 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLDif: Diffusion Models for Low-light Emotion Recognition
Paper and Code
Aug 08, 2024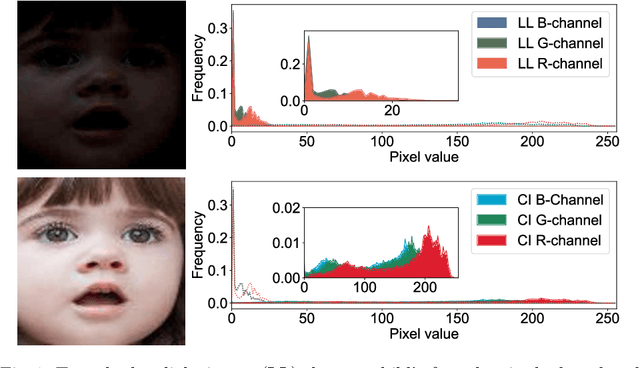
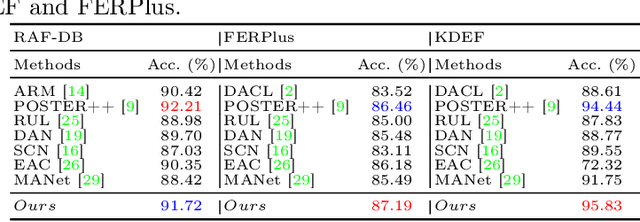
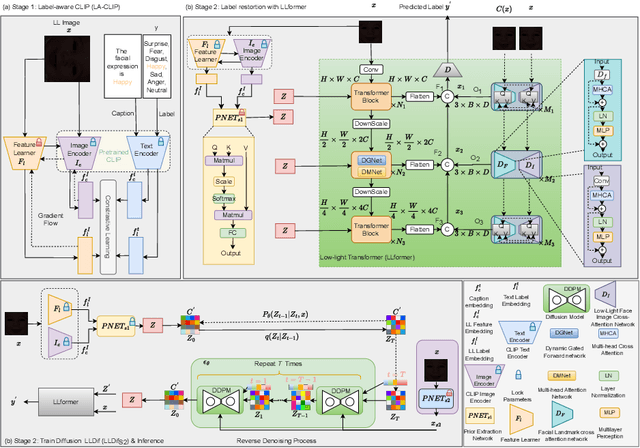
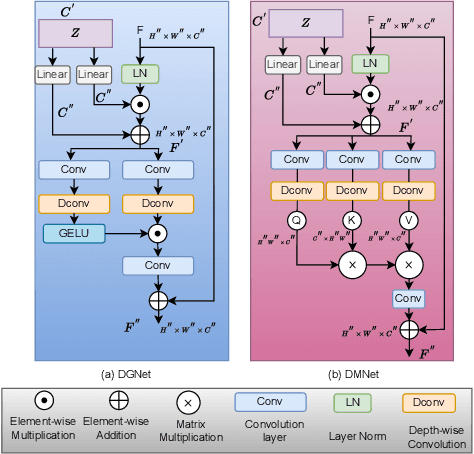
This paper introduces LLDif, a novel diffusion-based facial expression recognition (FER) framework tailored for extremely low-light (LL) environments. Images captured under such conditions often suffer from low brightness and significantly reduced contrast, presenting challenges to conventional methods. These challenges include poor image quality that can significantly reduce the accuracy of emotion recognition. LLDif addresses these issues with a novel two-stage training process that combines a Label-aware CLIP (LA-CLIP), an embedding prior network (PNET), and a transformer-based network adept at handling the noise of low-light images. The first stage involves LA-CLIP generating a joint embedding prior distribution (EPD) to guide the LLformer in label recovery. In the second stage, the diffusion model (DM) refines the EPD inference, ultilising the compactness of EPD for precise predictions. Experimental evaluations on various LL-FER datasets have shown that LLDif achieves competitive performance, underscoring its potential to enhance FER applications in challenging lighting conditions.