 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmodal Segmentation Based on Visible Region Segmentation and Shape Prior
Paper and Code


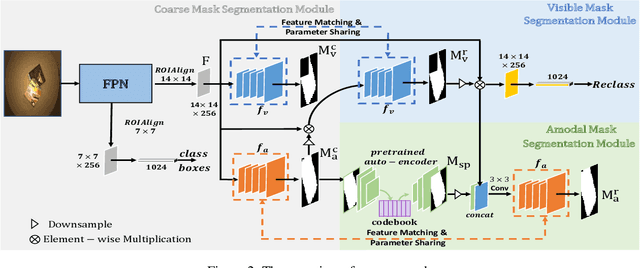

Almost all existing amodal segmentation methods make the inferences of occluded regions by using features corresponding to the whole image. This is against the human's amodal perception, where human uses the visible part and the shape prior knowledge of the target to infer the occluded region. To mimic the behavior of human and solve the ambiguity in the learning, we propose a framework, it firstly estimates a coarse visible mask and a coarse amodal mask. Then based on the coarse prediction, our model infers the amodal mask by concentrating on the visible region and utilizing the shape prior in the memory. In this way, features corresponding to background and occlusion can be suppressed for amodal mask estimation. Consequently, the amodal mask would not be affected by what the occlusion is given the same visible regions. The leverage of shape prior makes the amodal mask estimation more robust and reasonable. Our proposed model is evaluated on three datasets. Experiments show that our proposed model outperforms existing state-of-the-art methods. The visualization of shape prior indicates that the category-specific feature in the codebook has certain interpretability.