 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA MapReduce Approach to Effectively Utilize Long Context Information in Retrieval Augmented Language Models
Dec 17, 2024



While holding great promise for improving and facilitating healthcare, large language models (LLMs) struggle to produce up-to-date responses on evolving topics due to outdated knowledge or hallucination. Retrieval-augmented generation (RAG) is a pivotal innovation that improves the accuracy and relevance of LLM responses by integrating LLMs with a search engine and external sources of knowledge. However, the quality of RAG responses can be largely impacted by the rank and density of key information in the retrieval results, such as the "lost-in-the-middle" problem. In this work, we aim to improve the robustness and reliability of the RAG workflow in the medical domain. Specifically, we propose a map-reduce strategy, BriefContext, to combat the "lost-in-the-middle" issue without modifying the model weights. We demonstrated the advantage of the workflow with various LLM backbones and on multiple QA datasets. This method promises to improve the safety and reliability of LLMs deployed in healthcare domains.
Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine
Jan 24, 2024Recent studies indicate that Generative Pre-trained Transformer 4 with Vision (GPT-4V) outperforms human physicians in medical challenge tasks. However, these evaluations primarily focused on the accuracy of multi-choice questions alone. Our study extends the current scope by conducting a comprehensive analysis of GPT-4V's rationales of image comprehension, recall of medical knowledge, and step-by-step multimodal reasoning when solving New England Journal of Medicine (NEJM) Image Challenges - an imaging quiz designed to test the knowledge and diagnostic capabilities of medical professionals. Evaluation results confirmed that GPT-4V outperforms human physicians regarding multi-choice accuracy (88.0% vs. 77.0%, p=0.034). GPT-4V also performs well in cases where physicians incorrectly answer, with over 80% accuracy. However, we discovered that GPT-4V frequently presents flawed rationales in cases where it makes the correct final choices (27.3%), most prominent in image comprehension (21.6%). Regardless of GPT-4V's high accuracy in multi-choice questions, our findings emphasize the necessity for further in-depth evaluations of its rationales before integrating such models into clinical workflows.
Less Likely Brainstorming: Using Language Models to Generate Alternative Hypotheses
May 30, 2023


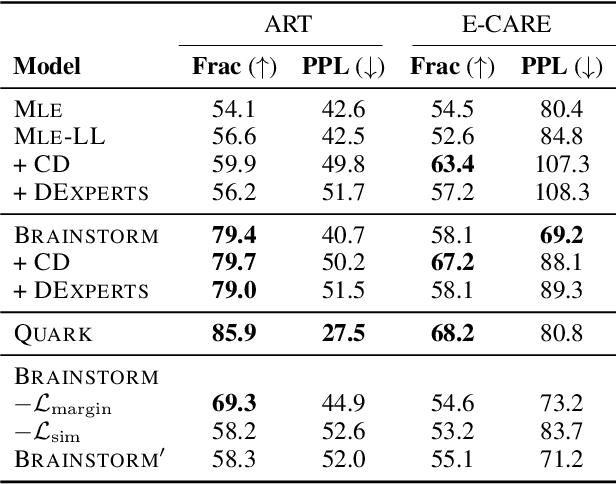
A human decision-maker benefits the most from an AI assistant that corrects for their biases. For problems such as generating interpretation of a radiology report given findings, a system predicting only highly likely outcomes may be less useful, where such outcomes are already obvious to the user. To alleviate biases in human decision-making, it is worth considering a broad differential diagnosis, going beyond the most likely options. We introduce a new task, "less likely brainstorming," that asks a model to generate outputs that humans think are relevant but less likely to happen. We explore the task in two settings: a brain MRI interpretation generation setting and an everyday commonsense reasoning setting. We found that a baseline approach of training with less likely hypotheses as targets generates outputs that humans evaluate as either likely or irrelevant nearly half of the time; standard MLE training is not effective. To tackle this problem, we propose a controlled text generation method that uses a novel contrastive learning strategy to encourage models to differentiate between generating likely and less likely outputs according to humans. We compare our method with several state-of-the-art controlled text generation models via automatic and human evaluations and show that our models' capability of generating less likely outputs is improved.
Using Explainable AI to Cross-Validate Socio-economic Disparities Among Covid-19 Patient Mortality
Feb 16, 2023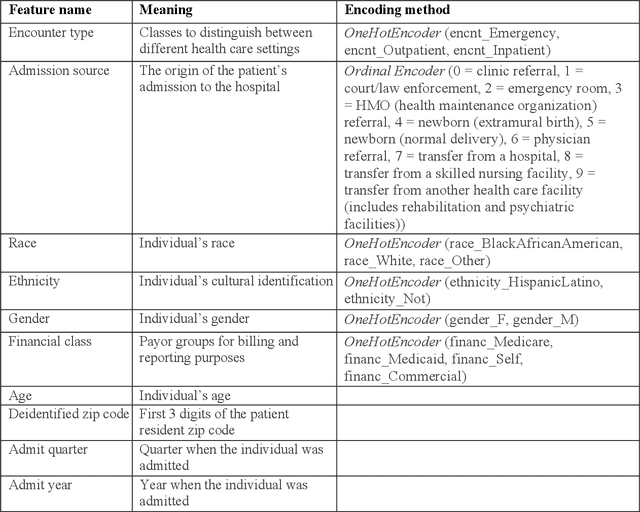
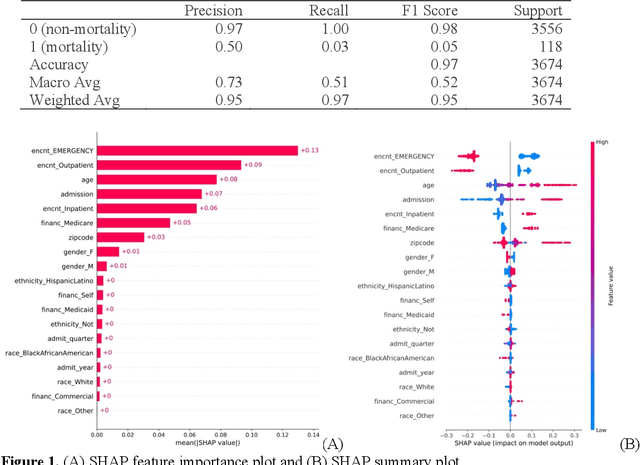
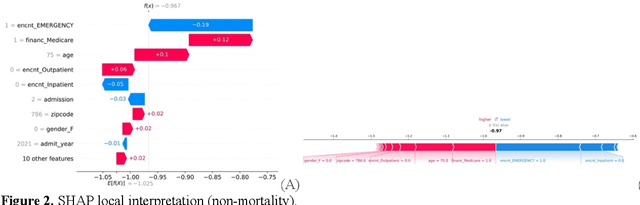

This paper applies eXplainable Artificial Intelligence (XAI) methods to investigate the socioeconomic disparities in COVID patient mortality. An Extreme Gradient Boosting (XGBoost) prediction model is built based on a de-identified Austin area hospital dataset to predict the mortality of COVID-19 patients. We apply two XAI methods, Shapley Additive exPlanations (SHAP) and Locally Interpretable Model Agnostic Explanations (LIME), to compare the global and local interpretation of feature importance. This paper demonstrates the advantages of using XAI which shows the feature importance and decisive capability. Furthermore, we use the XAI methods to cross-validate their interpretations for individual patients. The XAI models reveal that Medicare financial class, older age, and gender have high impact on the mortality prediction. We find that LIME local interpretation does not show significant differences in feature importance comparing to SHAP, which suggests pattern confirmation. This paper demonstrates the importance of XAI methods in cross-validation of feature attributions.
Attend Who is Weak: Pruning-assisted Medical Image Localization under Sophisticated and Implicit Imbalances
Dec 06, 2022

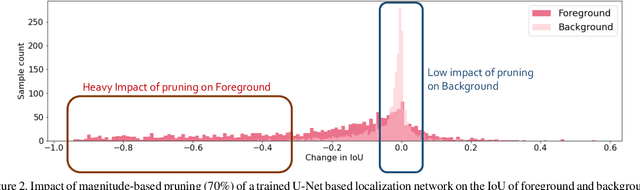
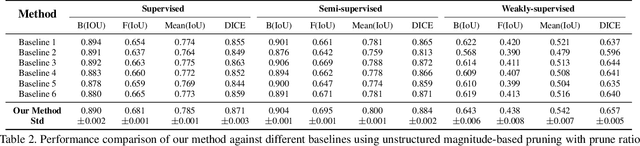
Deep neural networks (DNNs) have rapidly become a \textit{de facto} choice for medical image understanding tasks. However, DNNs are notoriously fragile to the class imbalance in image classification. We further point out that such imbalance fragility can be amplified when it comes to more sophisticated tasks such as pathology localization, as imbalances in such problems can have highly complex and often implicit forms of presence. For example, different pathology can have different sizes or colors (w.r.t.the background), different underlying demographic distributions, and in general different difficulty levels to recognize, even in a meticulously curated balanced distribution of training data. In this paper, we propose to use pruning to automatically and adaptively identify \textit{hard-to-learn} (HTL) training samples, and improve pathology localization by attending them explicitly, during training in \textit{supervised, semi-supervised, and weakly-supervised} settings. Our main inspiration is drawn from the recent finding that deep classification models have difficult-to-memorize samples and those may be effectively exposed through network pruning \cite{hooker2019compressed} - and we extend such observation beyond classification for the first time. We also present an interesting demographic analysis which illustrates HTLs ability to capture complex demographic imbalances. Our extensive experiments on the Skin Lesion Localization task in multiple training settings by paying additional attention to HTLs show significant improvement of localization performance by $\sim$2-3\%.
Old can be Gold: Better Gradient Flow can Make Vanilla-GCNs Great Again
Oct 14, 2022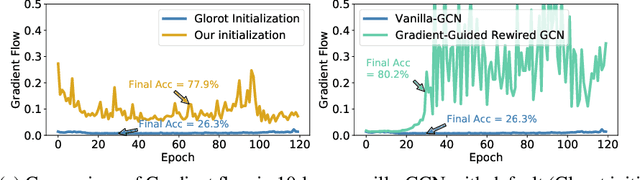

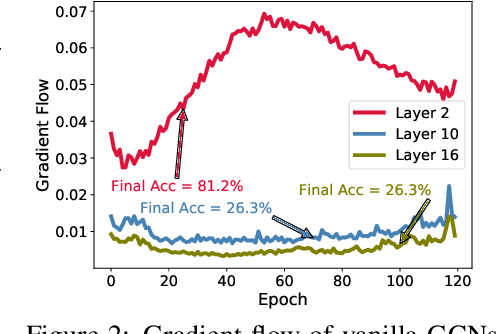
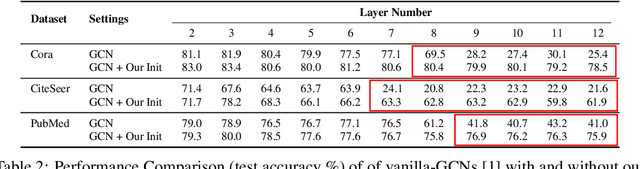
Despite the enormous success of Graph Convolutional Networks (GCNs) in modeling graph-structured data, most of the current GCNs are shallow due to the notoriously challenging problems of over-smoothening and information squashing along with conventional difficulty caused by vanishing gradients and over-fitting. Previous works have been primarily focused on the study of over-smoothening and over-squashing phenomena in training deep GCNs. Surprisingly, in comparison with CNNs/RNNs, very limited attention has been given to understanding how healthy gradient flow can benefit the trainability of deep GCNs. In this paper, firstly, we provide a new perspective of gradient flow to understand the substandard performance of deep GCNs and hypothesize that by facilitating healthy gradient flow, we can significantly improve their trainability, as well as achieve state-of-the-art (SOTA) level performance from vanilla-GCNs. Next, we argue that blindly adopting the Glorot initialization for GCNs is not optimal, and derive a topology-aware isometric initialization scheme for vanilla-GCNs based on the principles of isometry. Additionally, contrary to ad-hoc addition of skip-connections, we propose to use gradient-guided dynamic rewiring of vanilla-GCNs} with skip connections. Our dynamic rewiring method uses the gradient flow within each layer during training to introduce on-demand skip-connections adaptively. We provide extensive empirical evidence across multiple datasets that our methods improve gradient flow in deep vanilla-GCNs and significantly boost their performance to comfortably compete and outperform many fancy state-of-the-art methods. Codes are available at: https://github.com/VITA-Group/GradientGCN.
Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors
May 25, 2022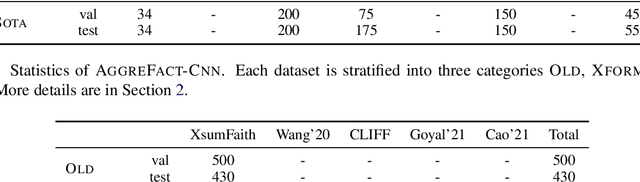
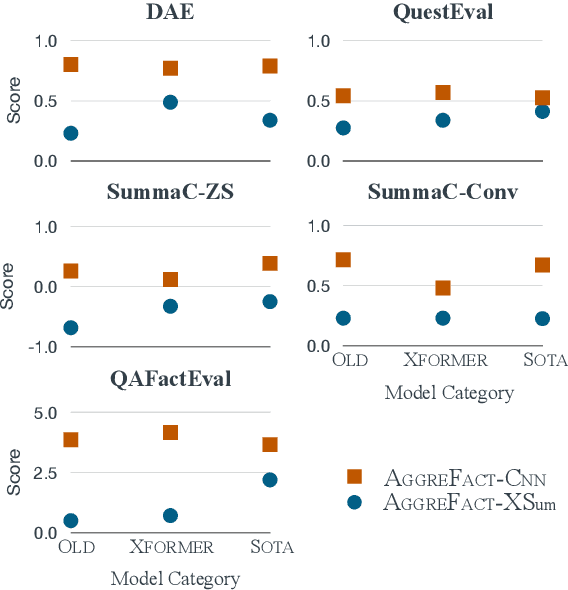
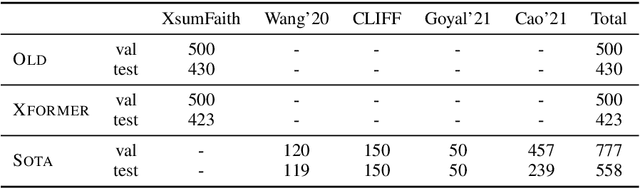
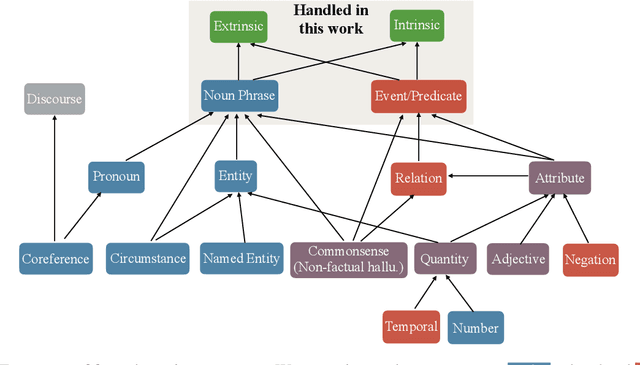
The propensity of abstractive summarization systems to make factual errors has been the subject of significant study, including work on models to detect factual errors and annotation of errors in current systems' outputs. However, the ever-evolving nature of summarization systems, error detectors, and annotated benchmarks make factuality evaluation a moving target; it is hard to get a clear picture of how techniques compare. In this work, we collect labeled factuality errors from across nine datasets of annotated summary outputs and stratify them in a new way, focusing on what kind of base summarization model was used. To support finer-grained analysis, we unify the labeled error types into a single taxonomy and project each of the datasets' errors into this shared labeled space. We then contrast five state-of-the-art error detection methods on this benchmark. Our findings show that benchmarks built on modern summary outputs (those from pre-trained models) show significantly different results than benchmarks using pre-Transformer models. Furthermore, no one factuality technique is superior in all settings or for all error types, suggesting that system developers should take care to choose the right system for their task at hand.
SCALP -- Supervised Contrastive Learning for Cardiopulmonary Disease Classification and Localization in Chest X-rays using Patient Metadata
Oct 27, 2021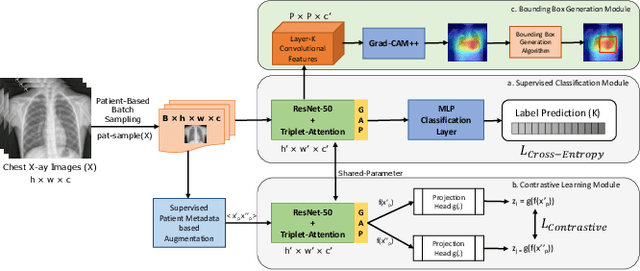
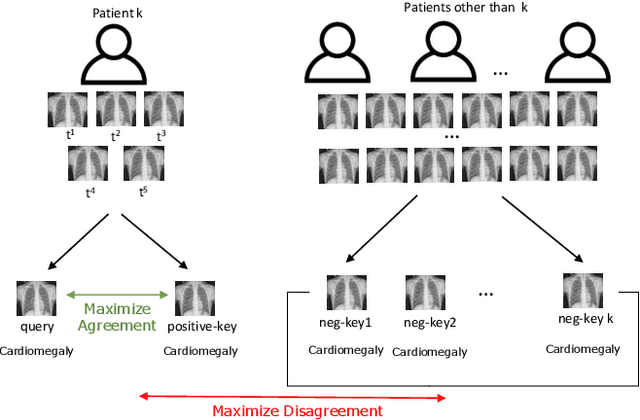
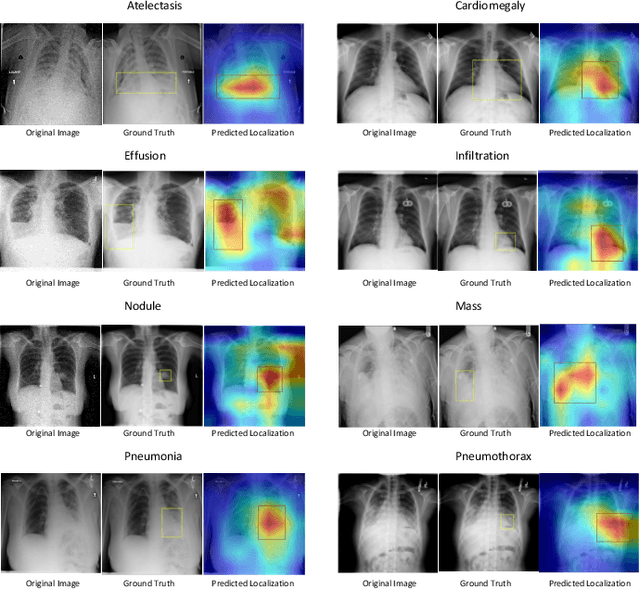
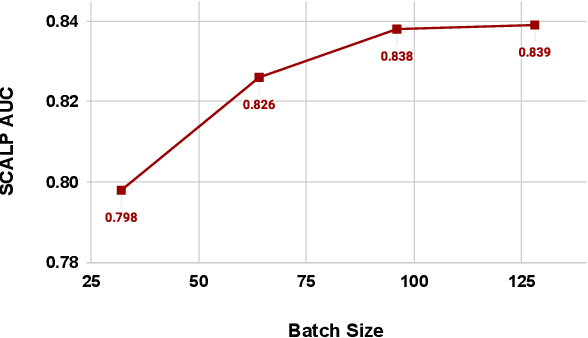
Computer-aided diagnosis plays a salient role in more accessible and accurate cardiopulmonary diseases classification and localization on chest radiography. Millions of people get affected and die due to these diseases without an accurate and timely diagnosis. Recently proposed contrastive learning heavily relies on data augmentation, especially positive data augmentation. However, generating clinically-accurate data augmentations for medical images is extremely difficult because the common data augmentation methods in computer vision, such as sharp, blur, and crop operations, can severely alter the clinical settings of medical images. In this paper, we proposed a novel and simple data augmentation method based on patient metadata and supervised knowledge to create clinically accurate positive and negative augmentations for chest X-rays. We introduce an end-to-end framework, SCALP, which extends the self-supervised contrastive approach to a supervised setting. Specifically, SCALP pulls together chest X-rays from the same patient (positive keys) and pushes apart chest X-rays from different patients (negative keys). In addition, it uses ResNet-50 along with the triplet-attention mechanism to identify cardiopulmonary diseases, and Grad-CAM++ to highlight the abnormal regions. Our extensive experiments demonstrate that SCALP outperforms existing baselines with significant margins in both classification and localization tasks. Specifically, the average classification AUCs improve from 82.8% (SOTA using DenseNet-121) to 83.9% (SCALP using ResNet-50), while the localization results improve on average by 3.7% over different IoU thresholds.