 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Synthetic Dataset Reliable for Benchmarking Generalizable Person Re-Identification?
Sep 12, 2022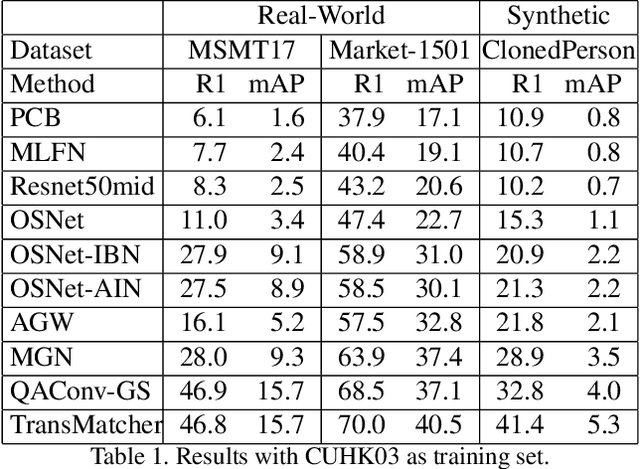
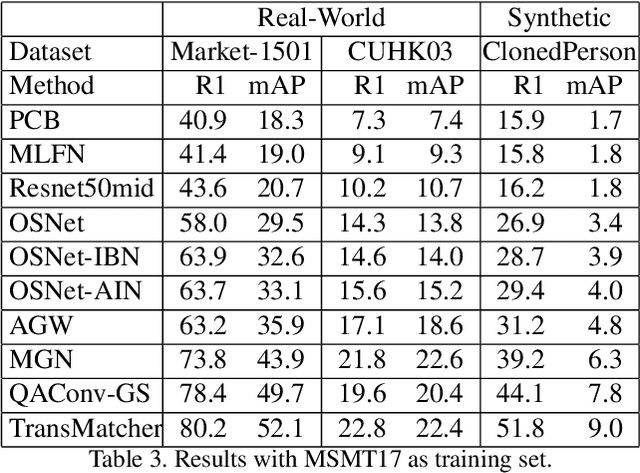
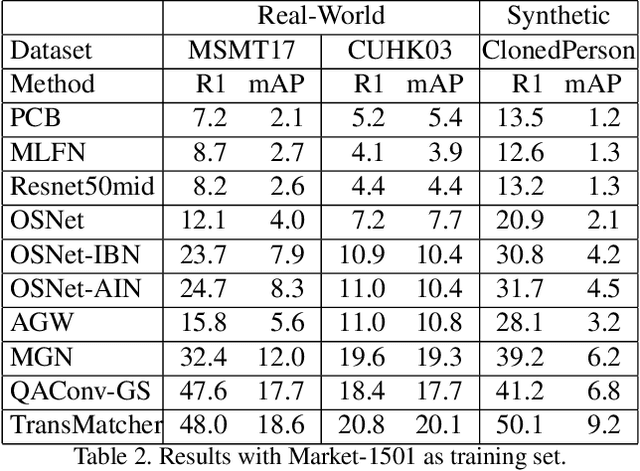
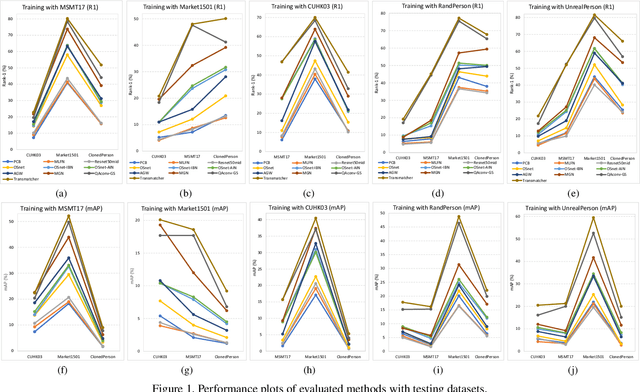
Recent studies show that models trained on synthetic datasets are able to achieve better generalizable person re-identification (GPReID) performance than that trained on public real-world datasets. On the other hand, due to the limitations of real-world person ReID datasets, it would also be important and interesting to use large-scale synthetic datasets as test sets to benchmark person ReID algorithms. Yet this raises a critical question: is synthetic dataset reliable for benchmarking generalizable person re-identification? In the literature there is no evidence showing this. To address this, we design a method called Pairwise Ranking Analysis (PRA) to quantitatively measure the ranking similarity and perform the statistical test of identical distributions. Specifically, we employ Kendall rank correlation coefficients to evaluate pairwise similarity values between algorithm rankings on different datasets. Then, a non-parametric two-sample Kolmogorov-Smirnov (KS) test is performed for the judgement of whether algorithm ranking correlations between synthetic and real-world datasets and those only between real-world datasets lie in identical distributions. We conduct comprehensive experiments, with ten representative algorithms, three popular real-world person ReID datasets, and three recently released large-scale synthetic datasets. Through the designed pairwise ranking analysis and comprehensive evaluations, we conclude that a recent large-scale synthetic dataset ClonedPerson can be reliably used to benchmark GPReID, statistically the same as real-world datasets. Therefore, this study guarantees the usage of synthetic datasets for both source training set and target testing set, with completely no privacy concerns from real-world surveillance data. Besides, the study in this paper might also inspire future designs of synthetic datasets.
Dynamically Decoding Source Domain Knowledge For Unseen Domain Generalization
Oct 06, 2021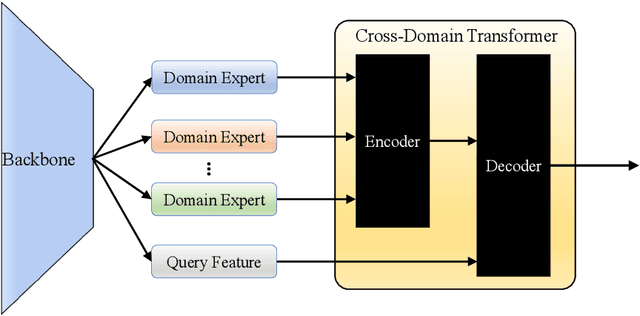
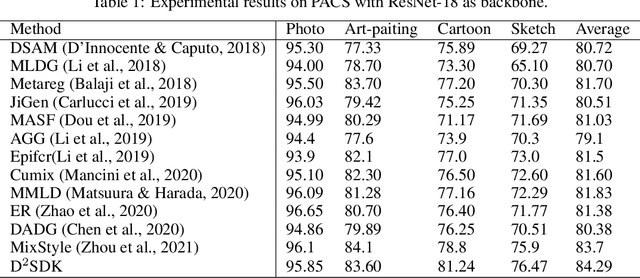
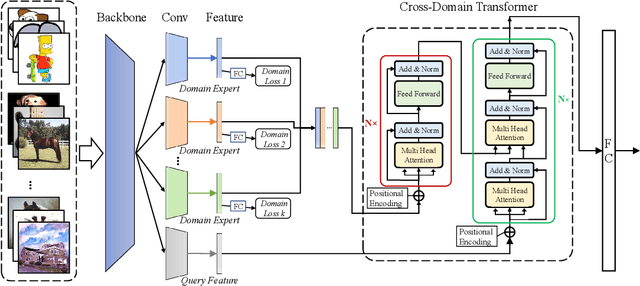
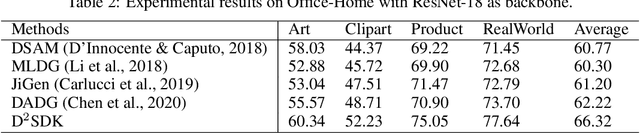
Domain generalization is an important problem which has gain much attention recently. While most existing studies focus on learning domain-invariant feature representations, some researchers try ensemble learning of multi experts and demonstrate promising performance. However, in existing multi-expert learning frameworks, the source domain knowledge has not yet been much explored, resulting in sub-optimal performance. In this paper, we propose to adapt Transformers for the purpose of dynamically decoding source domain knowledge for domain generalization. Specifically, we build one domain-specific local expert per source domain, and one domain-agnostic feature branch as query. Then, all local-domain features will be encoded by Transformer encoders, as source domain knowledge in memory. While in the Transformer decoders, the domain-agnostic query will interact with the memory in the cross-attention module, where similar domains with the input will contribute more in the attention output. This way, the source domain knowledge will be dynamically decoded for the inference of the current input from unseen domain. Therefore, this mechanism makes the proposed method well generalizable to unseen domains. The proposed method is evaluated on three benchmarks in the domain generalization field. The comparison with the state-of-the-art methods shows that the proposed method achieves the best performance, outperforming the others with a clear gap.
Discovering Spatial Relationships by Transformers for Domain Generalization
Aug 23, 2021

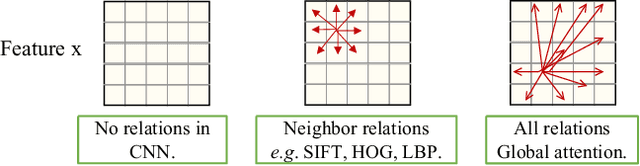
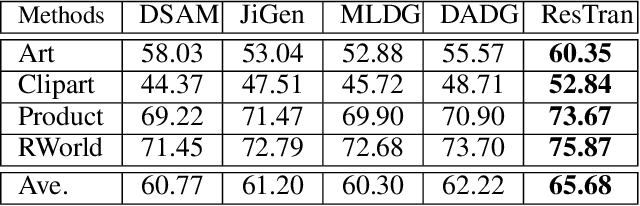
Due to the rapid increase in the diversity of image data, the problem of domain generalization has received increased attention recently. While domain generalization is a challenging problem, it has achieved great development thanks to the fast development of AI techniques in computer vision. Most of these advanced algorithms are proposed with deep architectures based on convolution neural nets (CNN). However, though CNNs have a strong ability to find the discriminative features, they do a poor job of modeling the relations between different locations in the image due to the response to CNN filters are mostly local. Since these local and global spatial relationships are characterized to distinguish an object under consideration, they play a critical role in improving the generalization ability against the domain gap. In order to get the object parts relationships to gain better domain generalization, this work proposes to use the self attention model. However, the attention models are proposed for sequence, which are not expert in discriminate feature extraction for 2D images. Considering this, we proposed a hybrid architecture to discover the spatial relationships between these local features, and derive a composite representation that encodes both the discriminative features and their relationships to improve the domain generalization. Evaluation on three well-known benchmarks demonstrates the benefits of modeling relationships between the features of an image using the proposed method and achieves state-of-the-art domain generalization performance. More specifically, the proposed algorithm outperforms the state-of-the-art by $2.2\%$ and $3.4\%$ on PACS and Office-Home databases, respectively.
DomainMix: Learning Generalizable Person Re-Identification Without Human Annotations
Nov 24, 2020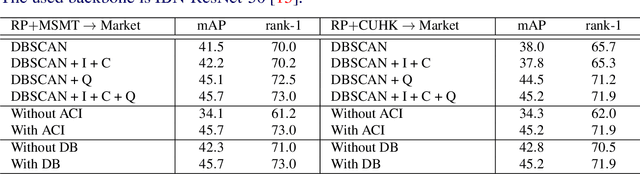
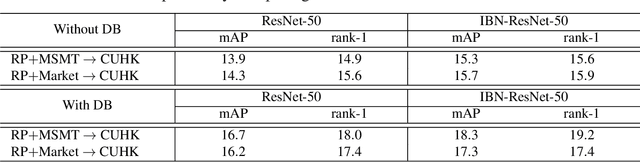

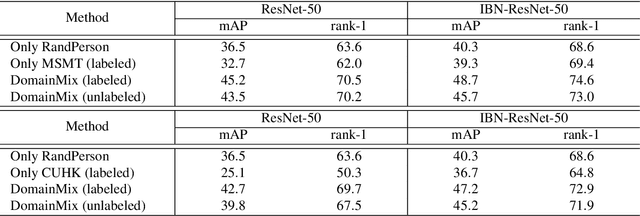
Existing person re-identification methods often have low generalization capability, which is mostly due to the limited availability of large-scale labeled training data. However, labeling large-scale training data is very expensive and time-consuming. To address this, this paper presents a solution, called DomainMix, which can learn a person re-identification model from both synthetic and real-world data, for the first time, completely without human annotations. This way, the proposed method enjoys the cheap availability of large-scale training data, and benefiting from its scalability and diversity, the learned model is able to generalize well on unseen domains. Specifically, inspired from a recent work generating large-scale synthetic data for effective person re-identification training, the proposed method firstly applies unsupervised domain adaptation from labeled synthetic data to unlabeled real-world data to generate pseudo labels. Then, the two sources of data are directly mixed together for supervised training. However, a large domain gap still exists between them. To address this, a domain-invariant feature learning method is proposed, which designs an adversarial learning between domain-invariant feature learning and domain discrimination, and meanwhile learns a discriminant feature for person re-identification. This way, the domain gap between synthetic and real-world data is much reduced, and the learned feature is generalizable thanks to the large-scale and diverse training data. Experimental results show that the proposed annotation-free method is more or less comparable to the counterpart trained with full human annotations, which is quite promising. In addition, it achieves the current state of the art on several popular person re-identification datasets under direct cross-dataset evaluation.
Cross-Modal Similarity Learning : A Low Rank Bilinear Formulation
Dec 17, 2015
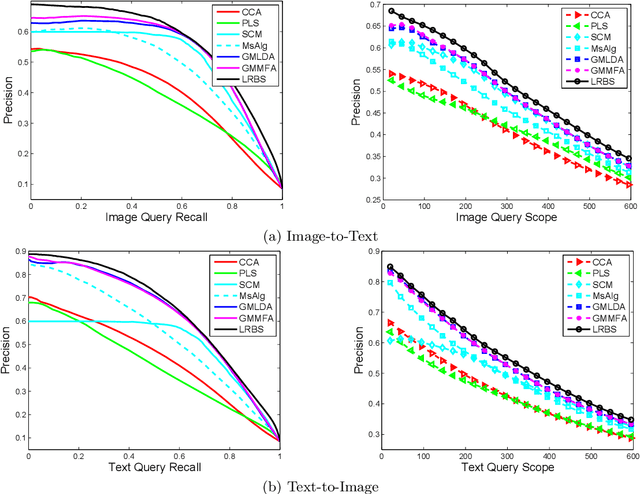


The cross-media retrieval problem has received much attention in recent years due to the rapid increasing of multimedia data on the Internet. A new approach to the problem has been raised which intends to match features of different modalities directly. In this research, there are two critical issues: how to get rid of the heterogeneity between different modalities and how to match the cross-modal features of different dimensions. Recently metric learning methods show a good capability in learning a distance metric to explore the relationship between data points. However, the traditional metric learning algorithms only focus on single-modal features, which suffer difficulties in addressing the cross-modal features of different dimensions. In this paper, we propose a cross-modal similarity learning algorithm for the cross-modal feature matching. The proposed method takes a bilinear formulation, and with the nuclear-norm penalization, it achieves low-rank representation. Accordingly, the accelerated proximal gradient algorithm is successfully imported to find the optimal solution with a fast convergence rate O(1/t^2). Experiments on three well known image-text cross-media retrieval databases show that the proposed method achieves the best performance compared to the state-of-the-art algorithms.