 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual and textual prompts for enhancing emotion recognition in video
Apr 24, 2025Vision Large Language Models (VLLMs) exhibit promising potential for multi-modal understanding, yet their application to video-based emotion recognition remains limited by insufficient spatial and contextual awareness. Traditional approaches, which prioritize isolated facial features, often neglect critical non-verbal cues such as body language, environmental context, and social interactions, leading to reduced robustness in real-world scenarios. To address this gap, we propose Set-of-Vision-Text Prompting (SoVTP), a novel framework that enhances zero-shot emotion recognition by integrating spatial annotations (e.g., bounding boxes, facial landmarks), physiological signals (facial action units), and contextual cues (body posture, scene dynamics, others' emotions) into a unified prompting strategy. SoVTP preserves holistic scene information while enabling fine-grained analysis of facial muscle movements and interpersonal dynamics. Extensive experiments show that SoVTP achieves substantial improvements over existing visual prompting methods, demonstrating its effectiveness in enhancing VLLMs' video emotion recognition capabilities.
LLDif: Diffusion Models for Low-light Emotion Recognition
Aug 08, 2024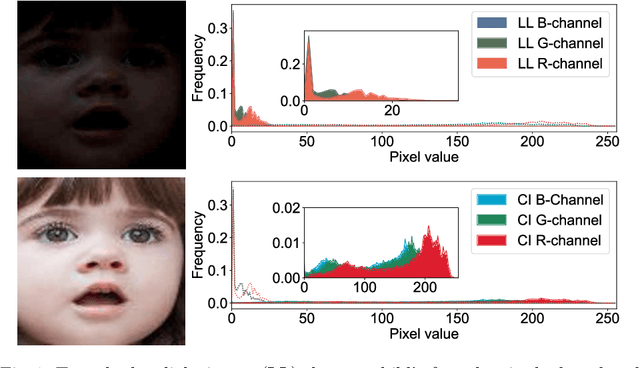
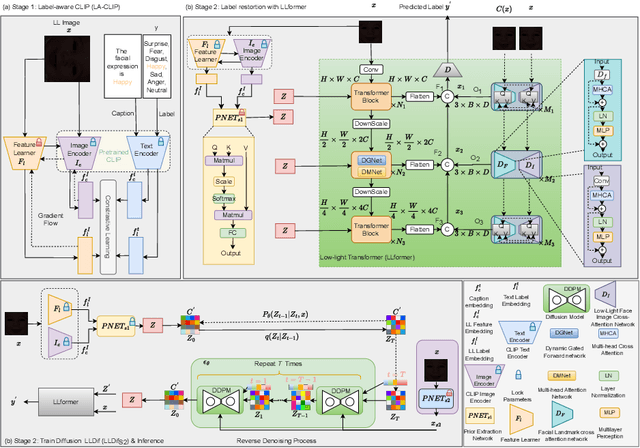
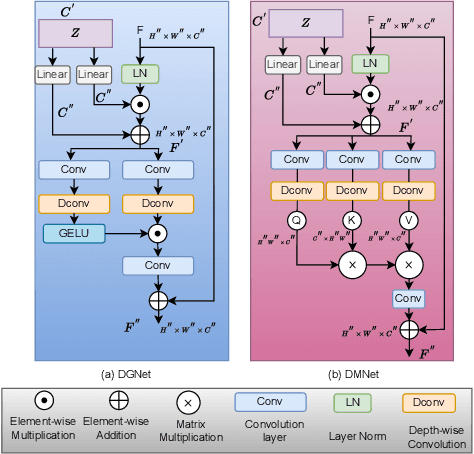
This paper introduces LLDif, a novel diffusion-based facial expression recognition (FER) framework tailored for extremely low-light (LL) environments. Images captured under such conditions often suffer from low brightness and significantly reduced contrast, presenting challenges to conventional methods. These challenges include poor image quality that can significantly reduce the accuracy of emotion recognition. LLDif addresses these issues with a novel two-stage training process that combines a Label-aware CLIP (LA-CLIP), an embedding prior network (PNET), and a transformer-based network adept at handling the noise of low-light images. The first stage involves LA-CLIP generating a joint embedding prior distribution (EPD) to guide the LLformer in label recovery. In the second stage, the diffusion model (DM) refines the EPD inference, ultilising the compactness of EPD for precise predictions. Experimental evaluations on various LL-FER datasets have shown that LLDif achieves competitive performance, underscoring its potential to enhance FER applications in challenging lighting conditions.
LRDif: Diffusion Models for Under-Display Camera Emotion Recognition
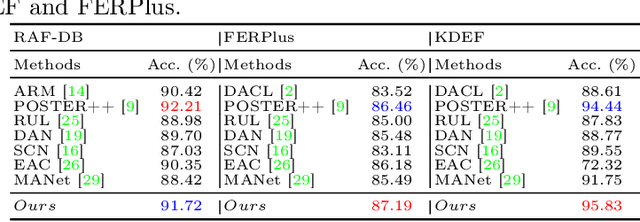
Feb 01, 2024This study introduces LRDif, a novel diffusion-based framework designed specifically for facial expression recognition (FER) within the context of under-display cameras (UDC). To address the inherent challenges posed by UDC's image degradation, such as reduced sharpness and increased noise, LRDif employs a two-stage training strategy that integrates a condensed preliminary extraction network (FPEN) and an agile transformer network (UDCformer) to effectively identify emotion labels from UDC images. By harnessing the robust distribution mapping capabilities of Diffusion Models (DMs) and the spatial dependency modeling strength of transformers, LRDif effectively overcomes the obstacles of noise and distortion inherent in UDC environments. Comprehensive experiments on standard FER datasets including RAF-DB, KDEF, and FERPlus, LRDif demonstrate state-of-the-art performance, underscoring its potential in advancing FER applications. This work not only addresses a significant gap in the literature by tackling the UDC challenge in FER but also sets a new benchmark for future research in the field.
Using Scene and Semantic Features for Multi-modal Emotion Recognition
Aug 01, 2023Automatic emotion recognition is a hot topic with a wide range of applications. Much work has been done in the area of automatic emotion recognition in recent years. The focus has been mainly on using the characteristics of a person such as speech, facial expression and pose for this purpose. However, the processing of scene and semantic features for emotion recognition has had limited exploration. In this paper, we propose to use combined scene and semantic features, along with personal features, for multi-modal emotion recognition. Scene features will describe the environment or context in which the target person is operating. The semantic feature can include objects that are present in the environment, as well as their attributes and relationships with the target person. In addition, we use a modified EmbraceNet to extract features from the images, which is trained to learn both the body and pose features simultaneously. By fusing both body and pose features, the EmbraceNet can improve the accuracy and robustness of the model, particularly when dealing with partially missing data. This is because having both body and pose features provides a more complete representation of the subject in the images, which can help the model to make more accurate predictions even when some parts of body are missing. We demonstrate the efficiency of our method on the benchmark EMOTIC dataset. We report an average precision of 40.39\% across the 26 emotion categories, which is a 5\% improvement over previous approaches.
HTNet for micro-expression recognition
Jul 27, 2023Facial expression is related to facial muscle contractions and different muscle movements correspond to different emotional states. For micro-expression recognition, the muscle movements are usually subtle, which has a negative impact on the performance of current facial emotion recognition algorithms. Most existing methods use self-attention mechanisms to capture relationships between tokens in a sequence, but they do not take into account the inherent spatial relationships between facial landmarks. This can result in sub-optimal performance on micro-expression recognition tasks.Therefore, learning to recognize facial muscle movements is a key challenge in the area of micro-expression recognition. In this paper, we propose a Hierarchical Transformer Network (HTNet) to identify critical areas of facial muscle movement. HTNet includes two major components: a transformer layer that leverages the local temporal features and an aggregation layer that extracts local and global semantical facial features. Specifically, HTNet divides the face into four different facial areas: left lip area, left eye area, right eye area and right lip area. The transformer layer is used to focus on representing local minor muscle movement with local self-attention in each area. The aggregation layer is used to learn the interactions between eye areas and lip areas. The experiments on four publicly available micro-expression datasets show that the proposed approach outperforms previous methods by a large margin. The codes and models are available at: \url{https://github.com/wangzhifengharrison/HTNet}