 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgumentative Experience: Reducing Confirmation Bias on Controversial Issues through LLM-Generated Multi-Persona Debates
Dec 10, 2024



Large language models (LLMs) are enabling designers to give life to exciting new user experiences for information access. In this work, we present a system that generates LLM personas to debate a topic of interest from different perspectives. How might information seekers use and benefit from such a system? Can centering information access around diverse viewpoints help to mitigate thorny challenges like confirmation bias in which information seekers over-trust search results matching existing beliefs? How do potential biases and hallucinations in LLMs play out alongside human users who are also fallible and possibly biased? Our study exposes participants to multiple viewpoints on controversial issues via a mixed-methods, within-subjects study. We use eye-tracking metrics to quantitatively assess cognitive engagement alongside qualitative feedback. Compared to a baseline search system, we see more creative interactions and diverse information-seeking with our multi-persona debate system, which more effectively reduces user confirmation bias and conviction toward their initial beliefs. Overall, our study contributes to the emerging design space of LLM-based information access systems, specifically investigating the potential of simulated personas to promote greater exposure to information diversity, emulate collective intelligence, and mitigate bias in information seeking.
Stable Remaster: Bridging the Gap Between Old Content and New Displays
Jun 11, 2023
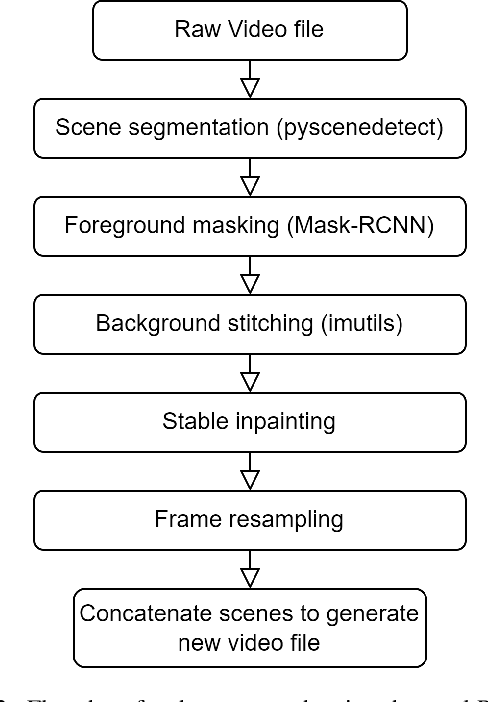


The invention of modern displays has enhanced the viewer experience for any kind of content: ranging from sports to movies in 8K high-definition resolution. However, older content developed for CRT or early Plasma screen TVs has become outdated quickly and no longer meets current aspect ratio and resolution standards. In this paper, we explore whether we can solve this problem with the use of diffusion models to adapt old content to meet contemporary expectations. We explore the ability to combine multiple independent computer vision tasks to attempt to solve the problem of expanding aspect ratios of old animated content such that the new content would be indistinguishable from the source material to a brand-new viewer. These existing capabilities include Stable Diffusion, Content-Aware Scene Detection, Object Detection, and Key Point Matching. We were able to successfully chain these tasks together in a way that generated reasonable outputs, however, future work needs to be done to improve and expand the application to non-animated content as well.