 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual and textual prompts for enhancing emotion recognition in video
Apr 24, 2025Vision Large Language Models (VLLMs) exhibit promising potential for multi-modal understanding, yet their application to video-based emotion recognition remains limited by insufficient spatial and contextual awareness. Traditional approaches, which prioritize isolated facial features, often neglect critical non-verbal cues such as body language, environmental context, and social interactions, leading to reduced robustness in real-world scenarios. To address this gap, we propose Set-of-Vision-Text Prompting (SoVTP), a novel framework that enhances zero-shot emotion recognition by integrating spatial annotations (e.g., bounding boxes, facial landmarks), physiological signals (facial action units), and contextual cues (body posture, scene dynamics, others' emotions) into a unified prompting strategy. SoVTP preserves holistic scene information while enabling fine-grained analysis of facial muscle movements and interpersonal dynamics. Extensive experiments show that SoVTP achieves substantial improvements over existing visual prompting methods, demonstrating its effectiveness in enhancing VLLMs' video emotion recognition capabilities.
Visual Prompting in LLMs for Enhancing Emotion Recognition
Oct 03, 2024Vision Large Language Models (VLLMs) are transforming the intersection of computer vision and natural language processing. Nonetheless, the potential of using visual prompts for emotion recognition in these models remains largely unexplored and untapped. Traditional methods in VLLMs struggle with spatial localization and often discard valuable global context. To address this problem, we propose a Set-of-Vision prompting (SoV) approach that enhances zero-shot emotion recognition by using spatial information, such as bounding boxes and facial landmarks, to mark targets precisely. SoV improves accuracy in face count and emotion categorization while preserving the enriched image context. Through a battery of experimentation and analysis of recent commercial or open-source VLLMs, we evaluate the SoV model's ability to comprehend facial expressions in natural environments. Our findings demonstrate the effectiveness of integrating spatial visual prompts into VLLMs for improving emotion recognition performance.
Authentic Emotion Mapping: Benchmarking Facial Expressions in Real News
Apr 21, 2024In this paper, we present a novel benchmark for Emotion Recognition using facial landmarks extracted from realistic news videos. Traditional methods relying on RGB images are resource-intensive, whereas our approach with Facial Landmark Emotion Recognition (FLER) offers a simplified yet effective alternative. By leveraging Graph Neural Networks (GNNs) to analyze the geometric and spatial relationships of facial landmarks, our method enhances the understanding and accuracy of emotion recognition. We discuss the advancements and challenges in deep learning techniques for emotion recognition, particularly focusing on Graph Neural Networks (GNNs) and Transformers. Our experimental results demonstrate the viability and potential of our dataset as a benchmark, setting a new direction for future research in emotion recognition technologies. The codes and models are at: https://github.com/wangzhifengharrison/benchmark_real_news
AMF: Adaptable Weighting Fusion with Multiple Fine-tuning for Image Classification
Jul 26, 2022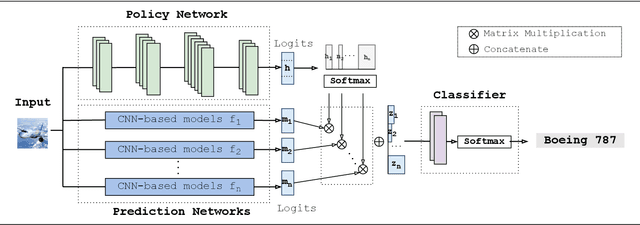
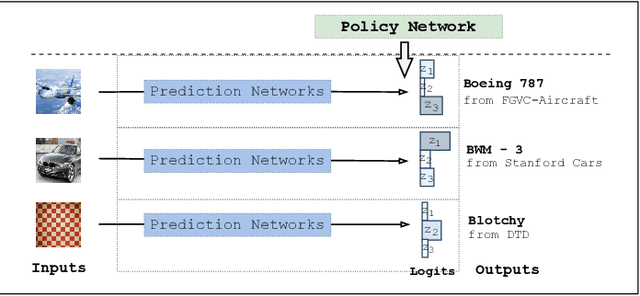
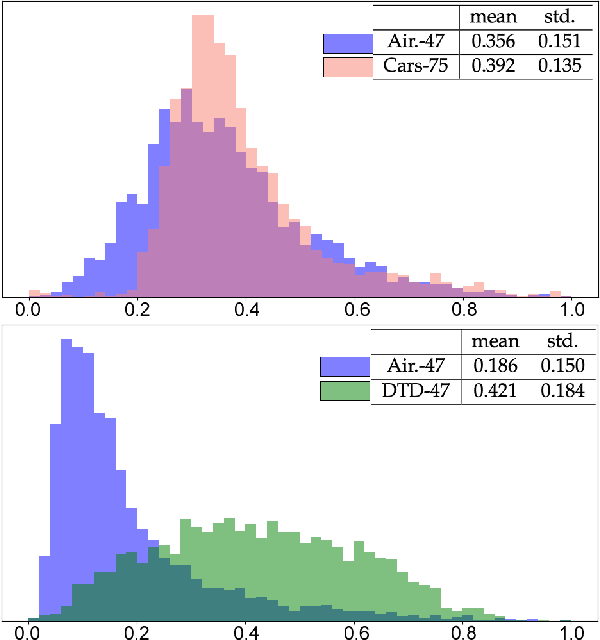
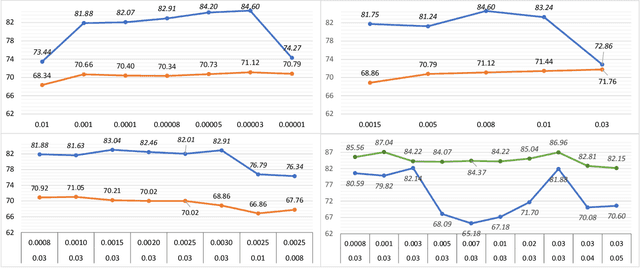
Fine-tuning is widely applied in image classification tasks as a transfer learning approach. It re-uses the knowledge from a source task to learn and obtain a high performance in target tasks. Fine-tuning is able to alleviate the challenge of insufficient training data and expensive labelling of new data. However, standard fine-tuning has limited performance in complex data distributions. To address this issue, we propose the Adaptable Multi-tuning method, which adaptively determines each data sample's fine-tuning strategy. In this framework, multiple fine-tuning settings and one policy network are defined. The policy network in Adaptable Multi-tuning can dynamically adjust to an optimal weighting to feed different samples into models that are trained using different fine-tuning strategies. Our method outperforms the standard fine-tuning approach by 1.69%, 2.79% on the datasets FGVC-Aircraft, and Describable Texture, yielding comparable performance on the datasets Stanford Cars, CIFAR-10, and Fashion-MNIST.
Exploring Biases and Prejudice of Facial Synthesis via Semantic Latent Space
Aug 23, 2021
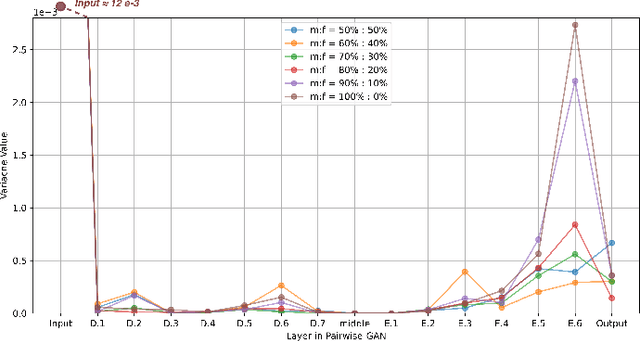
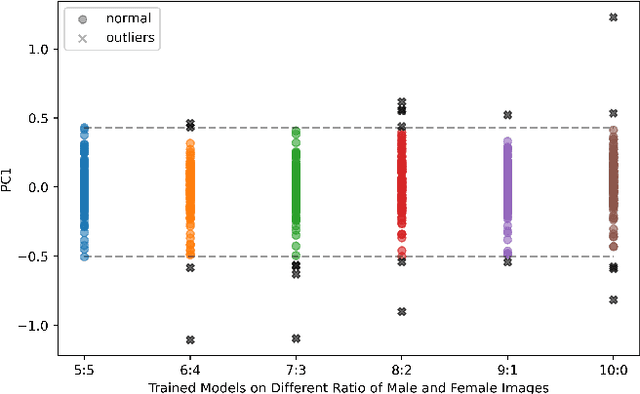
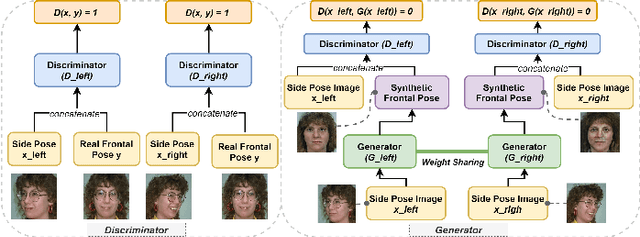
Deep learning (DL) models are widely used to provide a more convenient and smarter life. However, biased algorithms will negatively influence us. For instance, groups targeted by biased algorithms will feel unfairly treated and even fearful of negative consequences of these biases. This work targets biased generative models' behaviors, identifying the cause of the biases and eliminating them. We can (as expected) conclude that biased data causes biased predictions of face frontalization models. Varying the proportions of male and female faces in the training data can have a substantial effect on behavior on the test data: we found that the seemingly obvious choice of 50:50 proportions was not the best for this dataset to reduce biased behavior on female faces, which was 71% unbiased as compared to our top unbiased rate of 84%. Failure in generation and generating incorrect gender faces are two behaviors of these models. In addition, only some layers in face frontalization models are vulnerable to biased datasets. Optimizing the skip-connections of the generator in face frontalization models can make models less biased. We conclude that it is likely to be impossible to eliminate all training bias without an unlimited size dataset, and our experiments show that the bias can be reduced and quantified. We believe the next best to a perfect unbiased predictor is one that has minimized the remaining known bias.
Disentangling Noise from Images: A Flow-Based Image Denoising Neural Network
May 11, 2021



The prevalent convolutional neural network (CNN) based image denoising methods extract features of images to restore the clean ground truth, achieving high denoising accuracy. However, these methods may ignore the underlying distribution of clean images, inducing distortions or artifacts in denoising results. This paper proposes a new perspective to treat image denoising as a distribution learning and disentangling task. Since the noisy image distribution can be viewed as a joint distribution of clean images and noise, the denoised images can be obtained via manipulating the latent representations to the clean counterpart. This paper also provides a distribution learning based denoising framework. Following this framework, we present an invertible denoising network, FDN, without any assumptions on either clean or noise distributions, as well as a distribution disentanglement method. FDN learns the distribution of noisy images, which is different from the previous CNN based discriminative mapping. Experimental results demonstrate FDN's capacity to remove synthetic additive white Gaussian noise (AWGN) on both category-specific and remote sensing images. Furthermore, the performance of FDN surpasses that of previously published methods in real image denoising with fewer parameters and faster speed. Our code is available at: https://github.com/Yang-Liu1082/FDN.git.
Invertible Denoising Network: A Light Solution for Real Noise Removal
Apr 21, 2021



Invertible networks have various benefits for image denoising since they are lightweight, information-lossless, and memory-saving during back-propagation. However, applying invertible models to remove noise is challenging because the input is noisy, and the reversed output is clean, following two different distributions. We propose an invertible denoising network, InvDN, to address this challenge. InvDN transforms the noisy input into a low-resolution clean image and a latent representation containing noise. To discard noise and restore the clean image, InvDN replaces the noisy latent representation with another one sampled from a prior distribution during reversion. The denoising performance of InvDN is better than all the existing competitive models, achieving a new state-of-the-art result for the SIDD dataset while enjoying less run time. Moreover, the size of InvDN is far smaller, only having 4.2% of the number of parameters compared to the most recently proposed DANet. Further, via manipulating the noisy latent representation, InvDN is also able to generate noise more similar to the original one. Our code is available at: https://github.com/Yang-Liu1082/InvDN.git.
Are Deep Neural Architectures Losing Information? Invertibility Is Indispensable
Sep 29, 2020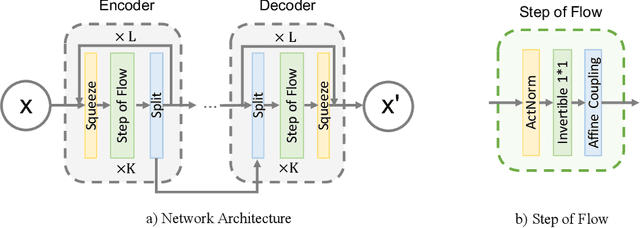
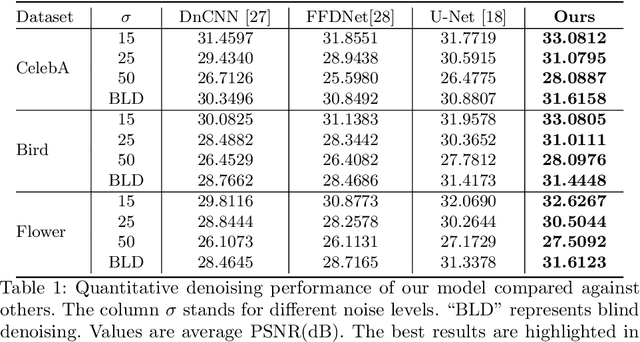


Ever since the advent of AlexNet, designing novel deep neural architectures for different tasks has consistently been a productive research direction. Despite the exceptional performance of various architectures in practice, we study a theoretical question: what is the condition for deep neural architectures to preserve all the information of the input data? Identifying the information lossless condition for deep neural architectures is important, because tasks such as image restoration require keep the detailed information of the input data as much as possible. Using the definition of mutual information, we show that: a deep neural architecture can preserve maximum details about the given data if and only if the architecture is invertible. We verify the advantages of our Invertible Restoring Autoencoder (IRAE) network by comparing it with competitive models on three perturbed image restoration tasks: image denoising, jpeg image decompression and image inpainting. Experimental results show that IRAE consistently outperforms non-invertible ones. Our model even contains far fewer parameters. Thus, it may be worthwhile to try replacing standard components of deep neural architectures, such as residual blocks and ReLU, with their invertible counterparts. We believe our work provides a unique perspective and direction for future deep learning research.
A Token-wise CNN-based Method for Sentence Compression
Sep 23, 2020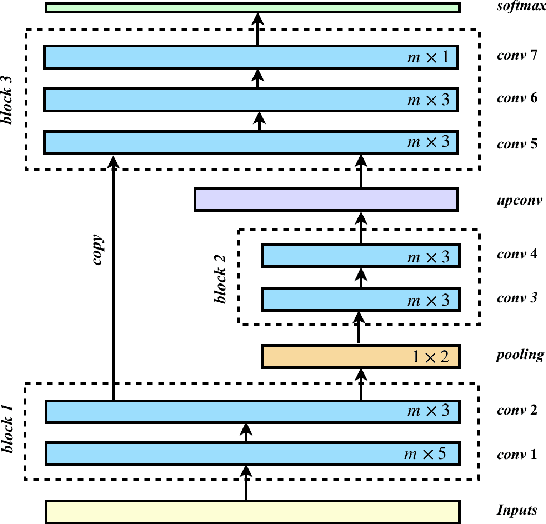

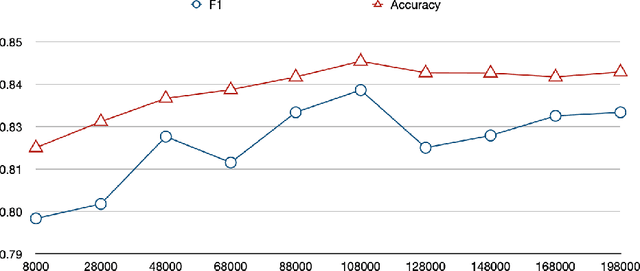

Sentence compression is a Natural Language Processing (NLP) task aimed at shortening original sentences and preserving their key information. Its applications can benefit many fields e.g. one can build tools for language education. However, current methods are largely based on Recurrent Neural Network (RNN) models which suffer from poor processing speed. To address this issue, in this paper, we propose a token-wise Convolutional Neural Network, a CNN-based model along with pre-trained Bidirectional Encoder Representations from Transformers (BERT) features for deletion-based sentence compression. We also compare our model with RNN-based models and fine-tuned BERT. Although one of the RNN-based models outperforms marginally other models given the same input, our CNN-based model was ten times faster than the RNN-based approach.