 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Language Models with Domain-specific Retrieval Augment Generation: A Case Study on Long-form Consumer Health Question Answering in Ophthalmology
Paper and Code
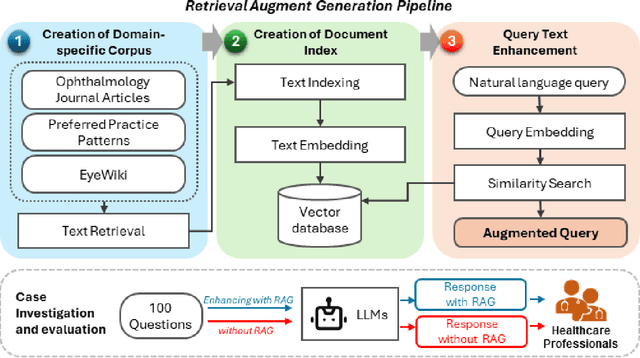

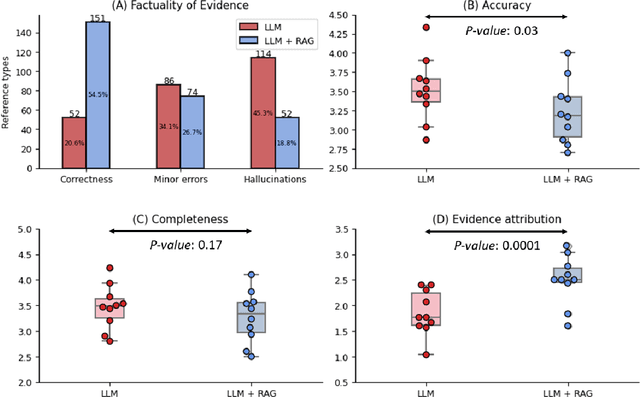

Despite the potential of Large Language Models (LLMs) in medicine, they may generate responses lacking supporting evidence or based on hallucinated evidence. While Retrieval Augment Generation (RAG) is popular to address this issue, few studies implemented and evaluated RAG in downstream domain-specific applications. We developed a RAG pipeline with 70,000 ophthalmology-specific documents that retrieve relevant documents to augment LLMs during inference time. In a case study on long-form consumer health questions, we systematically evaluated the responses including over 500 references of LLMs with and without RAG on 100 questions with 10 healthcare professionals. The evaluation focuses on factuality of evidence, selection and ranking of evidence, attribution of evidence, and answer accuracy and completeness. LLMs without RAG provided 252 references in total. Of which, 45.3% hallucinated, 34.1% consisted of minor errors, and 20.6% were correct. In contrast, LLMs with RAG significantly improved accuracy (54.5% being correct) and reduced error rates (18.8% with minor hallucinations and 26.7% with errors). 62.5% of the top 10 documents retrieved by RAG were selected as the top references in the LLM response, with an average ranking of 4.9. The use of RAG also improved evidence attribution (increasing from 1.85 to 2.49 on a 5-point scale, P<0.001), albeit with slight decreases in accuracy (from 3.52 to 3.23, P=0.03) and completeness (from 3.47 to 3.27, P=0.17). The results demonstrate that LLMs frequently exhibited hallucinated and erroneous evidence in the responses, raising concerns for downstream applications in the medical domain. RAG substantially reduced the proportion of such evidence but encountered challenges.