 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomainMix: Learning Generalizable Person Re-Identification Without Human Annotations
Paper and Code
Nov 24, 2020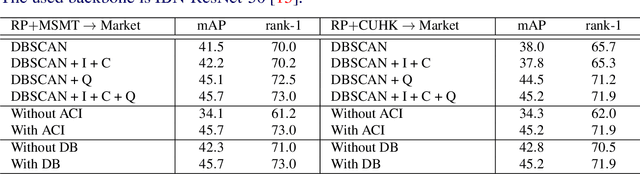
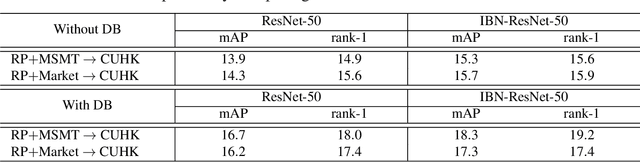

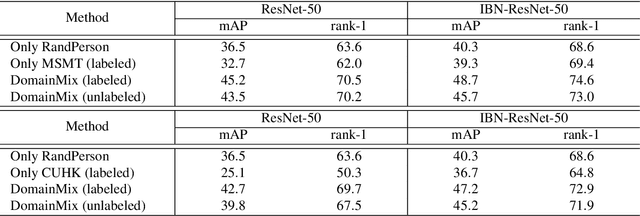
Existing person re-identification methods often have low generalization capability, which is mostly due to the limited availability of large-scale labeled training data. However, labeling large-scale training data is very expensive and time-consuming. To address this, this paper presents a solution, called DomainMix, which can learn a person re-identification model from both synthetic and real-world data, for the first time, completely without human annotations. This way, the proposed method enjoys the cheap availability of large-scale training data, and benefiting from its scalability and diversity, the learned model is able to generalize well on unseen domains. Specifically, inspired from a recent work generating large-scale synthetic data for effective person re-identification training, the proposed method firstly applies unsupervised domain adaptation from labeled synthetic data to unlabeled real-world data to generate pseudo labels. Then, the two sources of data are directly mixed together for supervised training. However, a large domain gap still exists between them. To address this, a domain-invariant feature learning method is proposed, which designs an adversarial learning between domain-invariant feature learning and domain discrimination, and meanwhile learns a discriminant feature for person re-identification. This way, the domain gap between synthetic and real-world data is much reduced, and the learned feature is generalizable thanks to the large-scale and diverse training data. Experimental results show that the proposed annotation-free method is more or less comparable to the counterpart trained with full human annotations, which is quite promising. In addition, it achieves the current state of the art on several popular person re-identification datasets under direct cross-dataset evaluation.