 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-Bench: A Benchmark for Multimodal Lesion Understanding in Computed Tomography
Feb 16, 2026Artificial intelligence (AI) can automatically delineate lesions on computed tomography (CT) and generate radiology report content, yet progress is limited by the scarcity of publicly available CT datasets with lesion-level annotations. To bridge this gap, we introduce CT-Bench, a first-of-its-kind benchmark dataset comprising two components: a Lesion Image and Metadata Set containing 20,335 lesions from 7,795 CT studies with bounding boxes, descriptions, and size information, and a multitask visual question answering benchmark with 2,850 QA pairs covering lesion localization, description, size estimation, and attribute categorization. Hard negative examples are included to reflect real-world diagnostic challenges. We evaluate multiple state-of-the-art multimodal models, including vision-language and medical CLIP variants, by comparing their performance to radiologist assessments, demonstrating the value of CT-Bench as a comprehensive benchmark for lesion analysis. Moreover, fine-tuning models on the Lesion Image and Metadata Set yields significant performance gains across both components, underscoring the clinical utility of CT-Bench.
Text Embedded Swin-UMamba for DeepLesion Segmentation
Aug 08, 2025Segmentation of lesions on CT enables automatic measurement for clinical assessment of chronic diseases (e.g., lymphoma). Integrating large language models (LLMs) into the lesion segmentation workflow offers the potential to combine imaging features with descriptions of lesion characteristics from the radiology reports. In this study, we investigate the feasibility of integrating text into the Swin-UMamba architecture for the task of lesion segmentation. The publicly available ULS23 DeepLesion dataset was used along with short-form descriptions of the findings from the reports. On the test dataset, a high Dice Score of 82% and low Hausdorff distance of 6.58 (pixels) was obtained for lesion segmentation. The proposed Text-Swin-UMamba model outperformed prior approaches: 37% improvement over the LLM-driven LanGuideMedSeg model (p < 0.001),and surpassed the purely image-based xLSTM-UNet and nnUNet models by 1.74% and 0.22%, respectively. The dataset and code can be accessed at https://github.com/ruida/LLM-Swin-UMamba
Knowledge-guided Contextual Gene Set Analysis Using Large Language Models
Jun 04, 2025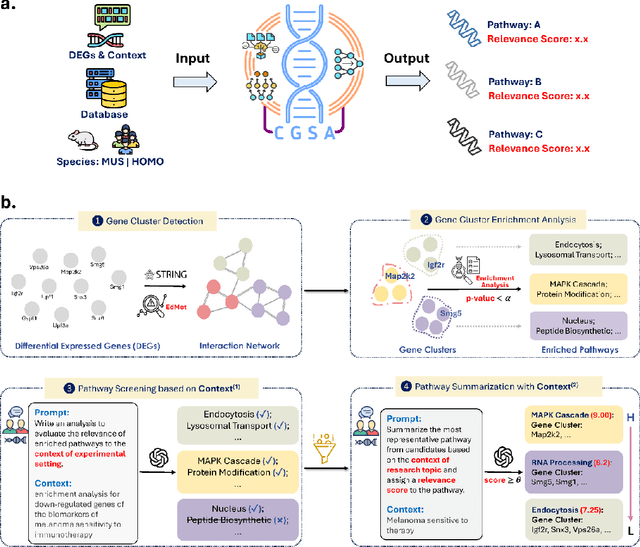

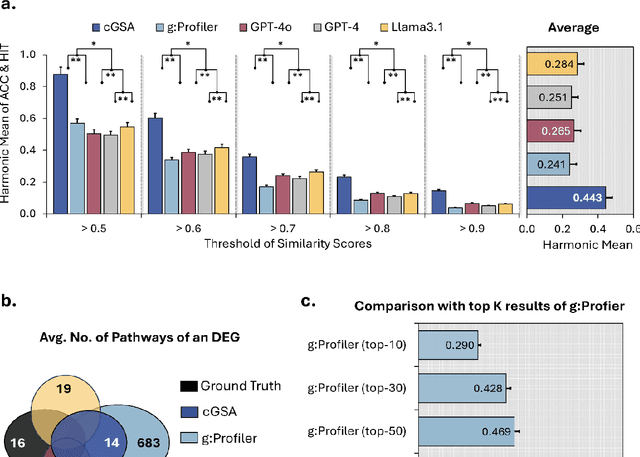

Gene set analysis (GSA) is a foundational approach for interpreting genomic data of diseases by linking genes to biological processes. However, conventional GSA methods overlook clinical context of the analyses, often generating long lists of enriched pathways with redundant, nonspecific, or irrelevant results. Interpreting these requires extensive, ad-hoc manual effort, reducing both reliability and reproducibility. To address this limitation, we introduce cGSA, a novel AI-driven framework that enhances GSA by incorporating context-aware pathway prioritization. cGSA integrates gene cluster detection, enrichment analysis, and large language models to identify pathways that are not only statistically significant but also biologically meaningful. Benchmarking on 102 manually curated gene sets across 19 diseases and ten disease-related biological mechanisms shows that cGSA outperforms baseline methods by over 30%, with expert validation confirming its increased precision and interpretability. Two independent case studies in melanoma and breast cancer further demonstrate its potential to uncover context-specific insights and support targeted hypothesis generation.
LLM-CoT Enhanced Graph Neural Recommendation with Harmonized Group Policy Optimization
May 18, 2025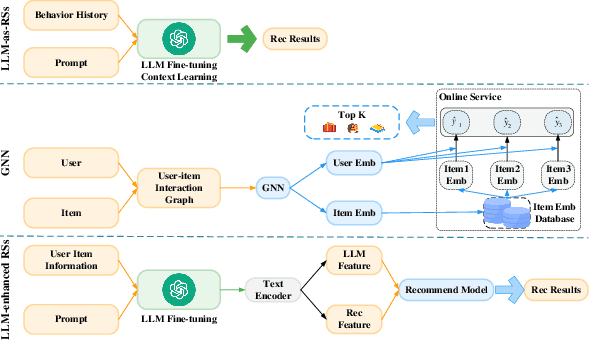
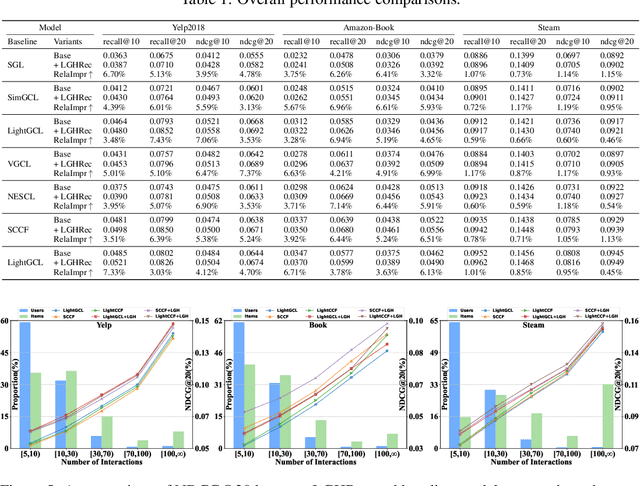


Graph neural networks (GNNs) have advanced recommender systems by modeling interaction relationships. However, existing graph-based recommenders rely on sparse ID features and do not fully exploit textual information, resulting in low information density within representations. Furthermore, graph contrastive learning faces challenges. Random negative sampling can introduce false negative samples, while fixed temperature coefficients cannot adapt to the heterogeneity of different nodes. In addition, current efforts to enhance recommendations with large language models (LLMs) have not fully utilized their Chain-of-Thought (CoT) reasoning capabilities to guide representation learning. To address these limitations, we introduces LGHRec (LLM-CoT Enhanced Graph Neural Recommendation with Harmonized Group Policy Optimization). This framework leverages the CoT reasoning ability of LLMs to generate semantic IDs, enriching reasoning processes and improving information density and semantic quality of representations. Moreover, we design a reinforcement learning algorithm, Harmonized Group Policy Optimization (HGPO), to optimize negative sampling strategies and temperature coefficients in contrastive learning. This approach enhances long-tail recommendation performance and ensures optimization consistency across different groups. Experimental results on three datasets demonstrate that LGHRec improves representation quality through semantic IDs generated by LLM's CoT reasoning and effectively boosts contrastive learning with HGPO. Our method outperforms several baseline models. The code is available at: https://anonymous.4open.science/r/LLM-Rec.
Beyond Multiple-Choice Accuracy: Real-World Challenges of Implementing Large Language Models in Healthcare
Oct 24, 2024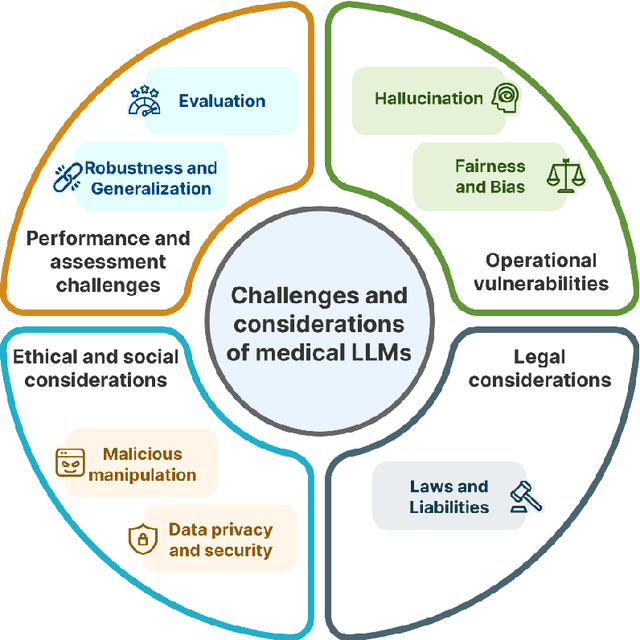
Large Language Models (LLMs) have gained significant attention in the medical domain for their human-level capabilities, leading to increased efforts to explore their potential in various healthcare applications. However, despite such a promising future, there are multiple challenges and obstacles that remain for their real-world uses in practical settings. This work discusses key challenges for LLMs in medical applications from four unique aspects: operational vulnerabilities, ethical and social considerations, performance and assessment difficulties, and legal and regulatory compliance. Addressing these challenges is crucial for leveraging LLMs to their full potential and ensuring their responsible integration into healthcare.
Demystifying Large Language Models for Medicine: A Primer
Oct 24, 2024



Large language models (LLMs) represent a transformative class of AI tools capable of revolutionizing various aspects of healthcare by generating human-like responses across diverse contexts and adapting to novel tasks following human instructions. Their potential application spans a broad range of medical tasks, such as clinical documentation, matching patients to clinical trials, and answering medical questions. In this primer paper, we propose an actionable guideline to help healthcare professionals more efficiently utilize LLMs in their work, along with a set of best practices. This approach consists of several main phases, including formulating the task, choosing LLMs, prompt engineering, fine-tuning, and deployment. We start with the discussion of critical considerations in identifying healthcare tasks that align with the core capabilities of LLMs and selecting models based on the selected task and data, performance requirements, and model interface. We then review the strategies, such as prompt engineering and fine-tuning, to adapt standard LLMs to specialized medical tasks. Deployment considerations, including regulatory compliance, ethical guidelines, and continuous monitoring for fairness and bias, are also discussed. By providing a structured step-by-step methodology, this tutorial aims to equip healthcare professionals with the tools necessary to effectively integrate LLMs into clinical practice, ensuring that these powerful technologies are applied in a safe, reliable, and impactful manner.
Write Summary Step-by-Step: A Pilot Study of Stepwise Summarization
Jun 08, 2024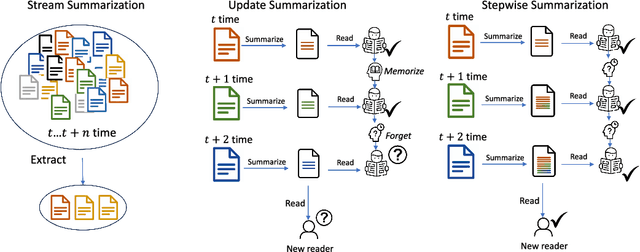

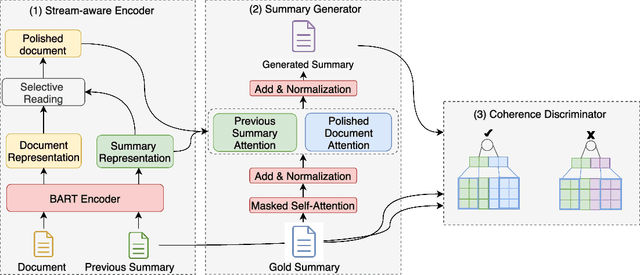
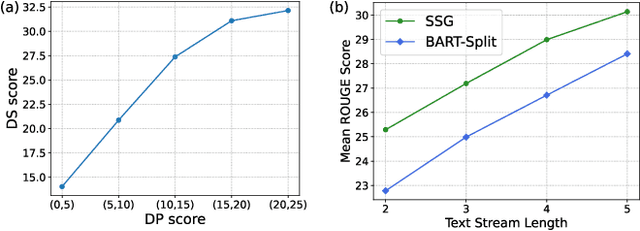
Nowadays, neural text generation has made tremendous progress in abstractive summarization tasks. However, most of the existing summarization models take in the whole document all at once, which sometimes cannot meet the needs in practice. Practically, social text streams such as news events and tweets keep growing from time to time, and can only be fed to the summarization system step by step. Hence, in this paper, we propose the task of Stepwise Summarization, which aims to generate a new appended summary each time a new document is proposed. The appended summary should not only summarize the newly added content but also be coherent with the previous summary, to form an up-to-date complete summary. To tackle this challenge, we design an adversarial learning model, named Stepwise Summary Generator (SSG). First, SSG selectively processes the new document under the guidance of the previous summary, obtaining polished document representation. Next, SSG generates the summary considering both the previous summary and the document. Finally, a convolutional-based discriminator is employed to determine whether the newly generated summary is coherent with the previous summary. For the experiment, we extend the traditional two-step update summarization setting to a multi-step stepwise setting, and re-propose a large-scale stepwise summarization dataset based on a public story generation dataset. Extensive experiments on this dataset show that SSG achieves state-of-the-art performance in terms of both automatic metrics and human evaluations. Ablation studies demonstrate the effectiveness of each module in our framework. We also discuss the benefits and limitations of recent large language models on this task.
Flexible and Adaptable Summarization via Expertise Separation
Jun 08, 2024

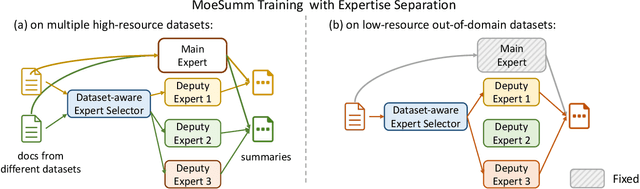
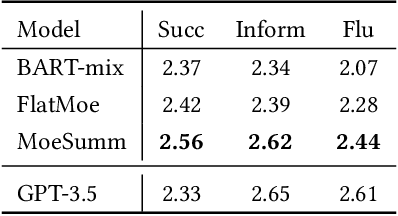
A proficient summarization model should exhibit both flexibility -- the capacity to handle a range of in-domain summarization tasks, and adaptability -- the competence to acquire new knowledge and adjust to unseen out-of-domain tasks. Unlike large language models (LLMs) that achieve this through parameter scaling, we propose a more parameter-efficient approach in this study. Our motivation rests on the principle that the general summarization ability to capture salient information can be shared across different tasks, while the domain-specific summarization abilities need to be distinct and tailored. Concretely, we propose MoeSumm, a Mixture-of-Expert Summarization architecture, which utilizes a main expert for gaining the general summarization capability and deputy experts that selectively collaborate to meet specific summarization task requirements. We further propose a max-margin loss to stimulate the separation of these abilities. Our model's distinct separation of general and domain-specific summarization abilities grants it with notable flexibility and adaptability, all while maintaining parameter efficiency. MoeSumm achieves flexibility by managing summarization across multiple domains with a single model, utilizing a shared main expert and selected deputy experts. It exhibits adaptability by tailoring deputy experts to cater to out-of-domain few-shot and zero-shot scenarios. Experimental results on 11 datasets show the superiority of our model compared with recent baselines and LLMs. We also provide statistical and visual evidence of the distinct separation of the two abilities in MoeSumm (https://github.com/iriscxy/MoE_Summ).
Shadow and Light: Digitally Reconstructed Radiographs for Disease Classification
Jun 06, 2024



In this paper, we introduce DRR-RATE, a large-scale synthetic chest X-ray dataset derived from the recently released CT-RATE dataset. DRR-RATE comprises of 50,188 frontal Digitally Reconstructed Radiographs (DRRs) from 21,304 unique patients. Each image is paired with a corresponding radiology text report and binary labels for 18 pathology classes. Given the controllable nature of DRR generation, it facilitates the inclusion of lateral view images and images from any desired viewing position. This opens up avenues for research into new and novel multimodal applications involving paired CT, X-ray images from various views, text, and binary labels. We demonstrate the applicability of DRR-RATE alongside existing large-scale chest X-ray resources, notably the CheXpert dataset and CheXnet model. Experiments demonstrate that CheXnet, when trained and tested on the DRR-RATE dataset, achieves sufficient to high AUC scores for the six common pathologies cited in common literature: Atelectasis, Cardiomegaly, Consolidation, Lung Lesion, Lung Opacity, and Pleural Effusion. Additionally, CheXnet trained on the CheXpert dataset can accurately identify several pathologies, even when operating out of distribution. This confirms that the generated DRR images effectively capture the essential pathology features from CT images. The dataset and labels are publicly accessible at https://huggingface.co/datasets/farrell236/DRR-RATE.
GeneAgent: Self-verification Language Agent for Gene Set Knowledge Discovery using Domain Databases
May 25, 2024



Gene set knowledge discovery is essential for advancing human functional genomics. Recent studies have shown promising performance by harnessing the power of Large Language Models (LLMs) on this task. Nonetheless, their results are subject to several limitations common in LLMs such as hallucinations. In response, we present GeneAgent, a first-of-its-kind language agent featuring self-verification capability. It autonomously interacts with various biological databases and leverages relevant domain knowledge to improve accuracy and reduce hallucination occurrences. Benchmarking on 1,106 gene sets from different sources, GeneAgent consistently outperforms standard GPT-4 by a significant margin. Moreover, a detailed manual review confirms the effectiveness of the self-verification module in minimizing hallucinations and generating more reliable analytical narratives. To demonstrate its practical utility, we apply GeneAgent to seven novel gene sets derived from mouse B2905 melanoma cell lines, with expert evaluations showing that GeneAgent offers novel insights into gene functions and subsequently expedites knowledge discovery.