 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonoSelect: Efficient Ultrasound Perception via Active Probe Exploration
Apr 07, 2026Ultrasound perception typically requires multiple scan views through probe movement to reduce diagnostic ambiguity, mitigate acoustic occlusions, and improve anatomical coverage. However, not all probe views are equally informative. Exhaustively acquiring a large number of views can introduce substantial redundancy, increase scanning and processing costs. To address this, we define an active view exploration task for ultrasound and propose SonoSelect, an ultrasound-specific method that adaptively guides probe movement based on current observations. Specifically, we cast ultrasound active view exploration as a sequential decision-making problem. Each new 2D ultrasound view is fused into a 3D spatial memory of the observed anatomy, which guides the next probe position. On top of this formulation, we propose an ultrasound-specific objective that favors probe movements with greater organ coverage, lower reconstruction uncertainty, and less redundant scanning. Experiments on the ultrasound simulator show that SonoSelect achieves promising multi-view organ classification accuracy using only 2 out of N views. Furthermore, for a more difficult kidney cyst detection task, it reaches 54.56% kidney coverage and 35.13% cyst coverage, with short trajectories consistently centered on the target cyst.
VOLMO: Versatile and Open Large Models for Ophthalmology
Mar 25, 2026Vision impairment affects millions globally, and early detection is critical to preventing irreversible vision loss. Ophthalmology workflows require clinicians to integrate medical images, structured clinical data, and free-text notes to determine disease severity and management, which is time-consuming and burdensome. Recent multimodal large language models (MLLMs) show promise, but existing general and medical MLLMs perform poorly in ophthalmology, and few ophthalmology-specific MLLMs are openly available. We present VOLMO (Versatile and Open Large Models for Ophthalmology), a model-agnostic, data-open framework for developing ophthalmology-specific MLLMs. VOLMO includes three stages: ophthalmology knowledge pretraining on 86,965 image-text pairs from 26,569 articles across 82 journals; domain task fine-tuning on 26,929 annotated instances spanning 12 eye conditions for disease screening and severity classification; and multi-step clinical reasoning on 913 patient case reports for assessment, planning, and follow-up care. Using this framework, we trained a compact 2B-parameter MLLM and compared it with strong baselines, including InternVL-2B, LLaVA-Med-7B, MedGemma-4B, MedGemma-27B, and RETFound. We evaluated these models on image description generation, disease screening and staging classification, and assessment-and-management generation, with additional manual review by two healthcare professionals and external validation on three independent cohorts for age-related macular degeneration and diabetic retinopathy. Across settings, VOLMO-2B consistently outperformed baselines, achieving stronger image description performance, an average F1 of 87.4% across 12 eye conditions, and higher scores in external validation.
Mind the Rarities: Can Rare Skin Diseases Be Reliably Diagnosed via Diagnostic Reasoning?
Mar 19, 2026Large vision-language models (LVLMs) demonstrate strong performance in dermatology; however, evaluating diagnostic reasoning for rare conditions remains largely unexplored. Existing benchmarks focus on common diseases and assess only final accuracy, overlooking the clinical reasoning process, which is critical for complex cases. We address this gap by constructing DermCase, a long-context benchmark derived from peer-reviewed case reports. Our dataset contains 26,030 multi-modal image-text pairs and 6,354 clinically challenging cases, each annotated with comprehensive clinical information and step-by-step reasoning chains. To enable reliable evaluation, we establish DermLIP-based similarity metrics that achieve stronger alignment with dermatologists for assessing differential diagnosis quality. Benchmarking 22 leading LVLMs exposes significant deficiencies across diagnosis accuracy, differential diagnosis, and clinical reasoning. Fine-tuning experiments demonstrate that instruction tuning substantially improves performance while Direct Preference Optimization (DPO) yields minimal gains. Systematic error analysis further reveals critical limitations in current models' reasoning capabilities.
Beyond Medical Diagnostics: How Medical Multimodal Large Language Models Think in Space
Mar 14, 2026Visual spatial intelligence is critical for medical image interpretation, yet remains largely unexplored in Multimodal Large Language Models (MLLMs) for 3D imaging. This gap persists due to a systemic lack of datasets featuring structured 3D spatial annotations beyond basic labels. In this study, we introduce an agentic pipeline that autonomously synthesizes spatial visual question-answering (VQA) data by orchestrating computational tools such as volume and distance calculators with multi-agent collaboration and expert radiologist validation. We present SpatialMed, the first comprehensive benchmark for evaluating 3D spatial intelligence in medical MLLMs, comprising nearly 10K question-answer pairs across multiple organs and tumor types. Our evaluations on 14 state-of-the-art MLLMs and extensive analyses reveal that current models lack robust spatial reasoning capabilities for medical imaging.
A Federated and Parameter-Efficient Framework for Large Language Model Training in Medicine
Jan 29, 2026Large language models (LLMs) have demonstrated strong performance on medical benchmarks, including question answering and diagnosis. To enable their use in clinical settings, LLMs are typically further adapted through continued pretraining or post-training using clinical data. However, most medical LLMs are trained on data from a single institution, which faces limitations in generalizability and safety in heterogeneous systems. Federated learning (FL) is a promising solution for enabling collaborative model development across healthcare institutions. Yet applying FL to LLMs in medicine remains fundamentally limited. First, conventional FL requires transmitting the full model during each communication round, which becomes impractical for multi-billion-parameter LLMs given the limited computational resources. Second, many FL algorithms implicitly assume data homogeneity, whereas real-world clinical data are highly heterogeneous across patients, diseases, and institutional practices. We introduce the model-agnostic and parameter-efficient federated learning framework for adapting LLMs to medical applications. Fed-MedLoRA transmits only low-rank adapter parameters, reducing communication and computation overhead, while Fed-MedLoRA+ further incorporates adaptive, data-aware aggregation to improve convergence under cross-site heterogeneity. We apply the framework to clinical information extraction (IE), which transforms patient narratives into structured medical entities and relations. Accuracy was assessed across five patient cohorts through comparisons with BERT models, and LLaMA-3 and DeepSeek-R1, GPT-4o models. Evaluation settings included (1) in-domain training and testing, (2) external validation on independent cohorts, and (3) a low-resource new-site adaptation scenario using real-world clinical notes from the Yale New Haven Health System.
Plane Geometry Problem Solving with Multi-modal Reasoning: A Survey
May 20, 2025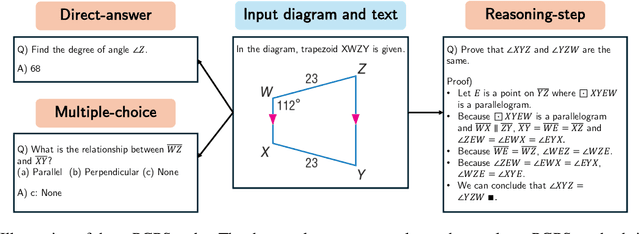
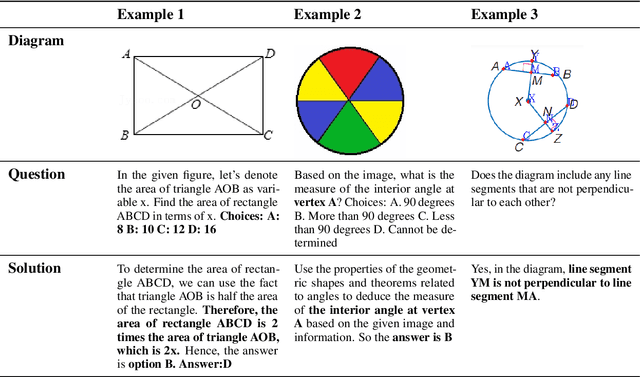
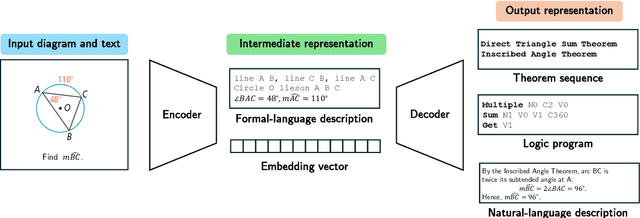
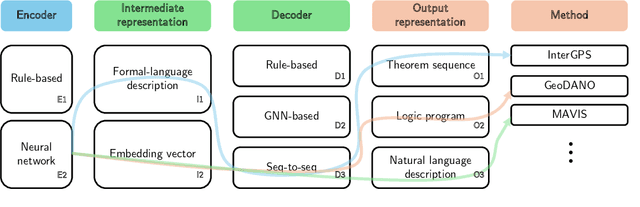
Plane geometry problem solving (PGPS) has recently gained significant attention as a benchmark to assess the multi-modal reasoning capabilities of large vision-language models. Despite the growing interest in PGPS, the research community still lacks a comprehensive overview that systematically synthesizes recent work in PGPS. To fill this gap, we present a survey of existing PGPS studies. We first categorize PGPS methods into an encoder-decoder framework and summarize the corresponding output formats used by their encoders and decoders. Subsequently, we classify and analyze these encoders and decoders according to their architectural designs. Finally, we outline major challenges and promising directions for future research. In particular, we discuss the hallucination issues arising during the encoding phase within encoder-decoder architectures, as well as the problem of data leakage in current PGPS benchmarks.
GeoDANO: Geometric VLM with Domain Agnostic Vision Encoder
Feb 17, 2025We introduce GeoDANO, a geometric vision-language model (VLM) with a domain-agnostic vision encoder, for solving plane geometry problems. Although VLMs have been employed for solving geometry problems, their ability to recognize geometric features remains insufficiently analyzed. To address this gap, we propose a benchmark that evaluates the recognition of visual geometric features, including primitives such as dots and lines, and relations such as orthogonality. Our preliminary study shows that vision encoders often used in general-purpose VLMs, e.g., OpenCLIP, fail to detect these features and struggle to generalize across domains. We develop GeoCLIP, a CLIP based model trained on synthetic geometric diagram-caption pairs to overcome the limitation. Benchmark results show that GeoCLIP outperforms existing vision encoders in recognizing geometric features. We then propose our VLM, GeoDANO, which augments GeoCLIP with a domain adaptation strategy for unseen diagram styles. GeoDANO outperforms specialized methods for plane geometry problems and GPT-4o on MathVerse.
HandCraft: Anatomically Correct Restoration of Malformed Hands in Diffusion Generated Images
Nov 07, 2024



Generative text-to-image models, such as Stable Diffusion, have demonstrated a remarkable ability to generate diverse, high-quality images. However, they are surprisingly inept when it comes to rendering human hands, which are often anatomically incorrect or reside in the "uncanny valley". In this paper, we propose a method HandCraft for restoring such malformed hands. This is achieved by automatically constructing masks and depth images for hands as conditioning signals using a parametric model, allowing a diffusion-based image editor to fix the hand's anatomy and adjust its pose while seamlessly integrating the changes into the original image, preserving pose, color, and style. Our plug-and-play hand restoration solution is compatible with existing pretrained diffusion models, and the restoration process facilitates adoption by eschewing any fine-tuning or training requirements for the diffusion models. We also contribute MalHand datasets that contain generated images with a wide variety of malformed hands in several styles for hand detector training and hand restoration benchmarking, and demonstrate through qualitative and quantitative evaluation that HandCraft not only restores anatomical correctness but also maintains the integrity of the overall image.
Visual Prompting in LLMs for Enhancing Emotion Recognition
Oct 03, 2024Vision Large Language Models (VLLMs) are transforming the intersection of computer vision and natural language processing. Nonetheless, the potential of using visual prompts for emotion recognition in these models remains largely unexplored and untapped. Traditional methods in VLLMs struggle with spatial localization and often discard valuable global context. To address this problem, we propose a Set-of-Vision prompting (SoV) approach that enhances zero-shot emotion recognition by using spatial information, such as bounding boxes and facial landmarks, to mark targets precisely. SoV improves accuracy in face count and emotion categorization while preserving the enriched image context. Through a battery of experimentation and analysis of recent commercial or open-source VLLMs, we evaluate the SoV model's ability to comprehend facial expressions in natural environments. Our findings demonstrate the effectiveness of integrating spatial visual prompts into VLLMs for improving emotion recognition performance.
LMOD: A Large Multimodal Ophthalmology Dataset and Benchmark for Large Vision-Language Models
Oct 02, 2024



Ophthalmology relies heavily on detailed image analysis for diagnosis and treatment planning. While large vision-language models (LVLMs) have shown promise in understanding complex visual information, their performance on ophthalmology images remains underexplored. We introduce LMOD, a dataset and benchmark for evaluating LVLMs on ophthalmology images, covering anatomical understanding, diagnostic analysis, and demographic extraction. LMODincludes 21,993 images spanning optical coherence tomography, scanning laser ophthalmoscopy, eye photos, surgical scenes, and color fundus photographs. We benchmark 13 state-of-the-art LVLMs and find that they are far from perfect for comprehending ophthalmology images. Models struggle with diagnostic analysis and demographic extraction, reveal weaknesses in spatial reasoning, diagnostic analysis, handling out-of-domain queries, and safeguards for handling biomarkers of ophthalmology images.