 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidGuard-R1: AI-Generated Video Detection and Explanation via Reasoning MLLMs and RL
Oct 02, 2025With the rapid advancement of AI-generated videos, there is an urgent need for effective detection tools to mitigate societal risks such as misinformation and reputational harm. In addition to accurate classification, it is essential that detection models provide interpretable explanations to ensure transparency for regulators and end users. To address these challenges, we introduce VidGuard-R1, the first video authenticity detector that fine-tunes a multi-modal large language model (MLLM) using group relative policy optimization (GRPO). Our model delivers both highly accurate judgments and insightful reasoning. We curate a challenging dataset of 140k real and AI-generated videos produced by state-of-the-art generation models, carefully designing the generation process to maximize discrimination difficulty. We then fine-tune Qwen-VL using GRPO with two specialized reward models that target temporal artifacts and generation complexity. Extensive experiments demonstrate that VidGuard-R1 achieves state-of-the-art zero-shot performance on existing benchmarks, with additional training pushing accuracy above 95%. Case studies further show that VidGuard-R1 produces precise and interpretable rationales behind its predictions. The code is publicly available at https://VidGuard-R1.github.io.
Explainable AI for Correct Root Cause Analysis of Product Quality in Injection Moulding
Apr 29, 2025



If a product deviates from its desired properties in the injection moulding process, its root cause analysis can be aided by models that relate the input machine settings with the output quality characteristics. The machine learning models tested in the quality prediction are mostly black boxes; therefore, no direct explanation of their prognosis is given, which restricts their applicability in the quality control. The previously attempted explainability methods are either restricted to tree-based algorithms only or do not emphasize on the fact that some explainability methods can lead to wrong root cause identification of a product's deviation from its desired properties. This study first shows that the interactions among the multiple input machine settings do exist in real experimental data collected as per a central composite design. Then, the model-agnostic explainable AI methods are compared for the first time to show that different explainability methods indeed lead to different feature impact analysis in injection moulding. Moreover, it is shown that the better feature attribution translates to the correct cause identification and actionable insights for the injection moulding process. Being model agnostic, explanations on both random forest and multilayer perceptron are performed for the cause analysis, as both models have the mean absolute percentage error of less than 0.05% on the experimental dataset.
Bridging Modalities: Knowledge Distillation and Masked Training for Translating Multi-Modal Emotion Recognition to Uni-Modal, Speech-Only Emotion Recognition
Jan 04, 2024
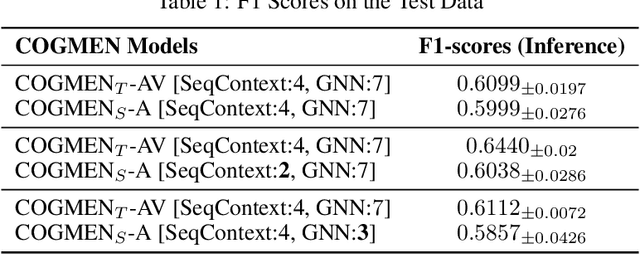
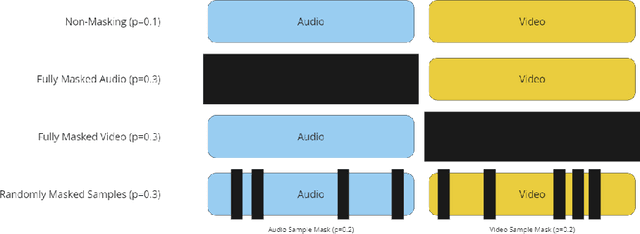

This paper presents an innovative approach to address the challenges of translating multi-modal emotion recognition models to a more practical and resource-efficient uni-modal counterpart, specifically focusing on speech-only emotion recognition. Recognizing emotions from speech signals is a critical task with applications in human-computer interaction, affective computing, and mental health assessment. However, existing state-of-the-art models often rely on multi-modal inputs, incorporating information from multiple sources such as facial expressions and gestures, which may not be readily available or feasible in real-world scenarios. To tackle this issue, we propose a novel framework that leverages knowledge distillation and masked training techniques.