 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexPro-1.0 Technical Report
Mar 11, 2025In this report, we introduce our first-generation reasoning model, LexPro-1.0, a large language model designed for the highly specialized Chinese legal domain, offering comprehensive capabilities to meet diverse realistic needs. Existing legal LLMs face two primary challenges. Firstly, their design and evaluation are predominantly driven by computer science perspectives, leading to insufficient incorporation of legal expertise and logic, which is crucial for high-precision legal applications, such as handling complex prosecutorial tasks. Secondly, these models often underperform due to a lack of comprehensive training data from the legal domain, limiting their ability to effectively address real-world legal scenarios. To address this, we first compile millions of legal documents covering over 20 types of crimes from 31 provinces in China for model training. From the extensive dataset, we further select high-quality for supervised fine-tuning, ensuring enhanced relevance and precision. The model further undergoes large-scale reinforcement learning without additional supervision, emphasizing the enhancement of its reasoning capabilities and explainability. To validate its effectiveness in complex legal applications, we also conduct human evaluations with legal experts. We develop fine-tuned models based on DeepSeek-R1-Distilled versions, available in three dense configurations: 14B, 32B, and 70B.
Partially Supervised Unpaired Multi-Modal Learning for Label-Efficient Medical Image Segmentation
Mar 07, 2025Unpaired Multi-Modal Learning (UMML) which leverages unpaired multi-modal data to boost model performance on each individual modality has attracted a lot of research interests in medical image analysis. However, existing UMML methods require multi-modal datasets to be fully labeled, which incurs tremendous annotation cost. In this paper, we investigate the use of partially labeled data for label-efficient unpaired multi-modal learning, which can reduce the annotation cost by up to one half. We term the new learning paradigm as Partially Supervised Unpaired Multi-Modal Learning (PSUMML) and propose a novel Decomposed partial class adaptation with snapshot Ensembled Self-Training (DEST) framework for it. Specifically, our framework consists of a compact segmentation network with modality specific normalization layers for learning with partially labeled unpaired multi-modal data. The key challenge in PSUMML lies in the complex partial class distribution discrepancy due to partial class annotation, which hinders effective knowledge transfer across modalities. We theoretically analyze this phenomenon with a decomposition theorem and propose a decomposed partial class adaptation technique to precisely align the partially labeled classes across modalities to reduce the distribution discrepancy. We further propose a snapshot ensembled self-training technique to leverage the valuable snapshot models during training to assign pseudo-labels to partially labeled pixels for self-training to boost model performance. We perform extensive experiments under different scenarios of PSUMML for two medical image segmentation tasks, namely cardiac substructure segmentation and abdominal multi-organ segmentation. Our framework outperforms existing methods significantly.
BenchX: A Unified Benchmark Framework for Medical Vision-Language Pretraining on Chest X-Rays
Oct 29, 2024



Medical Vision-Language Pretraining (MedVLP) shows promise in learning generalizable and transferable visual representations from paired and unpaired medical images and reports. MedVLP can provide useful features to downstream tasks and facilitate adapting task-specific models to new setups using fewer examples. However, existing MedVLP methods often differ in terms of datasets, preprocessing, and finetuning implementations. This pose great challenges in evaluating how well a MedVLP method generalizes to various clinically-relevant tasks due to the lack of unified, standardized, and comprehensive benchmark. To fill this gap, we propose BenchX, a unified benchmark framework that enables head-to-head comparison and systematical analysis between MedVLP methods using public chest X-ray datasets. Specifically, BenchX is composed of three components: 1) Comprehensive datasets covering nine datasets and four medical tasks; 2) Benchmark suites to standardize data preprocessing, train-test splits, and parameter selection; 3) Unified finetuning protocols that accommodate heterogeneous MedVLP methods for consistent task adaptation in classification, segmentation, and report generation, respectively. Utilizing BenchX, we establish baselines for nine state-of-the-art MedVLP methods and found that the performance of some early MedVLP methods can be enhanced to surpass more recent ones, prompting a revisiting of the developments and conclusions from prior works in MedVLP. Our code are available at https://github.com/yangzhou12/BenchX.
FCA-RAC: First Cycle Annotated Repetitive Action Counting
Jun 18, 2024



Repetitive action counting quantifies the frequency of specific actions performed by individuals. However, existing action-counting datasets have limited action diversity, potentially hampering model performance on unseen actions. To address this issue, we propose a framework called First Cycle Annotated Repetitive Action Counting (FCA-RAC). This framework contains 4 parts: 1) a labeling technique that annotates each training video with the start and end of the first action cycle, along with the total action count. This technique enables the model to capture the correlation between the initial action cycle and subsequent actions; 2) an adaptive sampling strategy that maximizes action information retention by adjusting to the speed of the first annotated action cycle in videos; 3) a Multi-Temporal Granularity Convolution (MTGC) module, that leverages the muli-scale first action as a kernel to convolve across the entire video. This enables the model to capture action variations at different time scales within the video; 4) a strategy called Training Knowledge Augmentation (TKA) that exploits the annotated first action cycle information from the entire dataset. This allows the network to harness shared characteristics across actions effectively, thereby enhancing model performance and generalizability to unseen actions. Experimental results demonstrate that our approach achieves superior outcomes on RepCount-A and related datasets, highlighting the efficacy of our framework in improving model performance on seen and unseen actions. Our paper makes significant contributions to the field of action counting by addressing the limitations of existing datasets and proposing novel techniques for improving model generalizability.
ResNeRF: Geometry-Guided Residual Neural Radiance Field for Indoor Scene Novel View Synthesis
Dec 01, 2022



We represent the ResNeRF, a novel geometry-guided two-stage framework for indoor scene novel view synthesis. Be aware of that a good geometry would greatly boost the performance of novel view synthesis, and to avoid the geometry ambiguity issue, we propose to characterize the density distribution of the scene based on a base density estimated from scene geometry and a residual density parameterized by the geometry. In the first stage, we focus on geometry reconstruction based on SDF representation, which would lead to a good geometry surface of the scene and also a sharp density. In the second stage, the residual density is learned based on the SDF learned in the first stage for encoding more details about the appearance. In this way, our method can better learn the density distribution with the geometry prior for high-fidelity novel view synthesis while preserving the 3D structures. Experiments on large-scale indoor scenes with many less-observed and textureless areas show that with the good 3D surface, our method achieves state-of-the-art performance for novel view synthesis.
Reliable Joint Segmentation of Retinal Edema Lesions in OCT Images
Dec 01, 2022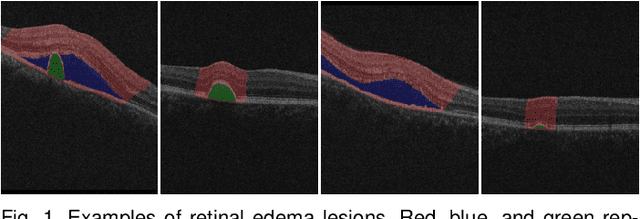

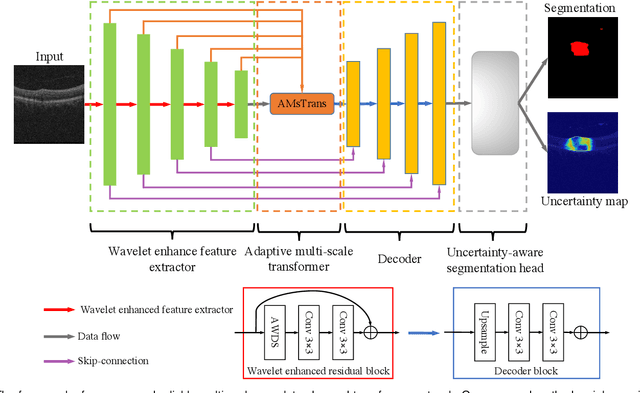
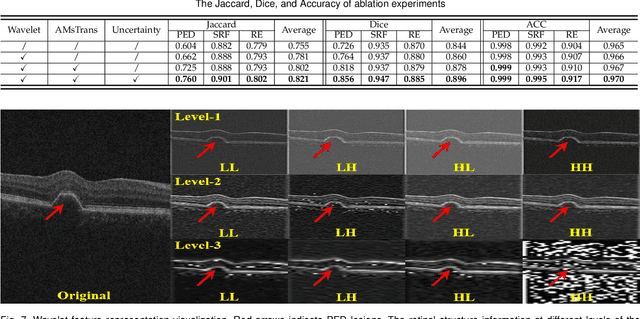
Focusing on the complicated pathological features, such as blurred boundaries, severe scale differences between symptoms, background noise interference, etc., in the task of retinal edema lesions joint segmentation from OCT images and enabling the segmentation results more reliable. In this paper, we propose a novel reliable multi-scale wavelet-enhanced transformer network, which can provide accurate segmentation results with reliability assessment. Specifically, aiming at improving the model's ability to learn the complex pathological features of retinal edema lesions in OCT images, we develop a novel segmentation backbone that integrates a wavelet-enhanced feature extractor network and a multi-scale transformer module of our newly designed. Meanwhile, to make the segmentation results more reliable, a novel uncertainty segmentation head based on the subjective logical evidential theory is introduced to generate the final segmentation results with a corresponding overall uncertainty evaluation score map. We conduct comprehensive experiments on the public database of AI-Challenge 2018 for retinal edema lesions segmentation, and the results show that our proposed method achieves better segmentation accuracy with a high degree of reliability as compared to other state-of-the-art segmentation approaches. The code will be released on: https://github.com/LooKing9218/ReliableRESeg.
Localizing Anatomical Landmarks in Ocular Images using Zoom-In Attentive Networks
Sep 25, 2022Localizing anatomical landmarks are important tasks in medical image analysis. However, the landmarks to be localized often lack prominent visual features. Their locations are elusive and easily confused with the background, and thus precise localization highly depends on the context formed by their surrounding areas. In addition, the required precision is usually higher than segmentation and object detection tasks. Therefore, localization has its unique challenges different from segmentation or detection. In this paper, we propose a zoom-in attentive network (ZIAN) for anatomical landmark localization in ocular images. First, a coarse-to-fine, or "zoom-in" strategy is utilized to learn the contextualized features in different scales. Then, an attentive fusion module is adopted to aggregate multi-scale features, which consists of 1) a co-attention network with a multiple regions-of-interest (ROIs) scheme that learns complementary features from the multiple ROIs, 2) an attention-based fusion module which integrates the multi-ROIs features and non-ROI features. We evaluated ZIAN on two open challenge tasks, i.e., the fovea localization in fundus images and scleral spur localization in AS-OCT images. Experiments show that ZIAN achieves promising performances and outperforms state-of-the-art localization methods. The source code and trained models of ZIAN are available at https://github.com/leixiaofeng-astar/OMIA9-ZIAN.
GAMMA Challenge:Glaucoma grAding from Multi-Modality imAges
Feb 16, 2022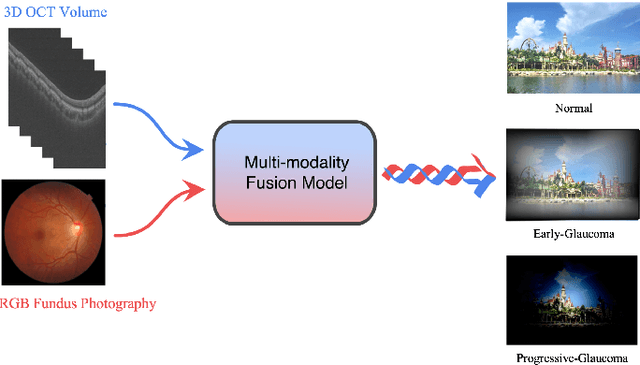
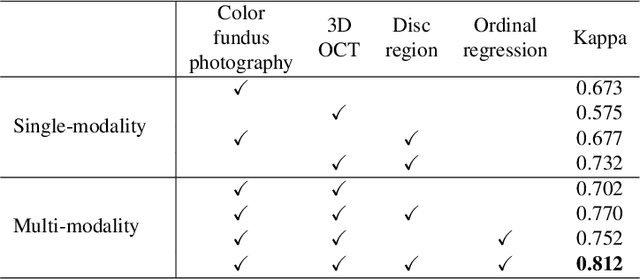
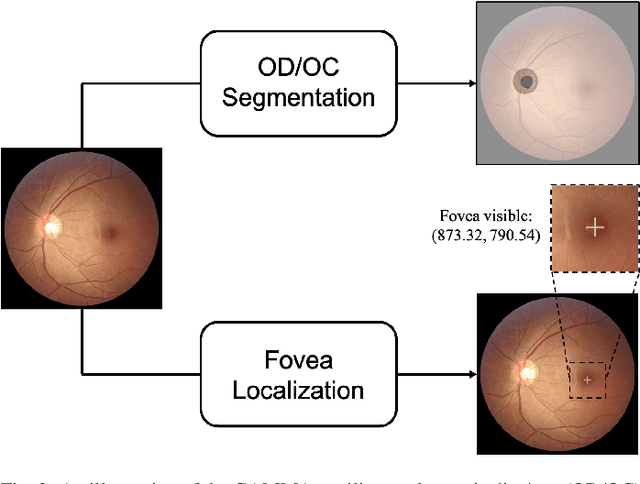
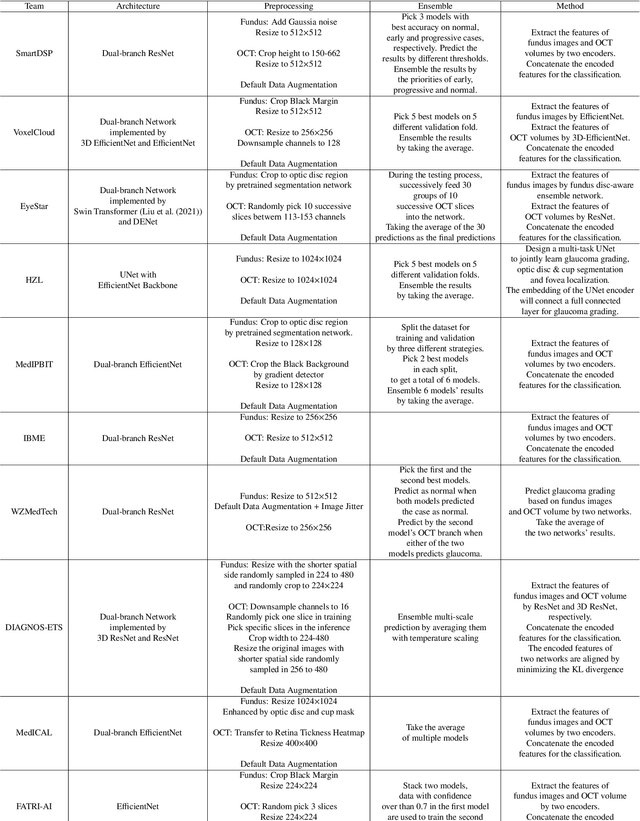
Color fundus photography and Optical Coherence Tomography (OCT) are the two most cost-effective tools for glaucoma screening. Both two modalities of images have prominent biomarkers to indicate glaucoma suspected. Clinically, it is often recommended to take both of the screenings for a more accurate and reliable diagnosis. However, although numerous algorithms are proposed based on fundus images or OCT volumes in computer-aided diagnosis, there are still few methods leveraging both of the modalities for the glaucoma assessment. Inspired by the success of Retinal Fundus Glaucoma Challenge (REFUGE) we held previously, we set up the Glaucoma grAding from Multi-Modality imAges (GAMMA) Challenge to encourage the development of fundus \& OCT-based glaucoma grading. The primary task of the challenge is to grade glaucoma from both the 2D fundus images and 3D OCT scanning volumes. As part of GAMMA, we have publicly released a glaucoma annotated dataset with both 2D fundus color photography and 3D OCT volumes, which is the first multi-modality dataset for glaucoma grading. In addition, an evaluation framework is also established to evaluate the performance of the submitted methods. During the challenge, 1272 results were submitted, and finally, top-10 teams were selected to the final stage. We analysis their results and summarize their methods in the paper. Since all these teams submitted their source code in the challenge, a detailed ablation study is also conducted to verify the effectiveness of the particular modules proposed. We find many of the proposed techniques are practical for the clinical diagnosis of glaucoma. As the first in-depth study of fundus \& OCT multi-modality glaucoma grading, we believe the GAMMA Challenge will be an essential starting point for future research.
Layout-Guided Novel View Synthesis from a Single Indoor Panorama
Mar 31, 2021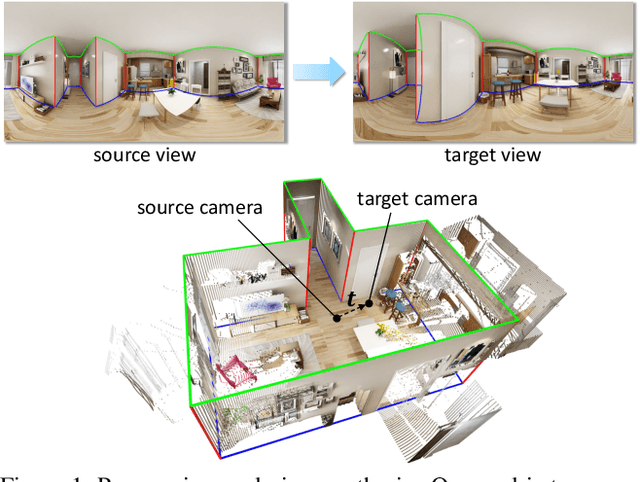
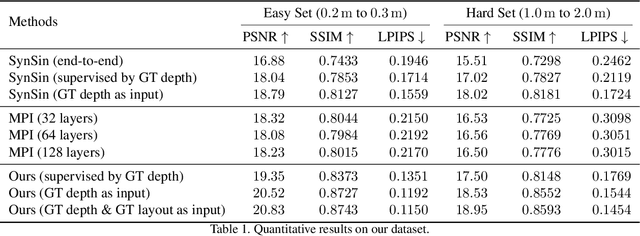

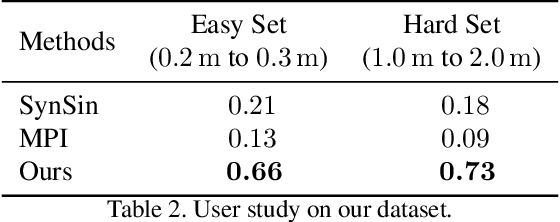
Existing view synthesis methods mainly focus on the perspective images and have shown promising results. However, due to the limited field-of-view of the pinhole camera, the performance quickly degrades when large camera movements are adopted. In this paper, we make the first attempt to generate novel views from a single indoor panorama and take the large camera translations into consideration. To tackle this challenging problem, we first use Convolutional Neural Networks (CNNs) to extract the deep features and estimate the depth map from the source-view image. Then, we leverage the room layout prior, a strong structural constraint of the indoor scene, to guide the generation of target views. More concretely, we estimate the room layout in the source view and transform it into the target viewpoint as guidance. Meanwhile, we also constrain the room layout of the generated target-view images to enforce geometric consistency. To validate the effectiveness of our method, we further build a large-scale photo-realistic dataset containing both small and large camera translations. The experimental results on our challenging dataset demonstrate that our method achieves state-of-the-art performance. The project page is at https://github.com/bluestyle97/PNVS.
Amodal Segmentation Based on Visible Region Segmentation and Shape Prior
Dec 19, 2020

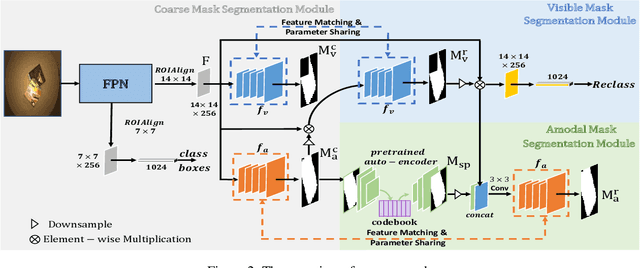

Almost all existing amodal segmentation methods make the inferences of occluded regions by using features corresponding to the whole image. This is against the human's amodal perception, where human uses the visible part and the shape prior knowledge of the target to infer the occluded region. To mimic the behavior of human and solve the ambiguity in the learning, we propose a framework, it firstly estimates a coarse visible mask and a coarse amodal mask. Then based on the coarse prediction, our model infers the amodal mask by concentrating on the visible region and utilizing the shape prior in the memory. In this way, features corresponding to background and occlusion can be suppressed for amodal mask estimation. Consequently, the amodal mask would not be affected by what the occlusion is given the same visible regions. The leverage of shape prior makes the amodal mask estimation more robust and reasonable. Our proposed model is evaluated on three datasets. Experiments show that our proposed model outperforms existing state-of-the-art methods. The visualization of shape prior indicates that the category-specific feature in the codebook has certain interpretability.