 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prejudice to Parity: A New Approach to Debiasing Large Language Model Word Embeddings
Feb 20, 2024



Embeddings play a pivotal role in the efficacy of Large Language Models. They are the bedrock on which these models grasp contextual relationships and foster a more nuanced understanding of language and consequently perform remarkably on a plethora of complex tasks that require a fundamental understanding of human language. Given that these embeddings themselves often reflect or exhibit bias, it stands to reason that these models may also inadvertently learn this bias. In this work, we build on the seminal previous work and propose DeepSoftDebias, an algorithm that uses a neural network to perform 'soft debiasing'. We exhaustively evaluate this algorithm across a variety of SOTA datasets, accuracy metrics, and challenging NLP tasks. We find that DeepSoftDebias outperforms the current state-of-the-art methods at reducing bias across gender, race, and religion.
Annotating sleep states in children from wrist-worn accelerometer data using Machine Learning
Dec 09, 2023



Sleep detection and annotation are crucial for researchers to understand sleep patterns, especially in children. With modern wrist-worn watches comprising built-in accelerometers, sleep logs can be collected. However, the annotation of these logs into distinct sleep events: onset and wakeup, proves to be challenging. These annotations must be automated, precise, and scalable. We propose to model the accelerometer data using different machine learning (ML) techniques such as support vectors, boosting, ensemble methods, and more complex approaches involving LSTMs and Region-based CNNs. Later, we aim to evaluate these approaches using the Event Detection Average Precision (EDAP) score (similar to the IOU metric) to eventually compare the predictive power and model performance.
Facial asymmetry: A Computer Vision based behaviometric index for assessment during a face-to-face interview
Oct 30, 2023



Choosing the right person for the right job makes the personnel interview process a cognitively demanding task. Psychometric tests, followed by an interview, have often been used to aid the process although such mechanisms have their limitations. While psychometric tests suffer from faking or social desirability of responses, the interview process depends on the way the responses are analyzed by the interviewers. We propose the use of behaviometry as an assistive tool to facilitate an objective assessment of the interviewee without increasing the cognitive load of the interviewer. Behaviometry is a relatively little explored field of study in the selection process, that utilizes inimitable behavioral characteristics like facial expressions, vocalization patterns, pupillary reactions, proximal behavior, body language, etc. The method analyzes thin slices of behavior and provides unbiased information about the interviewee. The current study proposes the methodology behind this tool to capture facial expressions, in terms of facial asymmetry and micro-expressions. Hemi-facial composites using a structural similarity index was used to develop a progressive time graph of facial asymmetry, as a test case. A frame-by-frame analysis was performed on three YouTube video samples, where Structural similarity index (SSID) scores of 75% and more showed behavioral congruence. The research utilizes open-source computer vision algorithms and libraries (python-opencv and dlib) to formulate the procedure for analysis of the facial asymmetry.
Decoding Brain Motor Imagery with various Machine Learning techniques
Jun 13, 2023



Motor imagery (MI) is a well-documented technique used by subjects in BCI (Brain Computer Interface) experiments to modulate brain activity within the motor cortex and surrounding areas of the brain. In our term project, we conducted an experiment in which the subjects were instructed to perform motor imagery that would be divided into two classes (Right and Left). Experiments were conducted with two different types of electrodes (Gel and POLiTag) and data for individual subjects was collected. In this paper, we will apply different machine learning (ML) methods to create a decoder based on offline training data that uses evidence accumulation to predict a subject's intent from their modulated brain signals in real-time.
Stable Remaster: Bridging the Gap Between Old Content and New Displays
Jun 11, 2023
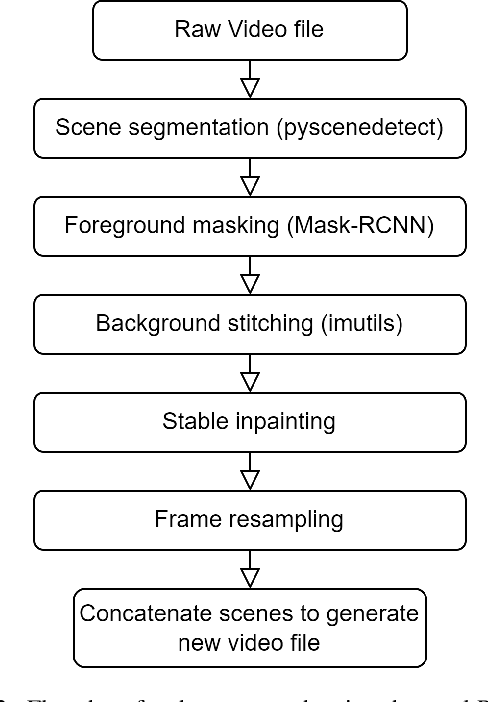


The invention of modern displays has enhanced the viewer experience for any kind of content: ranging from sports to movies in 8K high-definition resolution. However, older content developed for CRT or early Plasma screen TVs has become outdated quickly and no longer meets current aspect ratio and resolution standards. In this paper, we explore whether we can solve this problem with the use of diffusion models to adapt old content to meet contemporary expectations. We explore the ability to combine multiple independent computer vision tasks to attempt to solve the problem of expanding aspect ratios of old animated content such that the new content would be indistinguishable from the source material to a brand-new viewer. These existing capabilities include Stable Diffusion, Content-Aware Scene Detection, Object Detection, and Key Point Matching. We were able to successfully chain these tasks together in a way that generated reasonable outputs, however, future work needs to be done to improve and expand the application to non-animated content as well.