 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving the bias-precision paradox with stochastic causal representation learning for personalized medicine
May 07, 2026Estimating individualized treatment effects from longitudinal observational data is central to data-driven medicine, yet existing methods face a fundamental limitation: reducing confounding bias often suppresses clinically informative heterogeneity, degrading patient-specific predictions. Here, we identify this tension as a bias-precision paradox in causal representation learning and introduce sampling-based maximum mean discrepancy (sMMD), a stochastic alignment strategy that replaces global adversarial balancing with subset-level matching. We instantiate this approach in a framework for counterfactual outcome prediction with attribution-grounded interpretability. Across two large-scale ICU cohorts (n = 27,783), our framework improves accuracy under distribution shift, reducing error by up to 11.5% and substantially increasing recall in high-risk tasks. Mechanistic analyses show that sMMD selectively preserves clinically decisive variables. In human-AI evaluation, our method outperforms clinicians-in-training and large language models, and improves clinician accuracy by 14.7% while reducing decision time, enabling interpretable, real-time clinical decision support.
AI-generated data contamination erodes pathological variability and diagnostic reliability
Jan 21, 2026Generative artificial intelligence (AI) is rapidly populating medical records with synthetic content, creating a feedback loop where future models are increasingly at risk of training on uncurated AI-generated data. However, the clinical consequences of this AI-generated data contamination remain unexplored. Here, we show that in the absence of mandatory human verification, this self-referential cycle drives a rapid erosion of pathological variability and diagnostic reliability. By analysing more than 800,000 synthetic data points across clinical text generation, vision-language reporting, and medical image synthesis, we find that models progressively converge toward generic phenotypes regardless of the model architecture. Specifically, rare but critical findings, including pneumothorax and effusions, vanish from the synthetic content generated by AI models, while demographic representations skew heavily toward middle-aged male phenotypes. Crucially, this degradation is masked by false diagnostic confidence; models continue to issue reassuring reports while failing to detect life-threatening pathology, with false reassurance rates tripling to 40%. Blinded physician evaluation confirms that this decoupling of confidence and accuracy renders AI-generated documentation clinically useless after just two generations. We systematically evaluate three mitigation strategies, finding that while synthetic volume scaling fails to prevent collapse, mixing real data with quality-aware filtering effectively preserves diversity. Ultimately, our results suggest that without policy-mandated human oversight, the deployment of generative AI threatens to degrade the very healthcare data ecosystems it relies upon.
Building Digital Twins of Different Human Organs for Personalized Healthcare
Jan 16, 2026Digital twins are virtual replicas of physical entities and are poised to transform personalized medicine through the real-time simulation and prediction of human physiology. Translating this paradigm from engineering to biomedicine requires overcoming profound challenges, including anatomical variability, multi-scale biological processes, and the integration of multi-physics phenomena. This survey systematically reviews methodologies for building digital twins of human organs, structured around a pipeline decoupled into anatomical twinning (capturing patient-specific geometry and structure) and functional twinning (simulating multi-scale physiology from cellular to organ-level function). We categorize approaches both by organ-specific properties and by technical paradigm, with particular emphasis on multi-scale and multi-physics integration. A key focus is the role of artificial intelligence (AI), especially physics-informed AI, in enhancing model fidelity, scalability, and personalization. Furthermore, we discuss the critical challenges of clinical validation and translational pathways. This study not only charts a roadmap for overcoming current bottlenecks in single-organ twins but also outlines the promising, albeit ambitious, future of interconnected multi-organ digital twins for whole-body precision healthcare.
An integrated language-vision foundation model for conversational diagnostics and triaging in primary eye care
May 13, 2025Current deep learning models are mostly task specific and lack a user-friendly interface to operate. We present Meta-EyeFM, a multi-function foundation model that integrates a large language model (LLM) with vision foundation models (VFMs) for ocular disease assessment. Meta-EyeFM leverages a routing mechanism to enable accurate task-specific analysis based on text queries. Using Low Rank Adaptation, we fine-tuned our VFMs to detect ocular and systemic diseases, differentiate ocular disease severity, and identify common ocular signs. The model achieved 100% accuracy in routing fundus images to appropriate VFMs, which achieved $\ge$ 82.2% accuracy in disease detection, $\ge$ 89% in severity differentiation, $\ge$ 76% in sign identification. Meta-EyeFM was 11% to 43% more accurate than Gemini-1.5-flash and ChatGPT-4o LMMs in detecting various eye diseases and comparable to an ophthalmologist. This system offers enhanced usability and diagnostic performance, making it a valuable decision support tool for primary eye care or an online LLM for fundus evaluation.
AI-powered virtual eye: perspective, challenges and opportunities
May 07, 2025We envision the "virtual eye" as a next-generation, AI-powered platform that uses interconnected foundation models to simulate the eye's intricate structure and biological function across all scales. Advances in AI, imaging, and multiomics provide a fertile ground for constructing a universal, high-fidelity digital replica of the human eye. This perspective traces the evolution from early mechanistic and rule-based models to contemporary AI-driven approaches, integrating in a unified model with multimodal, multiscale, dynamic predictive capabilities and embedded feedback mechanisms. We propose a development roadmap emphasizing the roles of large-scale multimodal datasets, generative AI, foundation models, agent-based architectures, and interactive interfaces. Despite challenges in interpretability, ethics, data processing and evaluation, the virtual eye holds the potential to revolutionize personalized ophthalmic care and accelerate research into ocular health and disease.
A Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
Are Traditional Deep Learning Model Approaches as Effective as a Retinal-Specific Foundation Model for Ocular and Systemic Disease Detection?
Jan 21, 2025Background: RETFound, a self-supervised, retina-specific foundation model (FM), showed potential in downstream applications. However, its comparative performance with traditional deep learning (DL) models remains incompletely understood. This study aimed to evaluate RETFound against three ImageNet-pretrained supervised DL models (ResNet50, ViT-base, SwinV2) in detecting ocular and systemic diseases. Methods: We fine-tuned/trained RETFound and three DL models on full datasets, 50%, 20%, and fixed sample sizes (400, 200, 100 images, with half comprising disease cases; for each DR severity class, 100 and 50 cases were used. Fine-tuned models were tested internally using the SEED (53,090 images) and APTOS-2019 (3,672 images) datasets and externally validated on population-based (BES, CIEMS, SP2, UKBB) and open-source datasets (ODIR-5k, PAPILA, GAMMA, IDRiD, MESSIDOR-2). Model performance was compared using area under the receiver operating characteristic curve (AUC) and Z-tests with Bonferroni correction (P<0.05/3). Interpretation: Traditional DL models are mostly comparable to RETFound for ocular disease detection with large datasets. However, RETFound is superior in systemic disease detection with smaller datasets. These findings offer valuable insights into the respective merits and limitation of traditional models and FMs.
Enhancing Community Vision Screening -- AI Driven Retinal Photography for Early Disease Detection and Patient Trust
Oct 27, 2024Community vision screening plays a crucial role in identifying individuals with vision loss and preventing avoidable blindness, particularly in rural communities where access to eye care services is limited. Currently, there is a pressing need for a simple and efficient process to screen and refer individuals with significant eye disease-related vision loss to tertiary eye care centers for further care. An ideal solution should seamlessly and readily integrate with existing workflows, providing comprehensive initial screening results to service providers, thereby enabling precise patient referrals for timely treatment. This paper introduces the Enhancing Community Vision Screening (ECVS) solution, which addresses the aforementioned concerns with a novel and feasible solution based on simple, non-invasive retinal photography for the detection of pathology-based visual impairment. Our study employs four distinct deep learning models: RETinal photo Quality Assessment (RETQA), Pathology Visual Impairment detection (PVI), Eye Disease Diagnosis (EDD) and Visualization of Lesion Regions of the eye (VLR). We conducted experiments on over 10 datasets, totaling more than 80,000 fundus photos collected from various sources. The models integrated into ECVS achieved impressive AUC scores of 0.98 for RETQA, 0.95 for PVI, and 0.90 for EDD, along with a DICE coefficient of 0.48 for VLR. These results underscore the promising capabilities of ECVS as a straightforward and scalable method for community-based vision screening.
UrFound: Towards Universal Retinal Foundation Models via Knowledge-Guided Masked Modeling
Aug 10, 2024Retinal foundation models aim to learn generalizable representations from diverse retinal images, facilitating label-efficient model adaptation across various ophthalmic tasks. Despite their success, current retinal foundation models are generally restricted to a single imaging modality, such as Color Fundus Photography (CFP) or Optical Coherence Tomography (OCT), limiting their versatility. Moreover, these models may struggle to fully leverage expert annotations and overlook the valuable domain knowledge essential for domain-specific representation learning. To overcome these limitations, we introduce UrFound, a retinal foundation model designed to learn universal representations from both multimodal retinal images and domain knowledge. UrFound is equipped with a modality-agnostic image encoder and accepts either CFP or OCT images as inputs. To integrate domain knowledge into representation learning, we encode expert annotation in text supervision and propose a knowledge-guided masked modeling strategy for model pre-training. It involves reconstructing randomly masked patches of retinal images while predicting masked text tokens conditioned on the corresponding retinal image. This approach aligns multimodal images and textual expert annotations within a unified latent space, facilitating generalizable and domain-specific representation learning. Experimental results demonstrate that UrFound exhibits strong generalization ability and data efficiency when adapting to various tasks in retinal image analysis. By training on ~180k retinal images, UrFound significantly outperforms the state-of-the-art retinal foundation model trained on up to 1.6 million unlabelled images across 8 public retinal datasets. Our code and data are available at https://github.com/yukkai/UrFound.
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024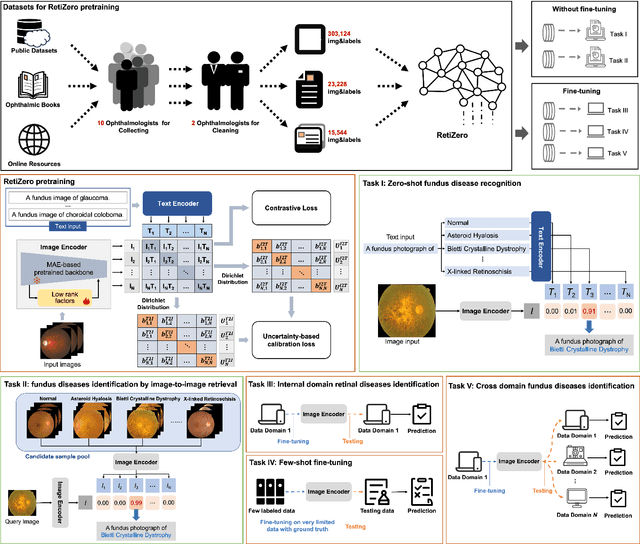
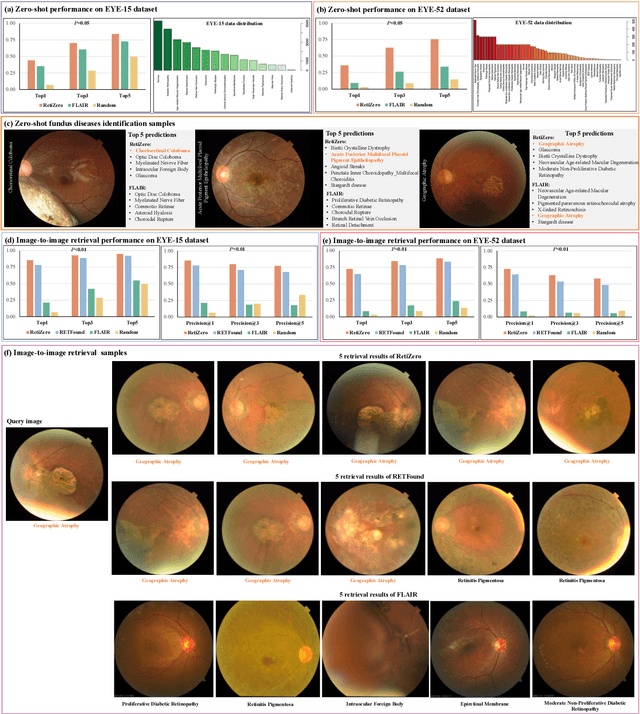
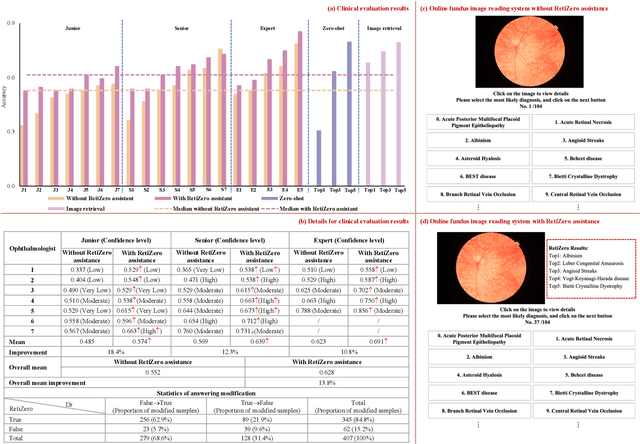
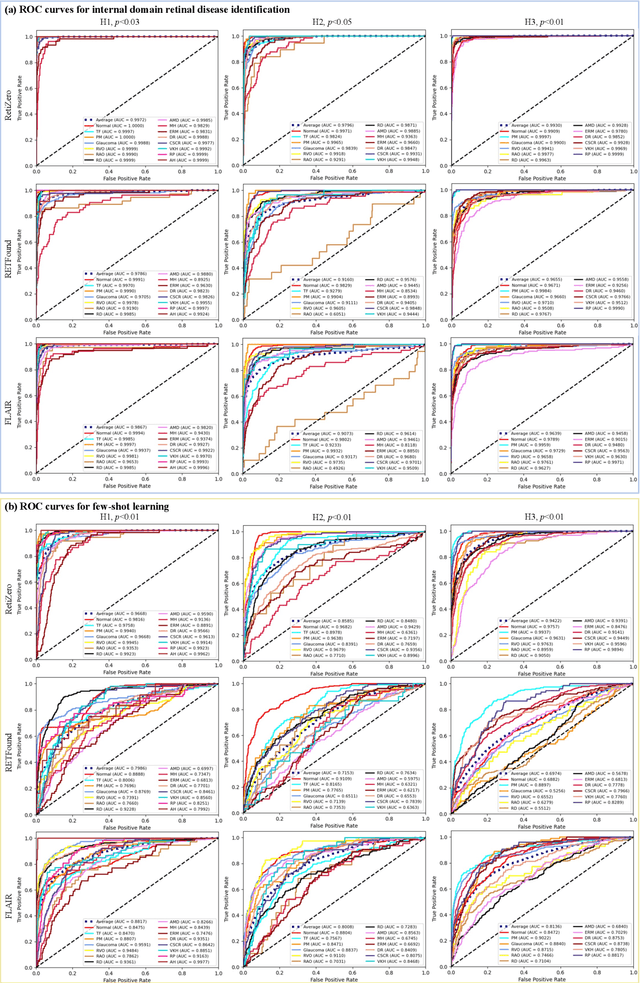
The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.