 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Federated and Parameter-Efficient Framework for Large Language Model Training in Medicine
Jan 29, 2026Large language models (LLMs) have demonstrated strong performance on medical benchmarks, including question answering and diagnosis. To enable their use in clinical settings, LLMs are typically further adapted through continued pretraining or post-training using clinical data. However, most medical LLMs are trained on data from a single institution, which faces limitations in generalizability and safety in heterogeneous systems. Federated learning (FL) is a promising solution for enabling collaborative model development across healthcare institutions. Yet applying FL to LLMs in medicine remains fundamentally limited. First, conventional FL requires transmitting the full model during each communication round, which becomes impractical for multi-billion-parameter LLMs given the limited computational resources. Second, many FL algorithms implicitly assume data homogeneity, whereas real-world clinical data are highly heterogeneous across patients, diseases, and institutional practices. We introduce the model-agnostic and parameter-efficient federated learning framework for adapting LLMs to medical applications. Fed-MedLoRA transmits only low-rank adapter parameters, reducing communication and computation overhead, while Fed-MedLoRA+ further incorporates adaptive, data-aware aggregation to improve convergence under cross-site heterogeneity. We apply the framework to clinical information extraction (IE), which transforms patient narratives into structured medical entities and relations. Accuracy was assessed across five patient cohorts through comparisons with BERT models, and LLaMA-3 and DeepSeek-R1, GPT-4o models. Evaluation settings included (1) in-domain training and testing, (2) external validation on independent cohorts, and (3) a low-resource new-site adaptation scenario using real-world clinical notes from the Yale New Haven Health System.
Memorization in Large Language Models in Medicine: Prevalence, Characteristics, and Implications
Sep 10, 2025Large Language Models (LLMs) have demonstrated significant potential in medicine. To date, LLMs have been widely applied to tasks such as diagnostic assistance, medical question answering, and clinical information synthesis. However, a key open question remains: to what extent do LLMs memorize medical training data. In this study, we present the first comprehensive evaluation of memorization of LLMs in medicine, assessing its prevalence (how frequently it occurs), characteristics (what is memorized), volume (how much content is memorized), and potential downstream impacts (how memorization may affect medical applications). We systematically analyze common adaptation scenarios: (1) continued pretraining on medical corpora, (2) fine-tuning on standard medical benchmarks, and (3) fine-tuning on real-world clinical data, including over 13,000 unique inpatient records from Yale New Haven Health System. The results demonstrate that memorization is prevalent across all adaptation scenarios and significantly higher than reported in the general domain. Memorization affects both the development and adoption of LLMs in medicine and can be categorized into three types: beneficial (e.g., accurate recall of clinical guidelines and biomedical references), uninformative (e.g., repeated disclaimers or templated medical document language), and harmful (e.g., regeneration of dataset-specific or sensitive clinical content). Based on these findings, we offer practical recommendations to facilitate beneficial memorization that enhances domain-specific reasoning and factual accuracy, minimize uninformative memorization to promote deeper learning beyond surface-level patterns, and mitigate harmful memorization to prevent the leakage of sensitive or identifiable patient information.
Are Traditional Deep Learning Model Approaches as Effective as a Retinal-Specific Foundation Model for Ocular and Systemic Disease Detection?
Jan 21, 2025Background: RETFound, a self-supervised, retina-specific foundation model (FM), showed potential in downstream applications. However, its comparative performance with traditional deep learning (DL) models remains incompletely understood. This study aimed to evaluate RETFound against three ImageNet-pretrained supervised DL models (ResNet50, ViT-base, SwinV2) in detecting ocular and systemic diseases. Methods: We fine-tuned/trained RETFound and three DL models on full datasets, 50%, 20%, and fixed sample sizes (400, 200, 100 images, with half comprising disease cases; for each DR severity class, 100 and 50 cases were used. Fine-tuned models were tested internally using the SEED (53,090 images) and APTOS-2019 (3,672 images) datasets and externally validated on population-based (BES, CIEMS, SP2, UKBB) and open-source datasets (ODIR-5k, PAPILA, GAMMA, IDRiD, MESSIDOR-2). Model performance was compared using area under the receiver operating characteristic curve (AUC) and Z-tests with Bonferroni correction (P<0.05/3). Interpretation: Traditional DL models are mostly comparable to RETFound for ocular disease detection with large datasets. However, RETFound is superior in systemic disease detection with smaller datasets. These findings offer valuable insights into the respective merits and limitation of traditional models and FMs.
Enhancing Community Vision Screening -- AI Driven Retinal Photography for Early Disease Detection and Patient Trust
Oct 27, 2024Community vision screening plays a crucial role in identifying individuals with vision loss and preventing avoidable blindness, particularly in rural communities where access to eye care services is limited. Currently, there is a pressing need for a simple and efficient process to screen and refer individuals with significant eye disease-related vision loss to tertiary eye care centers for further care. An ideal solution should seamlessly and readily integrate with existing workflows, providing comprehensive initial screening results to service providers, thereby enabling precise patient referrals for timely treatment. This paper introduces the Enhancing Community Vision Screening (ECVS) solution, which addresses the aforementioned concerns with a novel and feasible solution based on simple, non-invasive retinal photography for the detection of pathology-based visual impairment. Our study employs four distinct deep learning models: RETinal photo Quality Assessment (RETQA), Pathology Visual Impairment detection (PVI), Eye Disease Diagnosis (EDD) and Visualization of Lesion Regions of the eye (VLR). We conducted experiments on over 10 datasets, totaling more than 80,000 fundus photos collected from various sources. The models integrated into ECVS achieved impressive AUC scores of 0.98 for RETQA, 0.95 for PVI, and 0.90 for EDD, along with a DICE coefficient of 0.48 for VLR. These results underscore the promising capabilities of ECVS as a straightforward and scalable method for community-based vision screening.
LMOD: A Large Multimodal Ophthalmology Dataset and Benchmark for Large Vision-Language Models
Oct 02, 2024



Ophthalmology relies heavily on detailed image analysis for diagnosis and treatment planning. While large vision-language models (LVLMs) have shown promise in understanding complex visual information, their performance on ophthalmology images remains underexplored. We introduce LMOD, a dataset and benchmark for evaluating LVLMs on ophthalmology images, covering anatomical understanding, diagnostic analysis, and demographic extraction. LMODincludes 21,993 images spanning optical coherence tomography, scanning laser ophthalmoscopy, eye photos, surgical scenes, and color fundus photographs. We benchmark 13 state-of-the-art LVLMs and find that they are far from perfect for comprehending ophthalmology images. Models struggle with diagnostic analysis and demographic extraction, reveal weaknesses in spatial reasoning, diagnostic analysis, handling out-of-domain queries, and safeguards for handling biomarkers of ophthalmology images.
Enhancing Large Language Models with Domain-specific Retrieval Augment Generation: A Case Study on Long-form Consumer Health Question Answering in Ophthalmology
Sep 20, 2024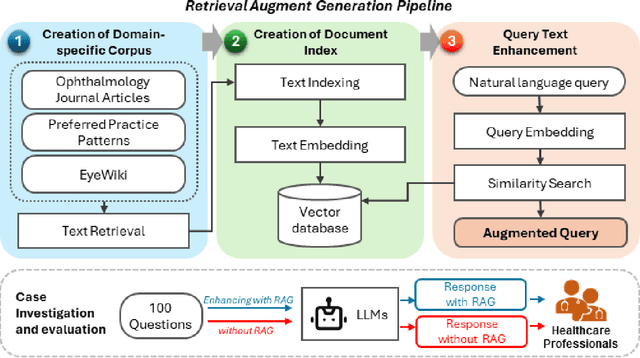

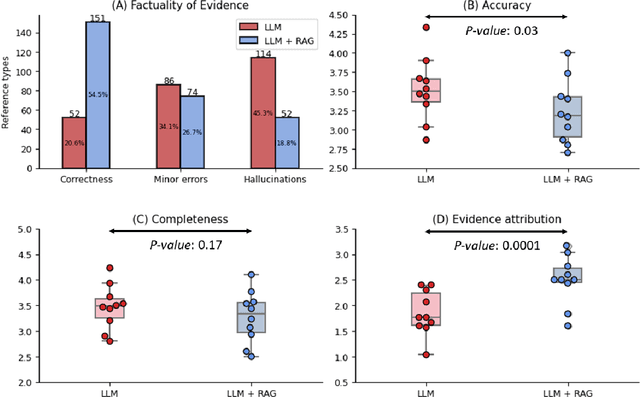

Despite the potential of Large Language Models (LLMs) in medicine, they may generate responses lacking supporting evidence or based on hallucinated evidence. While Retrieval Augment Generation (RAG) is popular to address this issue, few studies implemented and evaluated RAG in downstream domain-specific applications. We developed a RAG pipeline with 70,000 ophthalmology-specific documents that retrieve relevant documents to augment LLMs during inference time. In a case study on long-form consumer health questions, we systematically evaluated the responses including over 500 references of LLMs with and without RAG on 100 questions with 10 healthcare professionals. The evaluation focuses on factuality of evidence, selection and ranking of evidence, attribution of evidence, and answer accuracy and completeness. LLMs without RAG provided 252 references in total. Of which, 45.3% hallucinated, 34.1% consisted of minor errors, and 20.6% were correct. In contrast, LLMs with RAG significantly improved accuracy (54.5% being correct) and reduced error rates (18.8% with minor hallucinations and 26.7% with errors). 62.5% of the top 10 documents retrieved by RAG were selected as the top references in the LLM response, with an average ranking of 4.9. The use of RAG also improved evidence attribution (increasing from 1.85 to 2.49 on a 5-point scale, P<0.001), albeit with slight decreases in accuracy (from 3.52 to 3.23, P=0.03) and completeness (from 3.47 to 3.27, P=0.17). The results demonstrate that LLMs frequently exhibited hallucinated and erroneous evidence in the responses, raising concerns for downstream applications in the medical domain. RAG substantially reduced the proportion of such evidence but encountered challenges.
Localizing Anatomical Landmarks in Ocular Images using Zoom-In Attentive Networks
Sep 25, 2022Localizing anatomical landmarks are important tasks in medical image analysis. However, the landmarks to be localized often lack prominent visual features. Their locations are elusive and easily confused with the background, and thus precise localization highly depends on the context formed by their surrounding areas. In addition, the required precision is usually higher than segmentation and object detection tasks. Therefore, localization has its unique challenges different from segmentation or detection. In this paper, we propose a zoom-in attentive network (ZIAN) for anatomical landmark localization in ocular images. First, a coarse-to-fine, or "zoom-in" strategy is utilized to learn the contextualized features in different scales. Then, an attentive fusion module is adopted to aggregate multi-scale features, which consists of 1) a co-attention network with a multiple regions-of-interest (ROIs) scheme that learns complementary features from the multiple ROIs, 2) an attention-based fusion module which integrates the multi-ROIs features and non-ROI features. We evaluated ZIAN on two open challenge tasks, i.e., the fovea localization in fundus images and scleral spur localization in AS-OCT images. Experiments show that ZIAN achieves promising performances and outperforms state-of-the-art localization methods. The source code and trained models of ZIAN are available at https://github.com/leixiaofeng-astar/OMIA9-ZIAN.