 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Guided Diffusion Model for EEG-Based Visual Cognition Reconstruction
Apr 24, 2026Objective: Decoding visual information from electroencephalography (EEG) is an important problem in neuroscience and brain-computer interface (BCI) research. Existing methods are largely restricted to natural images and categorical representations, with limited capacity to capture structural features and to differentiate objective perception from subjective cognition. We propose a Structure-Guided Diffusion Model (SGDM) that incorporates explicit structural information for EEG-based visual reconstruction. Approach: SGDM is evaluated on the Kilogram abstract visual object dataset and the THINGS natural image dataset using a two-stage generative mechanism. The framework combines a structurally supervised variational autoencoder with a spatiotemporal EEG encoder aligned to a visual embedding space via contrastive learning. Structural information is integrated into a diffusion model through ControlNet to guide image generation from EEG features. Results: SGDM outperforms existing methods on both abstract and natural image datasets. Reconstructed images achieve higher fidelity in low-level visual features and semantic representations, indicating improved decoding accuracy and strong generalization across diverse visual domains. Spatiotemporal analysis of EEG signals further reveals hierarchical structural encoding patterns, consistent with the neural dynamics of visual cognition. Significance: These findings validate the effectiveness of SGDM in capturing explicit structural geometry and generating images with high fidelity to individual cognitive representations. By enabling decoding of complex visual content from EEG signals, the framework extends neural decoding beyond low-dimensional or categorical outputs. This supports BCIs with increased degrees of freedom for intention decoding and more flexible brain-to-machine communication.
Graph-GRPO: Stabilizing Multi-Agent Topology Learning via Group Relative Policy Optimization
Mar 03, 2026Optimizing communication topology is fundamental to the efficiency and effectiveness of Large Language Model (LLM)-based Multi-Agent Systems (MAS). While recent approaches utilize reinforcement learning to dynamically construct task-specific graphs, they typically rely on single-sample policy gradients with absolute rewards (e.g., binary correctness). This paradigm suffers from severe gradient variance and the credit assignment problem: simple queries yield non-informative positive rewards for suboptimal structures, while difficult queries often result in failures that provide no learning signal. To address these challenges, we propose Graph-GRPO, a novel topology optimization framework that integrates Group Relative Policy Optimization. Instead of evaluating a single topology in isolation, Graph-GRPO samples a group of diverse communication graphs for each query and computes the advantage of specific edges based on their relative performance within the group. By normalizing rewards across the sampled group, our method effectively mitigates the noise derived from task difficulty variance and enables fine-grained credit assignment. Extensive experiments on reasoning and code generation benchmarks demonstrate that Graph-GRPO significantly outperforms state-of-the-art baselines, achieving superior training stability and identifying critical communication pathways previously obscured by reward noise.
Intelligent Pathological Diagnosis of Gestational Trophoblastic Diseases via Visual-Language Deep Learning Model
Mar 03, 2026The pathological diagnosis of gestational trophoblastic disease(GTD) takes a long time, relies heavily on the experience of pathologists, and the consistency of initial diagnosis is low, which seriously threatens maternal health and reproductive outcomes. We developed an expert model for GTD pathological diagnosis, named GTDoctor. GTDoctor can perform pixel-based lesion segmentation on pathological slides, and output diagnostic conclusions and personalized pathological analysis results. We developed a software system, GTDiagnosis, based on this technology and conducted clinical trials. The retrospective results demonstrated that GTDiagnosis achieved a mean precision of over 0.91 for lesion detection in pathological slides (n=679 slides). In prospective studies, pathologists using GTDiagnosis attained a Positive Predictive Value of 95.59% (n=68 patients). The tool reduced average diagnostic time from 56 to 16 seconds per case (n=285 patients). GTDoctor and GTDiagnosis offer a novel solution for GTD pathological diagnosis, enhancing diagnostic performance and efficiency while maintaining clinical interpretability.
DINT Transformer
Jan 29, 2025DIFF Transformer addresses the issue of irrelevant context interference by introducing a differential attention mechanism that enhances the robustness of local attention. However, it has two critical limitations: the lack of global context modeling, which is essential for identifying globally significant tokens, and numerical instability due to the absence of strict row normalization in the attention matrix. To overcome these challenges, we propose DINT Transformer, which extends DIFF Transformer by incorporating a differential-integral mechanism. By computing global importance scores and integrating them into the attention matrix, DINT Transformer improves its ability to capture global dependencies. Moreover, the unified parameter design enforces row-normalized attention matrices, improving numerical stability. Experimental results demonstrate that DINT Transformer excels in accuracy and robustness across various practical applications, such as long-context language modeling and key information retrieval. These results position DINT Transformer as a highly effective and promising architecture.
Argumentative Experience: Reducing Confirmation Bias on Controversial Issues through LLM-Generated Multi-Persona Debates
Dec 10, 2024



Large language models (LLMs) are enabling designers to give life to exciting new user experiences for information access. In this work, we present a system that generates LLM personas to debate a topic of interest from different perspectives. How might information seekers use and benefit from such a system? Can centering information access around diverse viewpoints help to mitigate thorny challenges like confirmation bias in which information seekers over-trust search results matching existing beliefs? How do potential biases and hallucinations in LLMs play out alongside human users who are also fallible and possibly biased? Our study exposes participants to multiple viewpoints on controversial issues via a mixed-methods, within-subjects study. We use eye-tracking metrics to quantitatively assess cognitive engagement alongside qualitative feedback. Compared to a baseline search system, we see more creative interactions and diverse information-seeking with our multi-persona debate system, which more effectively reduces user confirmation bias and conviction toward their initial beliefs. Overall, our study contributes to the emerging design space of LLM-based information access systems, specifically investigating the potential of simulated personas to promote greater exposure to information diversity, emulate collective intelligence, and mitigate bias in information seeking.
Can KAN Work? Exploring the Potential of Kolmogorov-Arnold Networks in Computer Vision
Nov 14, 2024Kolmogorov-Arnold Networks(KANs), as a theoretically efficient neural network architecture, have garnered attention for their potential in capturing complex patterns. However, their application in computer vision remains relatively unexplored. This study first analyzes the potential of KAN in computer vision tasks, evaluating the performance of KAN and its convolutional variants in image classification and semantic segmentation. The focus is placed on examining their characteristics across varying data scales and noise levels. Results indicate that while KAN exhibits stronger fitting capabilities, it is highly sensitive to noise, limiting its robustness. To address this challenge, we propose a smoothness regularization method and introduce a Segment Deactivation technique. Both approaches enhance KAN's stability and generalization, demonstrating its potential in handling complex visual data tasks.
Review of Cloud Service Composition for Intelligent Manufacturing
Aug 03, 2024



Intelligent manufacturing is a new model that uses advanced technologies such as the Internet of Things, big data, and artificial intelligence to improve the efficiency and quality of manufacturing production. As an important support to promote the transformation and upgrading of the manufacturing industry, cloud service optimization has received the attention of researchers. In recent years, remarkable research results have been achieved in this field. For the sustainability of intelligent manufacturing platforms, in this paper we summarize the process of cloud service optimization for intelligent manufacturing. Further, to address the problems of dispersed optimization indicators and nonuniform/unstandardized definitions in the existing research, 11 optimization indicators that take into account three-party participant subjects are defined from the urgent requirements of the sustainable development of intelligent manufacturing platforms. Next, service optimization algorithms are classified into two categories, heuristic and reinforcement learning. After comparing the two categories, the current key techniques of service optimization are targeted. Finally, research hotspots and future research trends of service optimization are summarized.
TSOM: Small Object Motion Detection Neural Network Inspired by Avian Visual Circuit
Apr 01, 2024



Detecting small moving objects in complex backgrounds from an overhead perspective is a highly challenging task for machine vision systems. As an inspiration from nature, the avian visual system is capable of processing motion information in various complex aerial scenes, and its Retina-OT-Rt visual circuit is highly sensitive to capturing the motion information of small objects from high altitudes. However, more needs to be done on small object motion detection algorithms based on the avian visual system. In this paper, we conducted mathematical modeling based on extensive studies of the biological mechanisms of the Retina-OT-Rt visual circuit. Based on this, we proposed a novel tectum small object motion detection neural network (TSOM). The neural network includes the retina, SGC dendritic, SGC Soma, and Rt layers, each layer corresponding to neurons in the visual pathway. The Retina layer is responsible for accurately projecting input content, the SGC dendritic layer perceives and encodes spatial-temporal information, the SGC Soma layer computes complex motion information and extracts small objects, and the Rt layer integrates and decodes motion information from multiple directions to determine the position of small objects. Extensive experiments on pigeon neurophysiological experiments and image sequence data showed that the TSOM is biologically interpretable and effective in extracting reliable small object motion features from complex high-altitude backgrounds.
Using Explainable AI to Cross-Validate Socio-economic Disparities Among Covid-19 Patient Mortality
Feb 16, 2023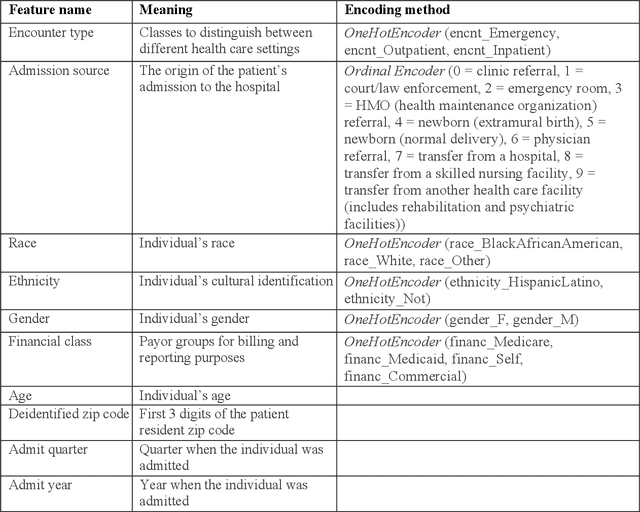
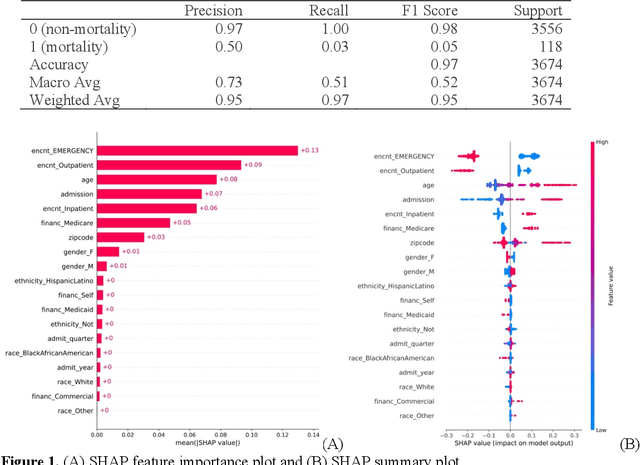
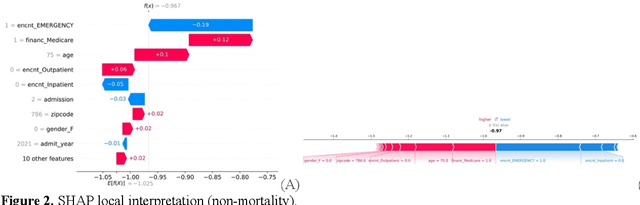

This paper applies eXplainable Artificial Intelligence (XAI) methods to investigate the socioeconomic disparities in COVID patient mortality. An Extreme Gradient Boosting (XGBoost) prediction model is built based on a de-identified Austin area hospital dataset to predict the mortality of COVID-19 patients. We apply two XAI methods, Shapley Additive exPlanations (SHAP) and Locally Interpretable Model Agnostic Explanations (LIME), to compare the global and local interpretation of feature importance. This paper demonstrates the advantages of using XAI which shows the feature importance and decisive capability. Furthermore, we use the XAI methods to cross-validate their interpretations for individual patients. The XAI models reveal that Medicare financial class, older age, and gender have high impact on the mortality prediction. We find that LIME local interpretation does not show significant differences in feature importance comparing to SHAP, which suggests pattern confirmation. This paper demonstrates the importance of XAI methods in cross-validation of feature attributions.
Segmentation Network with Compound Loss Function for Hydatidiform Mole Hydrops Lesion Recognition
Apr 11, 2022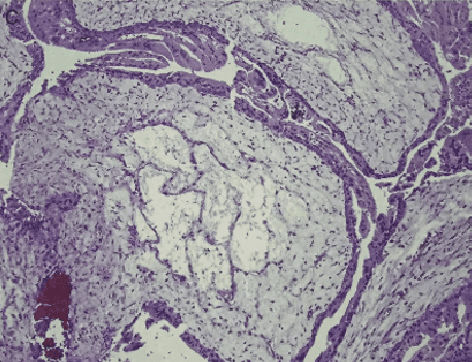
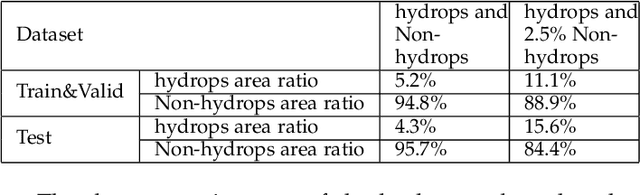

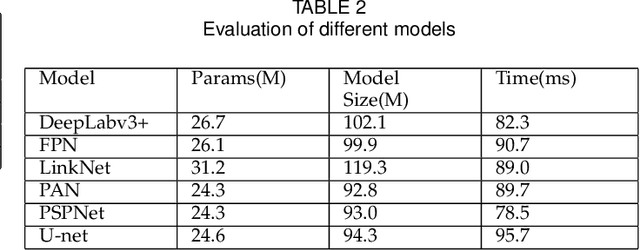
Pathological morphology diagnosis is the standard diagnosis method of hydatidiform mole. As a disease with malignant potential, the hydatidiform mole section of hydrops lesions is an important basis for diagnosis. Due to incomplete lesion development, early hydatidiform mole is difficult to distinguish, resulting in a low accuracy of clinical diagnosis. As a remarkable machine learning technology, image semantic segmentation networks have been used in many medical image recognition tasks. We developed a hydatidiform mole hydrops lesion segmentation model based on a novel loss function and training method. The model consists of different networks that segment the section image at the pixel and lesion levels. Our compound loss function assign weights to the segmentation results of the two levels to calculate the loss. We then propose a stagewise training method to combine the advantages of various loss functions at different levels. We evaluate our method on a hydatidiform mole hydrops dataset. Experiments show that the proposed model with our loss function and training method has good recognition performance under different segmentation metrics.