 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstroRAG -- A Pagerank-Based Retrieval-Augmented Generation Pipeline for Question Answering in Astronomy
May 24, 2026Large language models (LLMs) demonstrate strong performance in natural language processing but often generate factual errors when relying solely on parametric knowledge. Retrieval-Augmented Generation (RAG) mitigates these errors by grounding responses in external evidence, yet conventional retrieve-and-dump approaches frequently introduce irrelevant context that degrades answer quality. In this work, we present AstroRAG -- a PageRank-based retrieval-augmented generation (RAG) pipeline adapted for question answering in astronomy. The system performs token-aware chunking and per-instance, ephemeral indexing in Elasticsearch, then executes a two-stage retrieval: (i) Maximal Marginal Relevance (MMR) to obtain a small, diverse candidate set and (ii) a reader-driven PageRank (PR) re-ranking on a similarity graph to identify a compact, mutually supportive context under a strict token budget. Our design is training-free, privacy-preserving, and reproducible, as each instance is processed through transient indexing to prevent cross-task leakage. We evaluate the pipeline on the AstroQA benchmark for astronomy QA, and demonstrate competitive performance across all difficulty levels. In particular, the RAG-enhanced Mistral-7B achieves \textbf{79.49\% accuracy} and \textbf{79.49\% F1-score}, nearly doubling the performance of its non-RAG counterpart. These results highlight the effectiveness of disciplined retrieval and refinement in boosting domain-specific reasoning, establishing a robust foundation for extending RAG to other scientific fields.
Beyond VLM-Based Rewards: Diffusion-Native Latent Reward Modeling
Feb 11, 2026Preference optimization for diffusion and flow-matching models relies on reward functions that are both discriminatively robust and computationally efficient. Vision-Language Models (VLMs) have emerged as the primary reward provider, leveraging their rich multimodal priors to guide alignment. However, their computation and memory cost can be substantial, and optimizing a latent diffusion generator through a pixel-space reward introduces a domain mismatch that complicates alignment. In this paper, we propose DiNa-LRM, a diffusion-native latent reward model that formulates preference learning directly on noisy diffusion states. Our method introduces a noise-calibrated Thurstone likelihood with diffusion-noise-dependent uncertainty. DiNa-LRM leverages a pretrained latent diffusion backbone with a timestep-conditioned reward head, and supports inference-time noise ensembling, providing a diffusion-native mechanism for test-time scaling and robust rewarding. Across image alignment benchmarks, DiNa-LRM substantially outperforms existing diffusion-based reward baselines and achieves performance competitive with state-of-the-art VLMs at a fraction of the computational cost. In preference optimization, we demonstrate that DiNa-LRM improves preference optimization dynamics, enabling faster and more resource-efficient model alignment.
Fourier-RWKV: A Multi-State Perception Network for Efficient Image Dehazing
Dec 09, 2025Image dehazing is crucial for reliable visual perception, yet it remains highly challenging under real-world non-uniform haze conditions. Although Transformer-based methods excel at capturing global context, their quadratic computational complexity hinders real-time deployment. To address this, we propose Fourier Receptance Weighted Key Value (Fourier-RWKV), a novel dehazing framework based on a Multi-State Perception paradigm. The model achieves comprehensive haze degradation modeling with linear complexity by synergistically integrating three distinct perceptual states: (1) Spatial-form Perception, realized through the Deformable Quad-directional Token Shift (DQ-Shift) operation, which dynamically adjusts receptive fields to accommodate local haze variations; (2) Frequency-domain Perception, implemented within the Fourier Mix block, which extends the core WKV attention mechanism of RWKV from the spatial domain to the Fourier domain, preserving the long-range dependencies essential for global haze estimation while mitigating spatial attenuation; (3) Semantic-relation Perception, facilitated by the Semantic Bridge Module (SBM), which utilizes Dynamic Semantic Kernel Fusion (DSK-Fusion) to precisely align encoder-decoder features and suppress artifacts. Extensive experiments on multiple benchmarks demonstrate that Fourier-RWKV delivers state-of-the-art performance across diverse haze scenarios while significantly reducing computational overhead, establishing a favorable trade-off between restoration quality and practical efficiency. Code is available at: https://github.com/Dilizlr/Fourier-RWKV.
APD-Agents: A Large Language Model-Driven Multi-Agents Collaborative Framework for Automated Page Design
Nov 18, 2025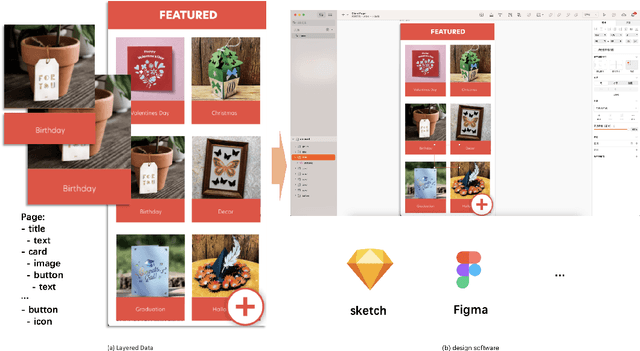
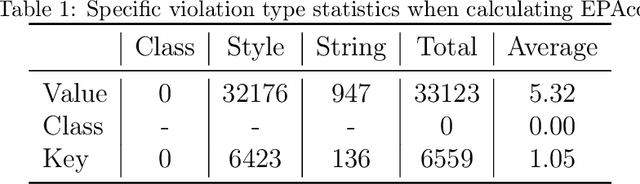
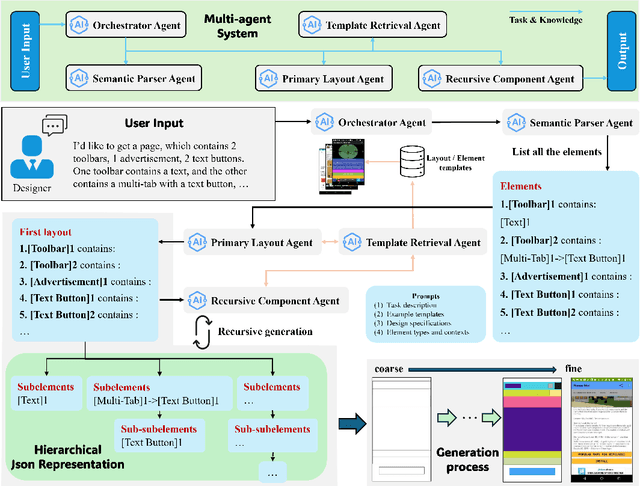
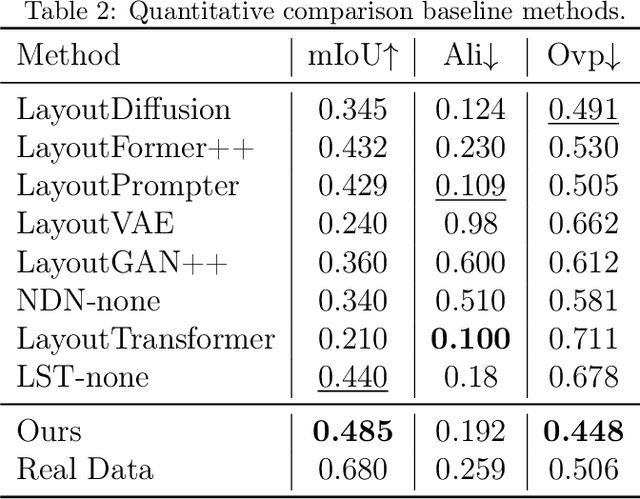
Layout design is a crucial step in developing mobile app pages. However, crafting satisfactory designs is time-intensive for designers: they need to consider which controls and content to present on the page, and then repeatedly adjust their size, position, and style for better aesthetics and structure. Although many design software can now help to perform these repetitive tasks, extensive training is needed to use them effectively. Moreover, collaborative design across app pages demands extra time to align standards and ensure consistent styling. In this work, we propose APD-agents, a large language model (LLM) driven multi-agent framework for automated page design in mobile applications. Our framework contains OrchestratorAgent, SemanticParserAgent, PrimaryLayoutAgent, TemplateRetrievalAgent, and RecursiveComponentAgent. Upon receiving the user's description of the page, the OrchestratorAgent can dynamically can direct other agents to accomplish users' design task. To be specific, the SemanticParserAgent is responsible for converting users' descriptions of page content into structured data. The PrimaryLayoutAgent can generate an initial coarse-grained layout of this page. The TemplateRetrievalAgent can fetch semantically relevant few-shot examples and enhance the quality of layout generation. Besides, a RecursiveComponentAgent can be used to decide how to recursively generate all the fine-grained sub-elements it contains for each element in the layout. Our work fully leverages the automatic collaboration capabilities of large-model-driven multi-agent systems. Experimental results on the RICO dataset show that our APD-agents achieve state-of-the-art performance.
CorrMoE: Mixture of Experts with De-stylization Learning for Cross-Scene and Cross-Domain Correspondence Pruning
Jul 16, 2025Establishing reliable correspondences between image pairs is a fundamental task in computer vision, underpinning applications such as 3D reconstruction and visual localization. Although recent methods have made progress in pruning outliers from dense correspondence sets, they often hypothesize consistent visual domains and overlook the challenges posed by diverse scene structures. In this paper, we propose CorrMoE, a novel correspondence pruning framework that enhances robustness under cross-domain and cross-scene variations. To address domain shift, we introduce a De-stylization Dual Branch, performing style mixing on both implicit and explicit graph features to mitigate the adverse influence of domain-specific representations. For scene diversity, we design a Bi-Fusion Mixture of Experts module that adaptively integrates multi-perspective features through linear-complexity attention and dynamic expert routing. Extensive experiments on benchmark datasets demonstrate that CorrMoE achieves superior accuracy and generalization compared to state-of-the-art methods. The code and pre-trained models are available at https://github.com/peiwenxia/CorrMoE.
DAM-VSR: Disentanglement of Appearance and Motion for Video Super-Resolution
Jul 01, 2025


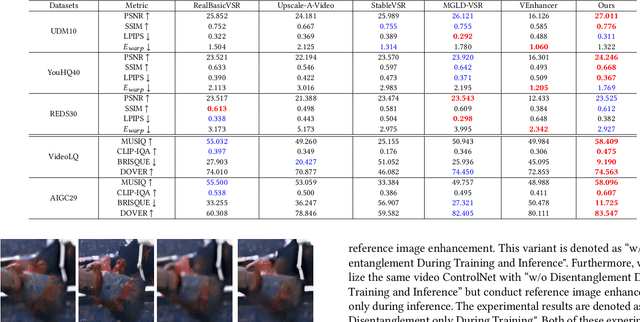
Real-world video super-resolution (VSR) presents significant challenges due to complex and unpredictable degradations. Although some recent methods utilize image diffusion models for VSR and have shown improved detail generation capabilities, they still struggle to produce temporally consistent frames. We attempt to use Stable Video Diffusion (SVD) combined with ControlNet to address this issue. However, due to the intrinsic image-animation characteristics of SVD, it is challenging to generate fine details using only low-quality videos. To tackle this problem, we propose DAM-VSR, an appearance and motion disentanglement framework for VSR. This framework disentangles VSR into appearance enhancement and motion control problems. Specifically, appearance enhancement is achieved through reference image super-resolution, while motion control is achieved through video ControlNet. This disentanglement fully leverages the generative prior of video diffusion models and the detail generation capabilities of image super-resolution models. Furthermore, equipped with the proposed motion-aligned bidirectional sampling strategy, DAM-VSR can conduct VSR on longer input videos. DAM-VSR achieves state-of-the-art performance on real-world data and AIGC data, demonstrating its powerful detail generation capabilities.
Visual and textual prompts for enhancing emotion recognition in video
Apr 24, 2025Vision Large Language Models (VLLMs) exhibit promising potential for multi-modal understanding, yet their application to video-based emotion recognition remains limited by insufficient spatial and contextual awareness. Traditional approaches, which prioritize isolated facial features, often neglect critical non-verbal cues such as body language, environmental context, and social interactions, leading to reduced robustness in real-world scenarios. To address this gap, we propose Set-of-Vision-Text Prompting (SoVTP), a novel framework that enhances zero-shot emotion recognition by integrating spatial annotations (e.g., bounding boxes, facial landmarks), physiological signals (facial action units), and contextual cues (body posture, scene dynamics, others' emotions) into a unified prompting strategy. SoVTP preserves holistic scene information while enabling fine-grained analysis of facial muscle movements and interpersonal dynamics. Extensive experiments show that SoVTP achieves substantial improvements over existing visual prompting methods, demonstrating its effectiveness in enhancing VLLMs' video emotion recognition capabilities.
MaterialMVP: Illumination-Invariant Material Generation via Multi-view PBR Diffusion
Mar 13, 2025Physically-based rendering (PBR) has become a cornerstone in modern computer graphics, enabling realistic material representation and lighting interactions in 3D scenes. In this paper, we present MaterialMVP, a novel end-to-end model for generating PBR textures from 3D meshes and image prompts, addressing key challenges in multi-view material synthesis. Our approach leverages Reference Attention to extract and encode informative latent from the input reference images, enabling intuitive and controllable texture generation. We also introduce a Consistency-Regularized Training strategy to enforce stability across varying viewpoints and illumination conditions, ensuring illumination-invariant and geometrically consistent results. Additionally, we propose Dual-Channel Material Generation, which separately optimizes albedo and metallic-roughness (MR) textures while maintaining precise spatial alignment with the input images through Multi-Channel Aligned Attention. Learnable material embeddings are further integrated to capture the distinct properties of albedo and MR. Experimental results demonstrate that our model generates PBR textures with realistic behavior across diverse lighting scenarios, outperforming existing methods in both consistency and quality for scalable 3D asset creation.
PTQ1.61: Push the Real Limit of Extremely Low-Bit Post-Training Quantization Methods for Large Language Models
Feb 18, 2025
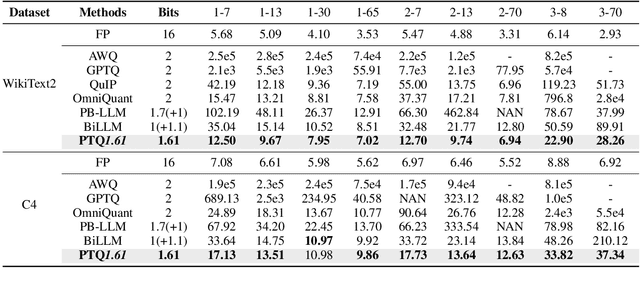
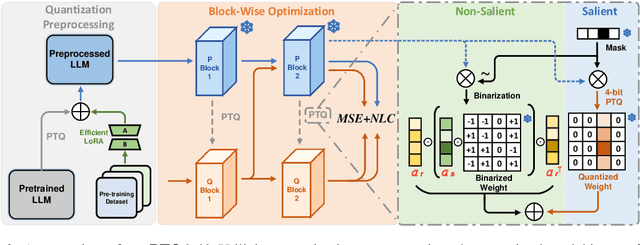
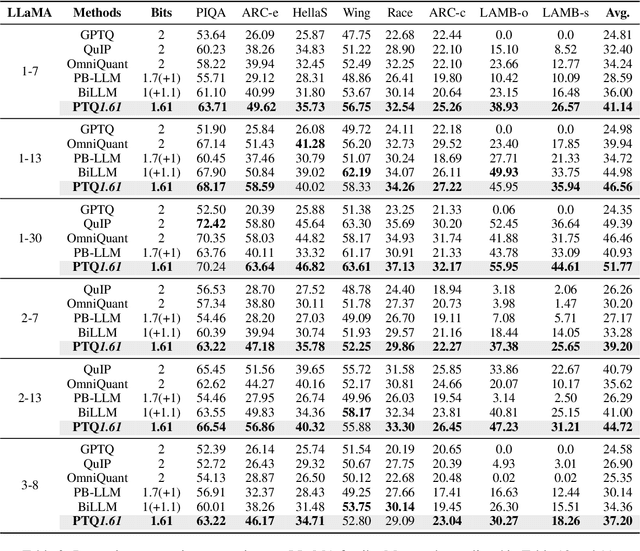
Large Language Models (LLMs) suffer severe performance degradation when facing extremely low-bit (sub 2-bit) quantization. Several existing sub 2-bit post-training quantization (PTQ) methods utilize a mix-precision scheme by leveraging an unstructured fine-grained mask to explicitly distinguish salient weights, while which introduces an extra 1-bit or more per weight. To explore the real limit of PTQ, we propose an extremely low-bit PTQ method called PTQ1.61, which enables weight quantization to 1.61-bit for the first time. Specifically, we first introduce a one-dimensional structured mask with negligibly additional 0.0002-bit per weight based on input activations from the perspective of reducing the upper bound of quantization error to allocate corresponding salient weight channels to 4-bit. For non-salient channels binarization, an efficient block-wise scaling factors optimization framework is then presented to take implicit row-wise correlations and angular biases into account. Different from prior works that concentrate on adjusting quantization methodologies, we further propose a novel paradigm called quantization preprocessing, where we argue that transforming the weight distribution of the pretrained model before quantization can alleviate the difficulty in per-channel extremely low-bit PTQ. Extensive experiments indicate our PTQ1.61 achieves state-of-the-art performance in extremely low-bit quantization. Codes are available at https://github.com/zjq0455/PTQ1.61.
MB-TaylorFormer V2: Improved Multi-branch Linear Transformer Expanded by Taylor Formula for Image Restoration
Jan 08, 2025Recently, Transformer networks have demonstrated outstanding performance in the field of image restoration due to the global receptive field and adaptability to input. However, the quadratic computational complexity of Softmax-attention poses a significant limitation on its extensive application in image restoration tasks, particularly for high-resolution images. To tackle this challenge, we propose a novel variant of the Transformer. This variant leverages the Taylor expansion to approximate the Softmax-attention and utilizes the concept of norm-preserving mapping to approximate the remainder of the first-order Taylor expansion, resulting in a linear computational complexity. Moreover, we introduce a multi-branch architecture featuring multi-scale patch embedding into the proposed Transformer, which has four distinct advantages: 1) various sizes of the receptive field; 2) multi-level semantic information; 3) flexible shapes of the receptive field; 4) accelerated training and inference speed. Hence, the proposed model, named the second version of Taylor formula expansion-based Transformer (for short MB-TaylorFormer V2) has the capability to concurrently process coarse-to-fine features, capture long-distance pixel interactions with limited computational cost, and improve the approximation of the Taylor expansion remainder. Experimental results across diverse image restoration benchmarks demonstrate that MB-TaylorFormer V2 achieves state-of-the-art performance in multiple image restoration tasks, such as image dehazing, deraining, desnowing, motion deblurring, and denoising, with very little computational overhead. The source code is available at https://github.com/FVL2020/MB-TaylorFormerV2.