 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Retrieval-Augmented Generation for Medicine: A Large-Scale, Systematic Expert Evaluation and Practical Insights
Nov 10, 2025Large language models (LLMs) are transforming the landscape of medicine, yet two fundamental challenges persist: keeping up with rapidly evolving medical knowledge and providing verifiable, evidence-grounded reasoning. Retrieval-augmented generation (RAG) has been widely adopted to address these limitations by supplementing model outputs with retrieved evidence. However, whether RAG reliably achieves these goals remains unclear. Here, we present the most comprehensive expert evaluation of RAG in medicine to date. Eighteen medical experts contributed a total of 80,502 annotations, assessing 800 model outputs generated by GPT-4o and Llama-3.1-8B across 200 real-world patient and USMLE-style queries. We systematically decomposed the RAG pipeline into three components: (i) evidence retrieval (relevance of retrieved passages), (ii) evidence selection (accuracy of evidence usage), and (iii) response generation (factuality and completeness of outputs). Contrary to expectation, standard RAG often degraded performance: only 22% of top-16 passages were relevant, evidence selection remained weak (precision 41-43%, recall 27-49%), and factuality and completeness dropped by up to 6% and 5%, respectively, compared with non-RAG variants. Retrieval and evidence selection remain key failure points for the model, contributing to the overall performance drop. We further show that simple yet effective strategies, including evidence filtering and query reformulation, substantially mitigate these issues, improving performance on MedMCQA and MedXpertQA by up to 12% and 8.2%, respectively. These findings call for re-examining RAG's role in medicine and highlight the importance of stage-aware evaluation and deliberate system design for reliable medical LLM applications.
Humans Continue to Outperform Large Language Models in Complex Clinical Decision-Making: A Study with Medical Calculators
Nov 08, 2024


Although large language models (LLMs) have been assessed for general medical knowledge using medical licensing exams, their ability to effectively support clinical decision-making tasks, such as selecting and using medical calculators, remains uncertain. Here, we evaluate the capability of both medical trainees and LLMs to recommend medical calculators in response to various multiple-choice clinical scenarios such as risk stratification, prognosis, and disease diagnosis. We assessed eight LLMs, including open-source, proprietary, and domain-specific models, with 1,009 question-answer pairs across 35 clinical calculators and measured human performance on a subset of 100 questions. While the highest-performing LLM, GPT-4o, provided an answer accuracy of 74.3% (CI: 71.5-76.9%), human annotators, on average, outperformed LLMs with an accuracy of 79.5% (CI: 73.5-85.0%). With error analysis showing that the highest-performing LLMs continue to make mistakes in comprehension (56.6%) and calculator knowledge (8.1%), our findings emphasize that humans continue to surpass LLMs on complex clinical tasks such as calculator recommendation.
Demystifying Large Language Models for Medicine: A Primer
Oct 24, 2024



Large language models (LLMs) represent a transformative class of AI tools capable of revolutionizing various aspects of healthcare by generating human-like responses across diverse contexts and adapting to novel tasks following human instructions. Their potential application spans a broad range of medical tasks, such as clinical documentation, matching patients to clinical trials, and answering medical questions. In this primer paper, we propose an actionable guideline to help healthcare professionals more efficiently utilize LLMs in their work, along with a set of best practices. This approach consists of several main phases, including formulating the task, choosing LLMs, prompt engineering, fine-tuning, and deployment. We start with the discussion of critical considerations in identifying healthcare tasks that align with the core capabilities of LLMs and selecting models based on the selected task and data, performance requirements, and model interface. We then review the strategies, such as prompt engineering and fine-tuning, to adapt standard LLMs to specialized medical tasks. Deployment considerations, including regulatory compliance, ethical guidelines, and continuous monitoring for fairness and bias, are also discussed. By providing a structured step-by-step methodology, this tutorial aims to equip healthcare professionals with the tools necessary to effectively integrate LLMs into clinical practice, ensuring that these powerful technologies are applied in a safe, reliable, and impactful manner.
Enhancing Large Language Models with Domain-specific Retrieval Augment Generation: A Case Study on Long-form Consumer Health Question Answering in Ophthalmology
Sep 20, 2024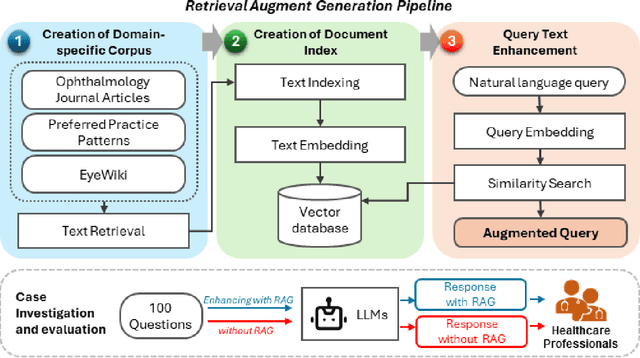

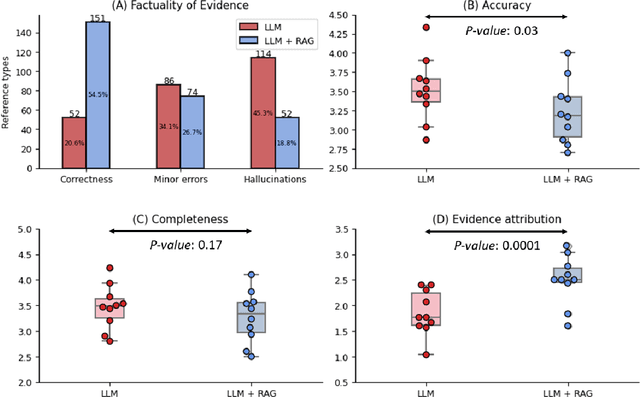

Despite the potential of Large Language Models (LLMs) in medicine, they may generate responses lacking supporting evidence or based on hallucinated evidence. While Retrieval Augment Generation (RAG) is popular to address this issue, few studies implemented and evaluated RAG in downstream domain-specific applications. We developed a RAG pipeline with 70,000 ophthalmology-specific documents that retrieve relevant documents to augment LLMs during inference time. In a case study on long-form consumer health questions, we systematically evaluated the responses including over 500 references of LLMs with and without RAG on 100 questions with 10 healthcare professionals. The evaluation focuses on factuality of evidence, selection and ranking of evidence, attribution of evidence, and answer accuracy and completeness. LLMs without RAG provided 252 references in total. Of which, 45.3% hallucinated, 34.1% consisted of minor errors, and 20.6% were correct. In contrast, LLMs with RAG significantly improved accuracy (54.5% being correct) and reduced error rates (18.8% with minor hallucinations and 26.7% with errors). 62.5% of the top 10 documents retrieved by RAG were selected as the top references in the LLM response, with an average ranking of 4.9. The use of RAG also improved evidence attribution (increasing from 1.85 to 2.49 on a 5-point scale, P<0.001), albeit with slight decreases in accuracy (from 3.52 to 3.23, P=0.03) and completeness (from 3.47 to 3.27, P=0.17). The results demonstrate that LLMs frequently exhibited hallucinated and erroneous evidence in the responses, raising concerns for downstream applications in the medical domain. RAG substantially reduced the proportion of such evidence but encountered challenges.
MedCalc-Bench: Evaluating Large Language Models for Medical Calculations
Jun 17, 2024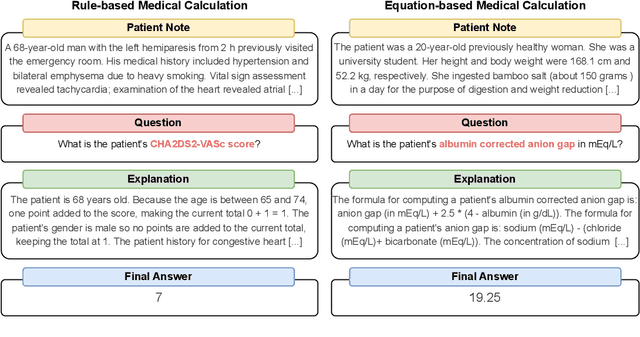
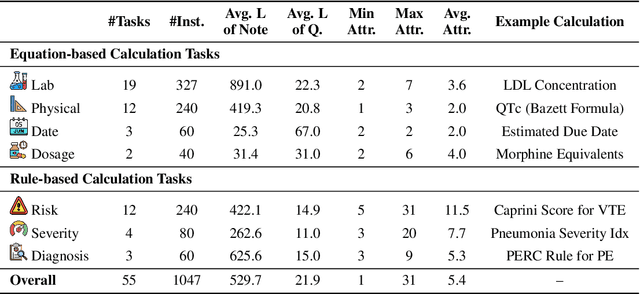
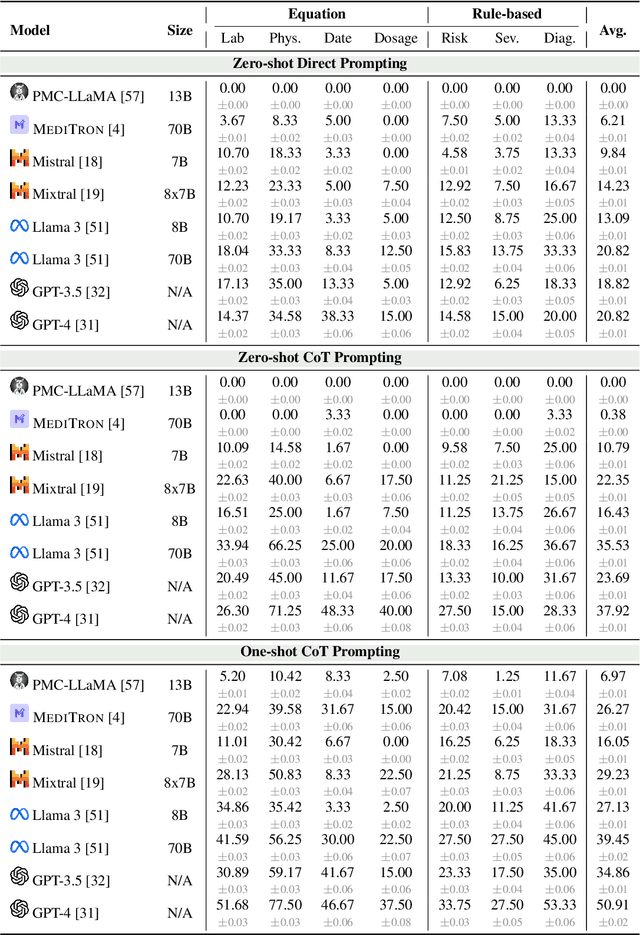
As opposed to evaluating computation and logic-based reasoning, current bench2 marks for evaluating large language models (LLMs) in medicine are primarily focused on question-answering involving domain knowledge and descriptive rea4 soning. While such qualitative capabilities are vital to medical diagnosis, in real5 world scenarios, doctors frequently use clinical calculators that follow quantitative equations and rule-based reasoning paradigms for evidence-based decision support. To this end, we propose MedCalc-Bench, a first-of-its-kind dataset focused on evaluating the medical calculation capability of LLMs. MedCalc-Bench contains an evaluation set of over 1000 manually reviewed instances from 55 different medical calculation tasks. Each instance in MedCalc-Bench consists of a patient note, a question requesting to compute a specific medical value, a ground truth answer, and a step-by-step explanation showing how the answer is obtained. While our evaluation results show the potential of LLMs in this area, none of them are effective enough for clinical settings. Common issues include extracting the incorrect entities, not using the correct equation or rules for a calculation task, or incorrectly performing the arithmetic for the computation. We hope our study highlights the quantitative knowledge and reasoning gaps in LLMs within medical settings, encouraging future improvements of LLMs for various clinical calculation tasks.