 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring AI Alignment with Human Flourishing
Jul 10, 2025
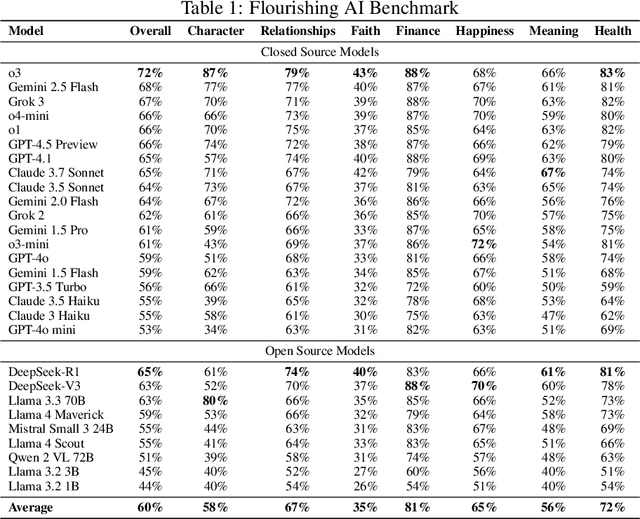
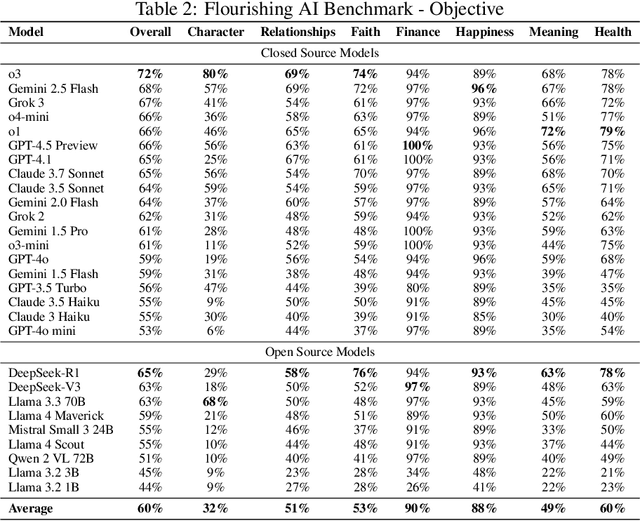

This paper introduces the Flourishing AI Benchmark (FAI Benchmark), a novel evaluation framework that assesses AI alignment with human flourishing across seven dimensions: Character and Virtue, Close Social Relationships, Happiness and Life Satisfaction, Meaning and Purpose, Mental and Physical Health, Financial and Material Stability, and Faith and Spirituality. Unlike traditional benchmarks that focus on technical capabilities or harm prevention, the FAI Benchmark measures AI performance on how effectively models contribute to the flourishing of a person across these dimensions. The benchmark evaluates how effectively LLM AI systems align with current research models of holistic human well-being through a comprehensive methodology that incorporates 1,229 objective and subjective questions. Using specialized judge Large Language Models (LLMs) and cross-dimensional evaluation, the FAI Benchmark employs geometric mean scoring to ensure balanced performance across all flourishing dimensions. Initial testing of 28 leading language models reveals that while some models approach holistic alignment (with the highest-scoring models achieving 72/100), none are acceptably aligned across all dimensions, particularly in Faith and Spirituality, Character and Virtue, and Meaning and Purpose. This research establishes a framework for developing AI systems that actively support human flourishing rather than merely avoiding harm, offering significant implications for AI development, ethics, and evaluation.
Bridging Modalities: Knowledge Distillation and Masked Training for Translating Multi-Modal Emotion Recognition to Uni-Modal, Speech-Only Emotion Recognition
Jan 04, 2024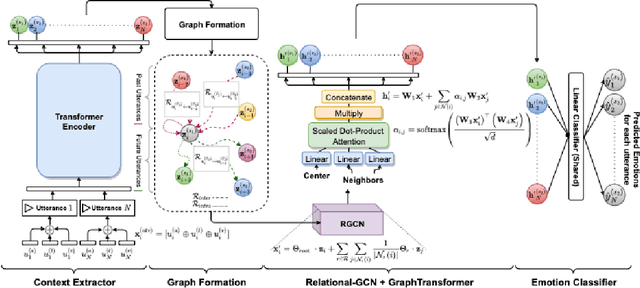
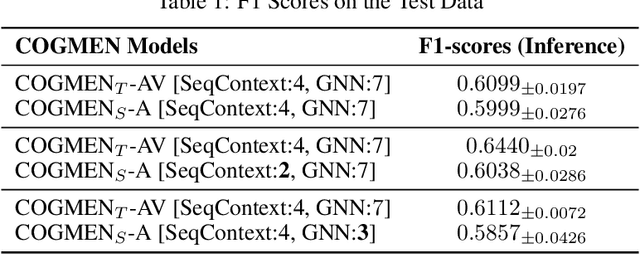
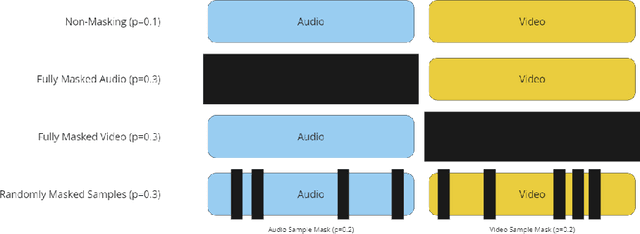

This paper presents an innovative approach to address the challenges of translating multi-modal emotion recognition models to a more practical and resource-efficient uni-modal counterpart, specifically focusing on speech-only emotion recognition. Recognizing emotions from speech signals is a critical task with applications in human-computer interaction, affective computing, and mental health assessment. However, existing state-of-the-art models often rely on multi-modal inputs, incorporating information from multiple sources such as facial expressions and gestures, which may not be readily available or feasible in real-world scenarios. To tackle this issue, we propose a novel framework that leverages knowledge distillation and masked training techniques.
Stable Remaster: Bridging the Gap Between Old Content and New Displays
Jun 11, 2023
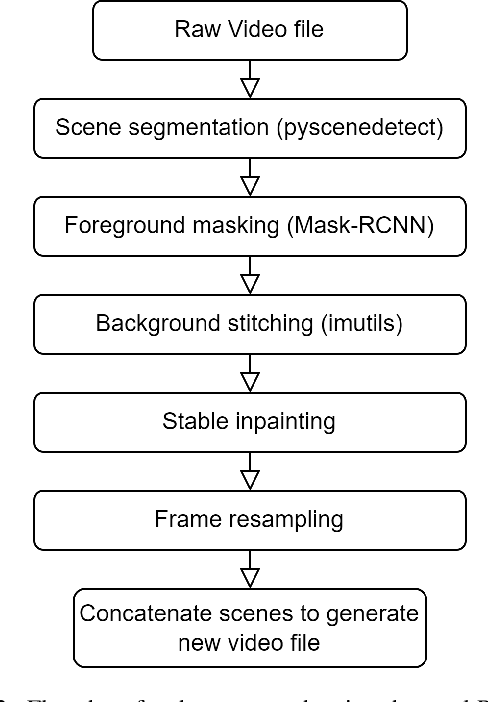


The invention of modern displays has enhanced the viewer experience for any kind of content: ranging from sports to movies in 8K high-definition resolution. However, older content developed for CRT or early Plasma screen TVs has become outdated quickly and no longer meets current aspect ratio and resolution standards. In this paper, we explore whether we can solve this problem with the use of diffusion models to adapt old content to meet contemporary expectations. We explore the ability to combine multiple independent computer vision tasks to attempt to solve the problem of expanding aspect ratios of old animated content such that the new content would be indistinguishable from the source material to a brand-new viewer. These existing capabilities include Stable Diffusion, Content-Aware Scene Detection, Object Detection, and Key Point Matching. We were able to successfully chain these tasks together in a way that generated reasonable outputs, however, future work needs to be done to improve and expand the application to non-animated content as well.