 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Generating Rules of Malicious Software Packages via Large Language Model
Apr 24, 2025Today's security tools predominantly rely on predefined rules crafted by experts, making them poorly adapted to the emergence of software supply chain attacks. To tackle this limitation, we propose a novel tool, RuleLLM, which leverages large language models (LLMs) to automate rule generation for OSS ecosystems. RuleLLM extracts metadata and code snippets from malware as its input, producing YARA and Semgrep rules that can be directly deployed in software development. Specifically, the rule generation task involves three subtasks: crafting rules, refining rules, and aligning rules. To validate RuleLLM's effectiveness, we implemented a prototype system and conducted experiments on the dataset of 1,633 malicious packages. The results are promising that RuleLLM generated 763 rules (452 YARA and 311 Semgrep) with a precision of 85.2\% and a recall of 91.8\%, outperforming state-of-the-art (SOTA) tools and scored-based approaches. We further analyzed generated rules and proposed a rule taxonomy: 11 categories and 38 subcategories.
* 14 pages, 11 figures
Visual and textual prompts for enhancing emotion recognition in video
Apr 24, 2025Vision Large Language Models (VLLMs) exhibit promising potential for multi-modal understanding, yet their application to video-based emotion recognition remains limited by insufficient spatial and contextual awareness. Traditional approaches, which prioritize isolated facial features, often neglect critical non-verbal cues such as body language, environmental context, and social interactions, leading to reduced robustness in real-world scenarios. To address this gap, we propose Set-of-Vision-Text Prompting (SoVTP), a novel framework that enhances zero-shot emotion recognition by integrating spatial annotations (e.g., bounding boxes, facial landmarks), physiological signals (facial action units), and contextual cues (body posture, scene dynamics, others' emotions) into a unified prompting strategy. SoVTP preserves holistic scene information while enabling fine-grained analysis of facial muscle movements and interpersonal dynamics. Extensive experiments show that SoVTP achieves substantial improvements over existing visual prompting methods, demonstrating its effectiveness in enhancing VLLMs' video emotion recognition capabilities.
Visual Prompting in LLMs for Enhancing Emotion Recognition
Oct 03, 2024Vision Large Language Models (VLLMs) are transforming the intersection of computer vision and natural language processing. Nonetheless, the potential of using visual prompts for emotion recognition in these models remains largely unexplored and untapped. Traditional methods in VLLMs struggle with spatial localization and often discard valuable global context. To address this problem, we propose a Set-of-Vision prompting (SoV) approach that enhances zero-shot emotion recognition by using spatial information, such as bounding boxes and facial landmarks, to mark targets precisely. SoV improves accuracy in face count and emotion categorization while preserving the enriched image context. Through a battery of experimentation and analysis of recent commercial or open-source VLLMs, we evaluate the SoV model's ability to comprehend facial expressions in natural environments. Our findings demonstrate the effectiveness of integrating spatial visual prompts into VLLMs for improving emotion recognition performance.
Blind Motion Deblurring Super-Resolution: When Dynamic Spatio-Temporal Learning Meets Static Image Understanding
May 27, 2021

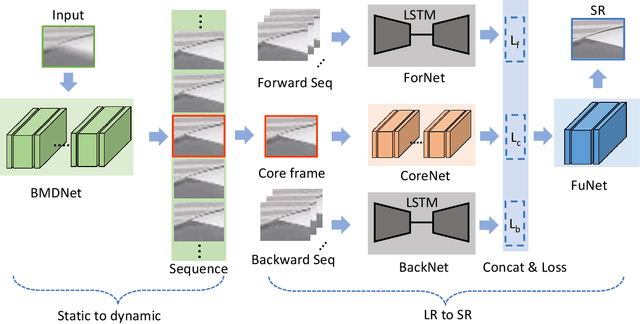
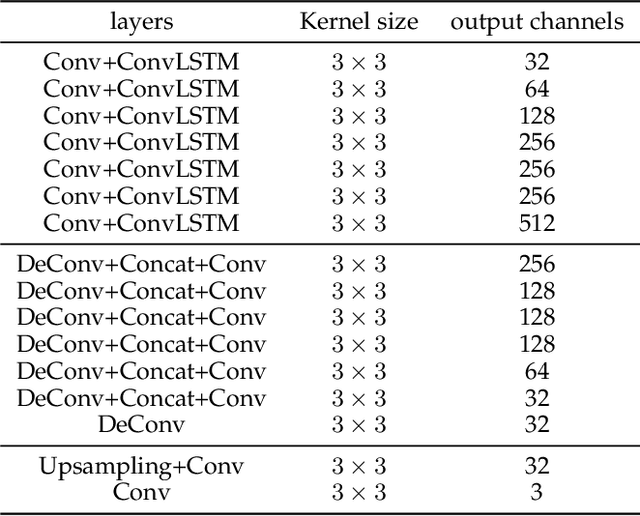
Single-image super-resolution (SR) and multi-frame SR are two ways to super resolve low-resolution images. Single-Image SR generally handles each image independently, but ignores the temporal information implied in continuing frames. Multi-frame SR is able to model the temporal dependency via capturing motion information. However, it relies on neighbouring frames which are not always available in the real world. Meanwhile, slight camera shake easily causes heavy motion blur on long-distance-shot low-resolution images. To address these problems, a Blind Motion Deblurring Super-Reslution Networks, BMDSRNet, is proposed to learn dynamic spatio-temporal information from single static motion-blurred images. Motion-blurred images are the accumulation over time during the exposure of cameras, while the proposed BMDSRNet learns the reverse process and uses three-streams to learn Bidirectional spatio-temporal information based on well designed reconstruction loss functions to recover clean high-resolution images. Extensive experiments demonstrate that the proposed BMDSRNet outperforms recent state-of-the-art methods, and has the ability to simultaneously deal with image deblurring and SR.
Bidirectional RNN-based Few-shot Training for Detecting Multi-stage Attack
May 09, 2019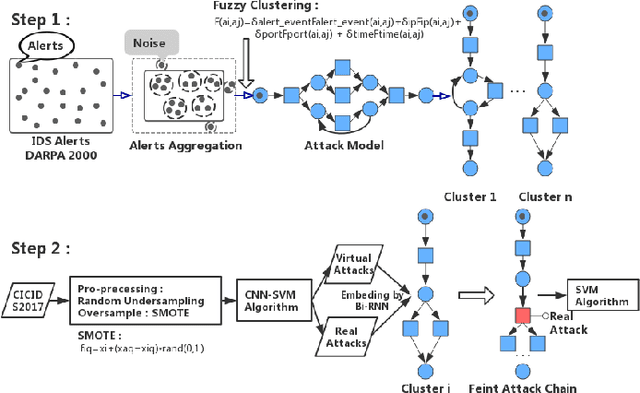
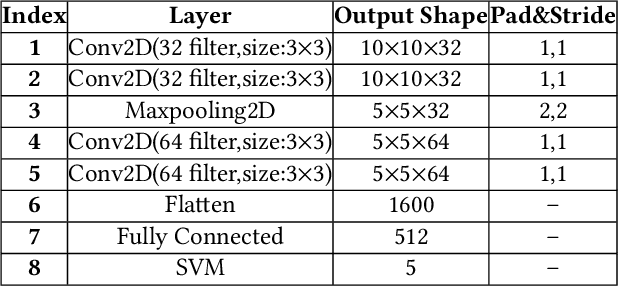
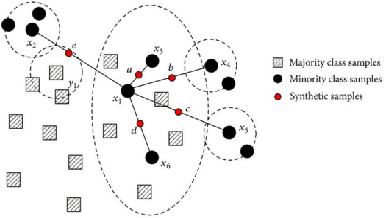
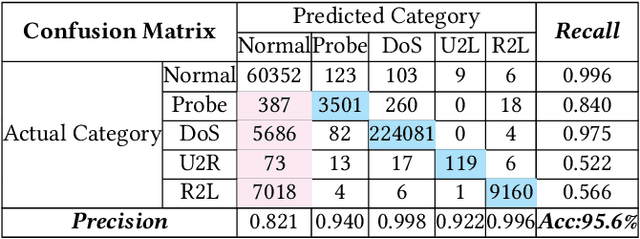
"Feint Attack", as a new type of APT attack, has become the focus of attention. It adopts a multi-stage attacks mode which can be concluded as a combination of virtual attacks and real attacks. Under the cover of virtual attacks, real attacks can achieve the real purpose of the attacker, as a result, it often caused huge losses inadvertently. However, to our knowledge, all previous works use common methods such as Causal-Correlation or Cased-based to detect outdated multi-stage attacks. Few attentions have been paid to detect the "Feint Attack", because the difficulty of detection lies in the diversification of the concept of "Feint Attack" and the lack of professional datasets, many detection methods ignore the semantic relationship in the attack. Aiming at the existing challenge, this paper explores a new method to solve the problem. In the attack scenario, the fuzzy clustering method based on attribute similarity is used to mine multi-stage attack chains. Then we use a few-shot deep learning algorithm (SMOTE&CNN-SVM) and bidirectional Recurrent Neural Network model (Bi-RNN) to obtain the "Feint Attack" chains. "Feint Attack" is simulated by the real attack inserted in the normal causal attack chain, and the addition of the real attack destroys the causal relationship of the original attack chain. So we used Bi-RNN coding to obtain the hidden feature of "Feint Attack" chain. In the end, our method achieved the goal to detect the "Feint Attack" accurately by using the LLDoS1.0 and LLDoS2.0 of DARPA2000 and CICIDS2017 of Canadian Institute for Cybersecurity.
Gradient Band-based Adversarial Training for Generalized Attack Immunity of A3C Path Finding
Jul 18, 2018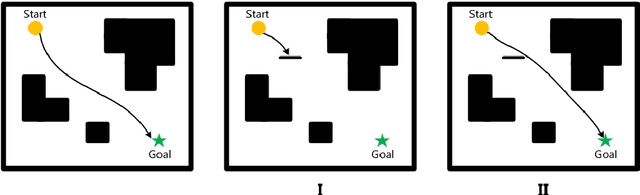
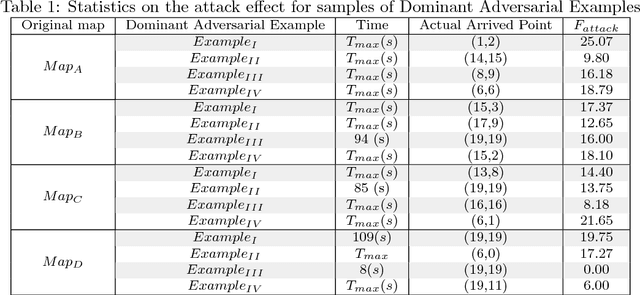
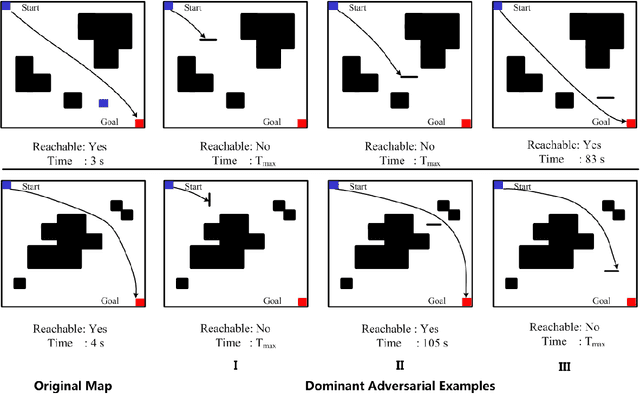
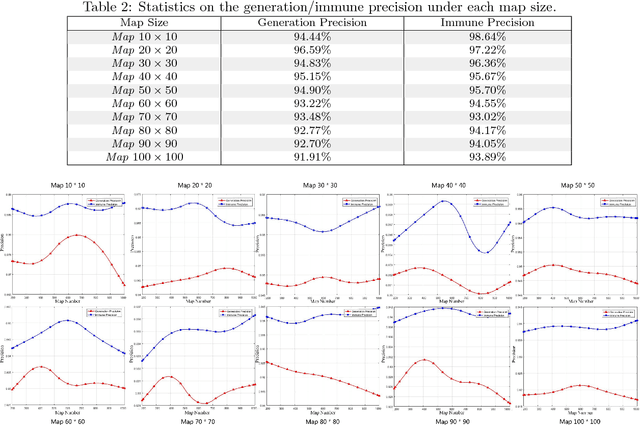
As adversarial attacks pose a serious threat to the security of AI system in practice, such attacks have been extensively studied in the context of computer vision applications. However, few attentions have been paid to the adversarial research on automatic path finding. In this paper, we show dominant adversarial examples are effective when targeting A3C path finding, and design a Common Dominant Adversarial Examples Generation Method (CDG) to generate dominant adversarial examples against any given map. In addition, we propose Gradient Band-based Adversarial Training, which trained with a single randomly choose dominant adversarial example without taking any modification, to realize the "1:N" attack immunity for generalized dominant adversarial examples. Extensive experimental results show that, the lowest generation precision for CDG algorithm is 91.91%, and the lowest immune precision for Gradient Band-based Adversarial Training is 93.89%, which can prove that our method can realize the generalized attack immunity of A3C path finding with a high confidence.
Cross-Modal Similarity Learning : A Low Rank Bilinear Formulation
Dec 17, 2015
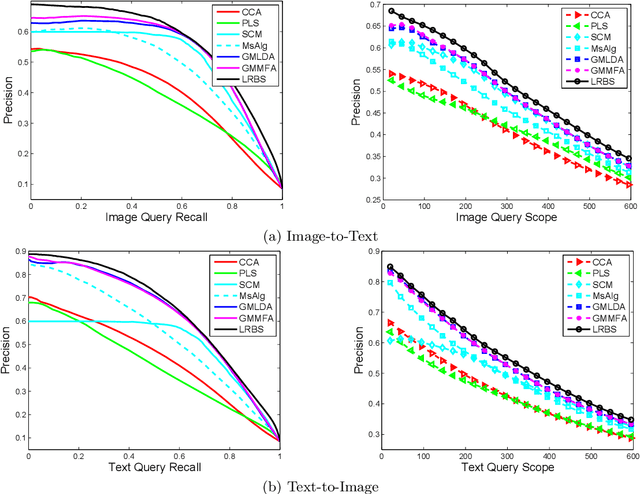


The cross-media retrieval problem has received much attention in recent years due to the rapid increasing of multimedia data on the Internet. A new approach to the problem has been raised which intends to match features of different modalities directly. In this research, there are two critical issues: how to get rid of the heterogeneity between different modalities and how to match the cross-modal features of different dimensions. Recently metric learning methods show a good capability in learning a distance metric to explore the relationship between data points. However, the traditional metric learning algorithms only focus on single-modal features, which suffer difficulties in addressing the cross-modal features of different dimensions. In this paper, we propose a cross-modal similarity learning algorithm for the cross-modal feature matching. The proposed method takes a bilinear formulation, and with the nuclear-norm penalization, it achieves low-rank representation. Accordingly, the accelerated proximal gradient algorithm is successfully imported to find the optimal solution with a fast convergence rate O(1/t^2). Experiments on three well known image-text cross-media retrieval databases show that the proposed method achieves the best performance compared to the state-of-the-art algorithms.