CorrMoE, a novel correspondence pruning framework that enhances robustness under cross-domain and cross-scene variations. To address domain shift, we introduce a De-stylization Dual Branch, performing style mixing on both implicit and explicit graph features to mitigate the adverse influence of domain-specific representations. For scene diversity, we design a Bi-Fusion Mixture of Experts module that adaptively integrates multi-perspective features through linear-complexity attention and dynamic expert routing. Extensive experiments on benchmark datasets demonstrate that CorrMoE achieves superior accuracy and generalization compared to state-of-the-art methods. The code and pre-trained models are available at https://github.com/peiwenxia/CorrMoE.
MMFuser: Multimodal Multi-Layer Feature Fuser for Fine-Grained Vision-Language Understanding
Oct 15, 2024
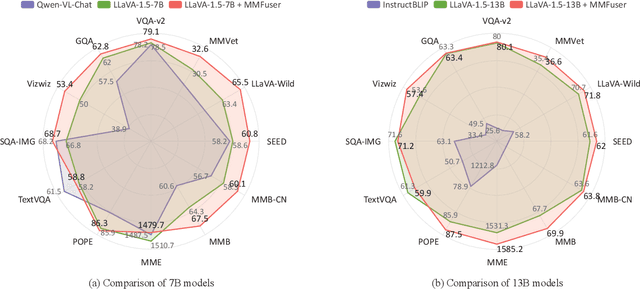
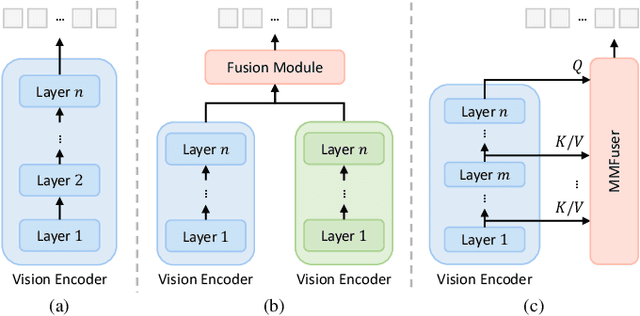
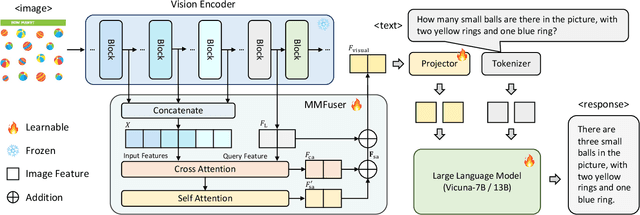
Despite significant advancements in Multimodal Large Language Models (MLLMs) for understanding complex human intentions through cross-modal interactions, capturing intricate image details remains challenging. Previous methods integrating multiple vision encoders to enhance visual detail introduce redundancy and computational overhead. We observe that most MLLMs utilize only the last-layer feature map of the vision encoder for visual representation, neglecting the rich fine-grained information in shallow feature maps. To address this issue, we propose \modelname, a simple yet effective multi-layer feature fuser that efficiently integrates deep and shallow features from Vision Transformers (ViTs). Specifically, it leverages semantically aligned deep features as queries to dynamically extract missing details from shallow features, thus preserving semantic alignment while enriching the representation with fine-grained information. Applied to the LLaVA-1.5 model, \modelname~achieves significant improvements in visual representation and benchmark performance, providing a more flexible and lightweight solution compared to multi-encoder ensemble methods. The code and model have been released at https://github.com/yuecao0119/MMFuser.