 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization in Large Language Models in Medicine: Prevalence, Characteristics, and Implications
Sep 10, 2025Large Language Models (LLMs) have demonstrated significant potential in medicine. To date, LLMs have been widely applied to tasks such as diagnostic assistance, medical question answering, and clinical information synthesis. However, a key open question remains: to what extent do LLMs memorize medical training data. In this study, we present the first comprehensive evaluation of memorization of LLMs in medicine, assessing its prevalence (how frequently it occurs), characteristics (what is memorized), volume (how much content is memorized), and potential downstream impacts (how memorization may affect medical applications). We systematically analyze common adaptation scenarios: (1) continued pretraining on medical corpora, (2) fine-tuning on standard medical benchmarks, and (3) fine-tuning on real-world clinical data, including over 13,000 unique inpatient records from Yale New Haven Health System. The results demonstrate that memorization is prevalent across all adaptation scenarios and significantly higher than reported in the general domain. Memorization affects both the development and adoption of LLMs in medicine and can be categorized into three types: beneficial (e.g., accurate recall of clinical guidelines and biomedical references), uninformative (e.g., repeated disclaimers or templated medical document language), and harmful (e.g., regeneration of dataset-specific or sensitive clinical content). Based on these findings, we offer practical recommendations to facilitate beneficial memorization that enhances domain-specific reasoning and factual accuracy, minimize uninformative memorization to promote deeper learning beyond surface-level patterns, and mitigate harmful memorization to prevent the leakage of sensitive or identifiable patient information.
Text Embedded Swin-UMamba for DeepLesion Segmentation
Aug 08, 2025Segmentation of lesions on CT enables automatic measurement for clinical assessment of chronic diseases (e.g., lymphoma). Integrating large language models (LLMs) into the lesion segmentation workflow offers the potential to combine imaging features with descriptions of lesion characteristics from the radiology reports. In this study, we investigate the feasibility of integrating text into the Swin-UMamba architecture for the task of lesion segmentation. The publicly available ULS23 DeepLesion dataset was used along with short-form descriptions of the findings from the reports. On the test dataset, a high Dice Score of 82% and low Hausdorff distance of 6.58 (pixels) was obtained for lesion segmentation. The proposed Text-Swin-UMamba model outperformed prior approaches: 37% improvement over the LLM-driven LanGuideMedSeg model (p < 0.001),and surpassed the purely image-based xLSTM-UNet and nnUNet models by 1.74% and 0.22%, respectively. The dataset and code can be accessed at https://github.com/ruida/LLM-Swin-UMamba
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
MedCite: Can Language Models Generate Verifiable Text for Medicine?
Jun 07, 2025Existing LLM-based medical question-answering systems lack citation generation and evaluation capabilities, raising concerns about their adoption in practice. In this work, we introduce \name, the first end-to-end framework that facilitates the design and evaluation of citation generation with LLMs for medical tasks. Meanwhile, we introduce a novel multi-pass retrieval-citation method that generates high-quality citations. Our evaluation highlights the challenges and opportunities of citation generation for medical tasks, while identifying important design choices that have a significant impact on the final citation quality. Our proposed method achieves superior citation precision and recall improvements compared to strong baseline methods, and we show that evaluation results correlate well with annotation results from professional experts.
Knowledge-guided Contextual Gene Set Analysis Using Large Language Models
Jun 04, 2025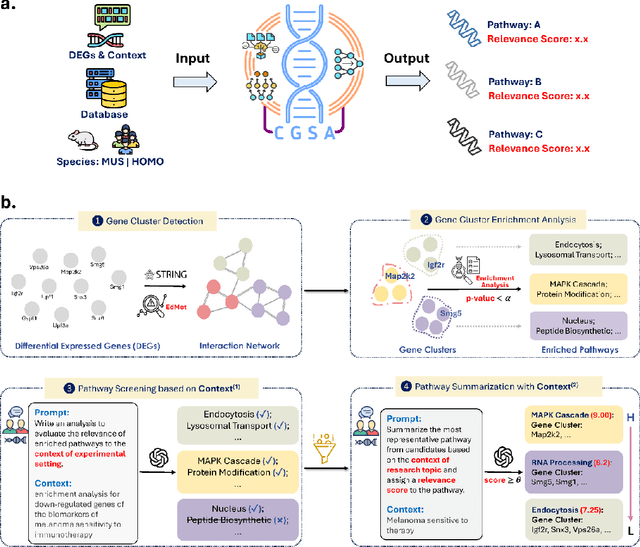

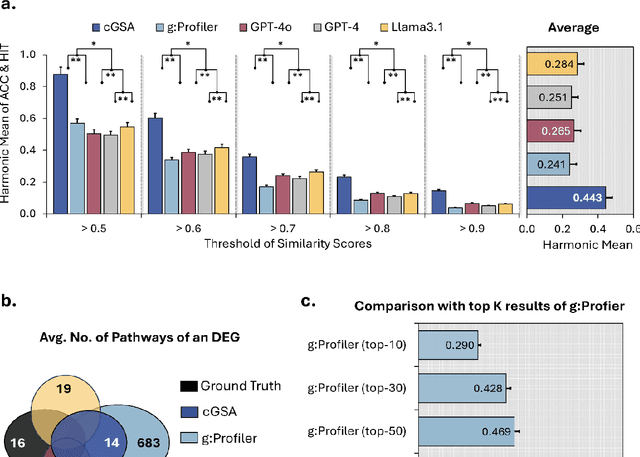

Gene set analysis (GSA) is a foundational approach for interpreting genomic data of diseases by linking genes to biological processes. However, conventional GSA methods overlook clinical context of the analyses, often generating long lists of enriched pathways with redundant, nonspecific, or irrelevant results. Interpreting these requires extensive, ad-hoc manual effort, reducing both reliability and reproducibility. To address this limitation, we introduce cGSA, a novel AI-driven framework that enhances GSA by incorporating context-aware pathway prioritization. cGSA integrates gene cluster detection, enrichment analysis, and large language models to identify pathways that are not only statistically significant but also biologically meaningful. Benchmarking on 102 manually curated gene sets across 19 diseases and ten disease-related biological mechanisms shows that cGSA outperforms baseline methods by over 30%, with expert validation confirming its increased precision and interpretability. Two independent case studies in melanoma and breast cancer further demonstrate its potential to uncover context-specific insights and support targeted hypothesis generation.
TrialPanorama: Database and Benchmark for Systematic Review and Design of Clinical Trials
May 22, 2025Developing artificial intelligence (AI) for vertical domains requires a solid data foundation for both training and evaluation. In this work, we introduce TrialPanorama, a large-scale, structured database comprising 1,657,476 clinical trial records aggregated from 15 global sources. The database captures key aspects of trial design and execution, including trial setups, interventions, conditions, biomarkers, and outcomes, and links them to standard biomedical ontologies such as DrugBank and MedDRA. This structured and ontology-grounded design enables TrialPanorama to serve as a unified, extensible resource for a wide range of clinical trial tasks, including trial planning, design, and summarization. To demonstrate its utility, we derive a suite of benchmark tasks directly from the TrialPanorama database. The benchmark spans eight tasks across two categories: three for systematic review (study search, study screening, and evidence summarization) and five for trial design (arm design, eligibility criteria, endpoint selection, sample size estimation, and trial completion assessment). The experiments using five state-of-the-art large language models (LLMs) show that while general-purpose LLMs exhibit some zero-shot capability, their performance is still inadequate for high-stakes clinical trial workflows. We release TrialPanorama database and the benchmark to facilitate further research on AI for clinical trials.
Recommending Clinical Trials for Online Patient Cases using Artificial Intelligence
Apr 15, 2025


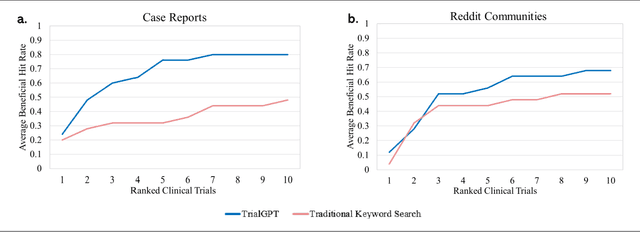
Clinical trials are crucial for assessing new treatments; however, recruitment challenges - such as limited awareness, complex eligibility criteria, and referral barriers - hinder their success. With the growth of online platforms, patients increasingly turn to social media and health communities for support, research, and advocacy, expanding recruitment pools and established enrollment pathways. Recognizing this potential, we utilized TrialGPT, a framework that leverages a large language model (LLM) as its backbone, to match 50 online patient cases (collected from published case reports and a social media website) to clinical trials and evaluate performance against traditional keyword-based searches. Our results show that TrialGPT outperforms traditional methods by 46% in identifying eligible trials, with each patient, on average, being eligible for around 7 trials. Additionally, our outreach efforts to case authors and trial organizers regarding these patient-trial matches yielded highly positive feedback, which we present from both perspectives.
Universal Lymph Node Detection in Multiparametric MRI with Selective Augmentation
Apr 07, 2025Robust localization of lymph nodes (LNs) in multiparametric MRI (mpMRI) is critical for the assessment of lymphadenopathy. Radiologists routinely measure the size of LN to distinguish benign from malignant nodes, which would require subsequent cancer staging. Sizing is a cumbersome task compounded by the diverse appearances of LNs in mpMRI, which renders their measurement difficult. Furthermore, smaller and potentially metastatic LNs could be missed during a busy clinical day. To alleviate these imaging and workflow problems, we propose a pipeline to universally detect both benign and metastatic nodes in the body for their ensuing measurement. The recently proposed VFNet neural network was employed to identify LN in T2 fat suppressed and diffusion weighted imaging (DWI) sequences acquired by various scanners with a variety of exam protocols. We also use a selective augmentation technique known as Intra-Label LISA (ILL) to diversify the input data samples the model sees during training, such that it improves its robustness during the evaluation phase. We achieved a sensitivity of $\sim$83\% with ILL vs. $\sim$80\% without ILL at 4 FP/vol. Compared with current LN detection approaches evaluated on mpMRI, we show a sensitivity improvement of $\sim$9\% at 4 FP/vol.
RAG-Gym: Optimizing Reasoning and Search Agents with Process Supervision
Feb 19, 2025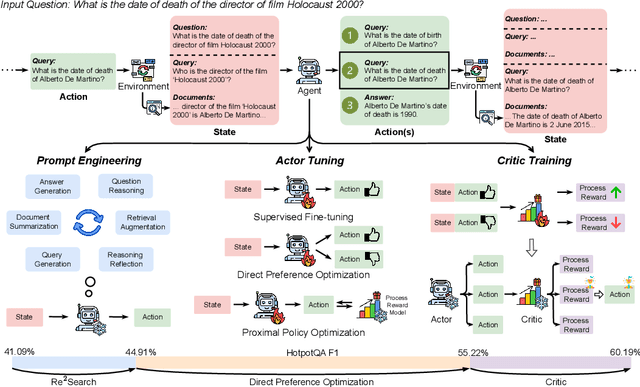

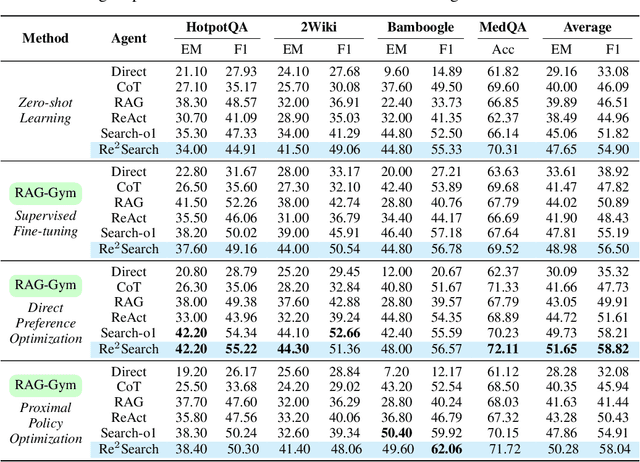
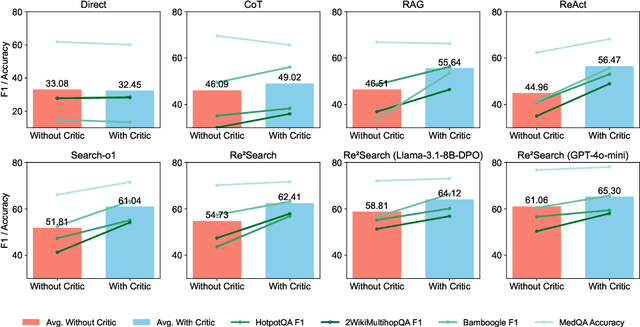
Retrieval-augmented generation (RAG) has shown great potential for knowledge-intensive tasks, but its traditional architectures rely on static retrieval, limiting their effectiveness for complex questions that require sequential information-seeking. While agentic reasoning and search offer a more adaptive approach, most existing methods depend heavily on prompt engineering. In this work, we introduce RAG-Gym, a unified optimization framework that enhances information-seeking agents through fine-grained process supervision at each search step. We also propose ReSearch, a novel agent architecture that synergizes answer reasoning and search query generation within the RAG-Gym framework. Experiments on four challenging datasets show that RAG-Gym improves performance by up to 25.6\% across various agent architectures, with ReSearch consistently outperforming existing baselines. Further analysis highlights the effectiveness of advanced LLMs as process reward judges and the transferability of trained reward models as verifiers for different LLMs. Additionally, we examine the scaling properties of training and inference in agentic RAG. The project homepage is available at https://rag-gym.github.io/.
A foundation model for human-AI collaboration in medical literature mining
Jan 27, 2025



Systematic literature review is essential for evidence-based medicine, requiring comprehensive analysis of clinical trial publications. However, the application of artificial intelligence (AI) models for medical literature mining has been limited by insufficient training and evaluation across broad therapeutic areas and diverse tasks. Here, we present LEADS, an AI foundation model for study search, screening, and data extraction from medical literature. The model is trained on 633,759 instruction data points in LEADSInstruct, curated from 21,335 systematic reviews, 453,625 clinical trial publications, and 27,015 clinical trial registries. We showed that LEADS demonstrates consistent improvements over four cutting-edge generic large language models (LLMs) on six tasks. Furthermore, LEADS enhances expert workflows by providing supportive references following expert requests, streamlining processes while maintaining high-quality results. A study with 16 clinicians and medical researchers from 14 different institutions revealed that experts collaborating with LEADS achieved a recall of 0.81 compared to 0.77 experts working alone in study selection, with a time savings of 22.6%. In data extraction tasks, experts using LEADS achieved an accuracy of 0.85 versus 0.80 without using LEADS, alongside a 26.9% time savings. These findings highlight the potential of specialized medical literature foundation models to outperform generic models, delivering significant quality and efficiency benefits when integrated into expert workflows for medical literature mining.