 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Interactive AI Design on User Behavior: An Eye-tracking Study of Fact-checking COVID-19 Claims
Feb 17, 2022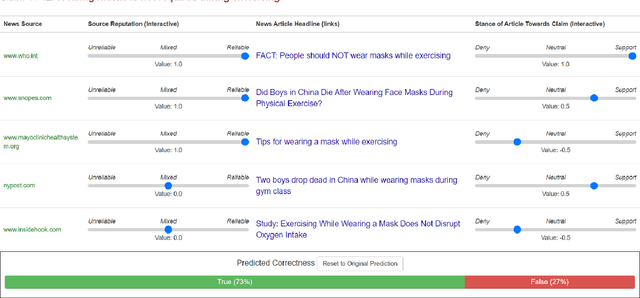
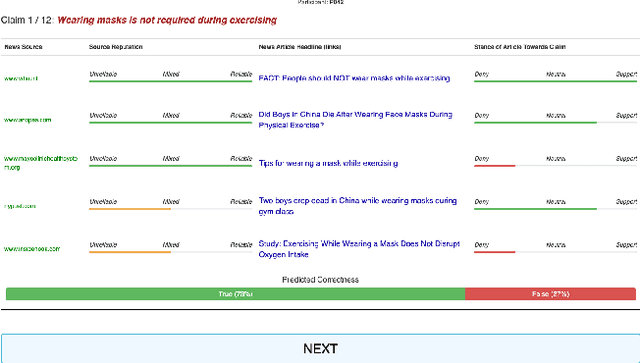
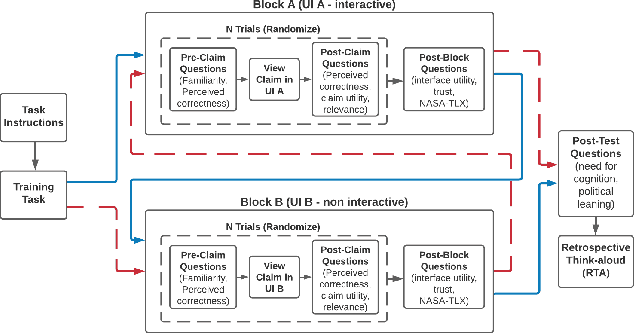
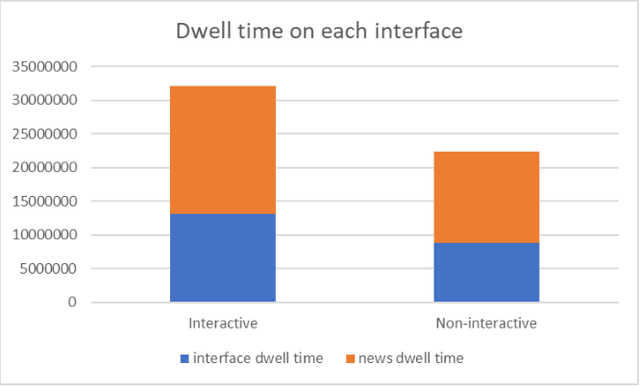
We conducted a lab-based eye-tracking study to investigate how the interactivity of an AI-powered fact-checking system affects user interactions, such as dwell time, attention, and mental resources involved in using the system. A within-subject experiment was conducted, where participants used an interactive and a non-interactive version of a mock AI fact-checking system and rated their perceived correctness of COVID-19 related claims. We collected web-page interactions, eye-tracking data, and mental workload using NASA-TLX. We found that the presence of the affordance of interactively manipulating the AI system's prediction parameters affected users' dwell times, and eye-fixations on AOIs, but not mental workload. In the interactive system, participants spent the most time evaluating claims' correctness, followed by reading news. This promising result shows a positive role of interactivity in a mixed-initiative AI-powered system.
Captioning Images Taken by People Who Are Blind
Feb 20, 2020
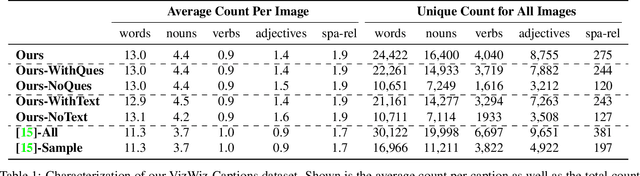
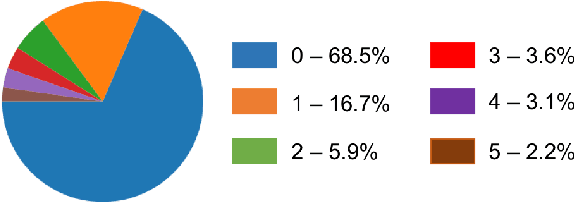
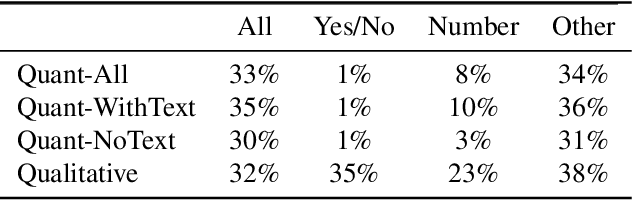
While an important problem in the vision community is to design algorithms that can automatically caption images, few publicly-available datasets for algorithm development directly address the interests of real users. Observing that people who are blind have relied on (human-based) image captioning services to learn about images they take for nearly a decade, we introduce the first image captioning dataset to represent this real use case. This new dataset, which we call VizWiz-Captions, consists of over 39,000 images originating from people who are blind that are each paired with five captions. We analyze this dataset to (1) characterize the typical captions, (2) characterize the diversity of content found in the images, and (3) compare its content to that found in eight popular vision datasets. We also analyze modern image captioning algorithms to identify what makes this new dataset challenging for the vision community. We publicly-share the dataset with captioning challenge instructions at https://vizwiz.org
Relevance Prediction from Eye-movements Using Semi-interpretable Convolutional Neural Networks
Jan 15, 2020
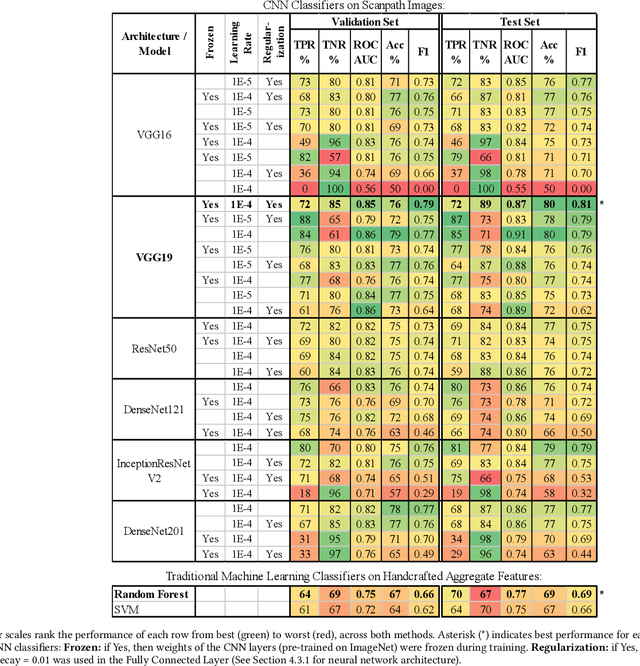
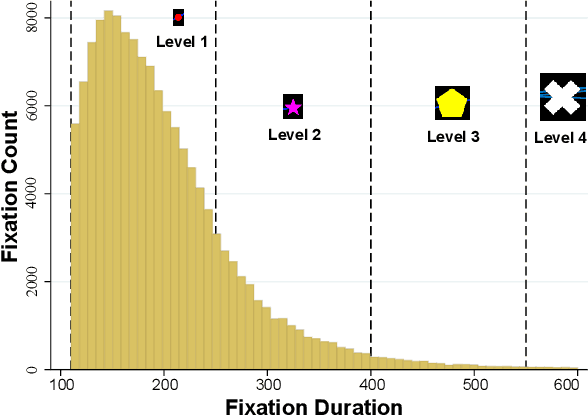
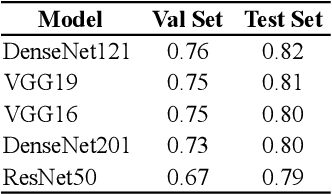
We propose an image-classification method to predict the perceived-relevance of text documents from eye-movements. An eye-tracking study was conducted where participants read short news articles, and rated them as relevant or irrelevant for answering a trigger question. We encode participants' eye-movement scanpaths as images, and then train a convolutional neural network classifier using these scanpath images. The trained classifier is used to predict participants' perceived-relevance of news articles from the corresponding scanpath images. This method is content-independent, as the classifier does not require knowledge of the screen-content, or the user's information-task. Even with little data, the image classifier can predict perceived-relevance with up to 80% accuracy. When compared to similar eye-tracking studies from the literature, this scanpath image classification method outperforms previously reported metrics by appreciable margins. We also attempt to interpret how the image classifier differentiates between scanpaths on relevant and irrelevant documents.
VizWiz Dataset Browser: A Tool for Visualizing Machine Learning Datasets
Dec 19, 2019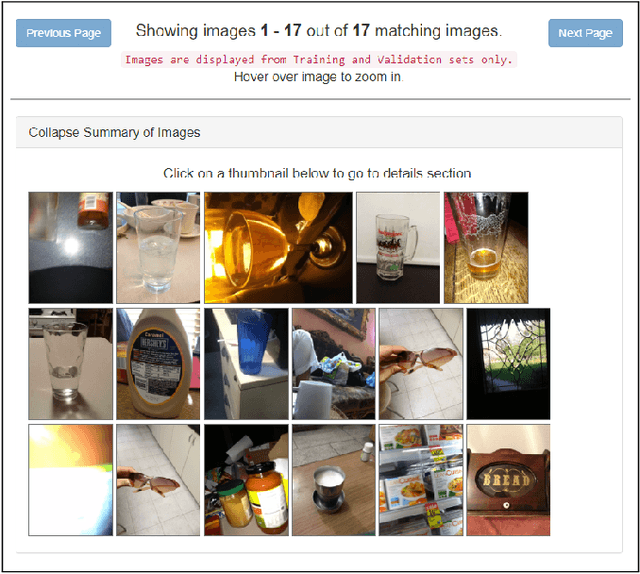
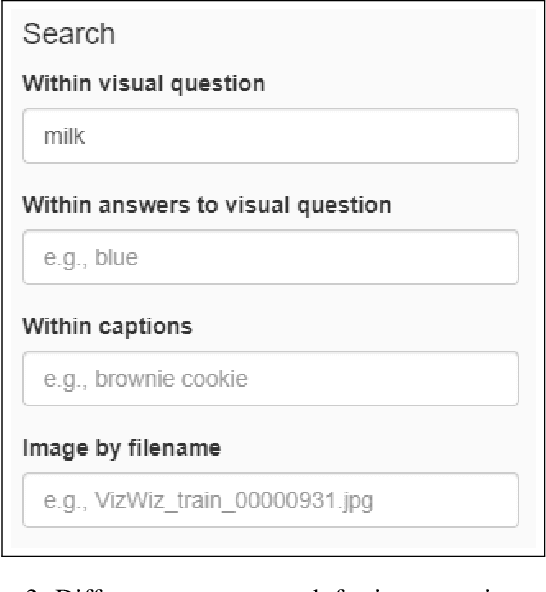
We present a visualization tool to exhaustively search and browse through a set of large-scale machine learning datasets. Built on the top of the VizWiz dataset, our dataset browser tool has the potential to support and enable a variety of qualitative and quantitative research, and open new directions for visualizing and researching with multimodal information. The tool is publicly available at https://vizwiz.org/browse.
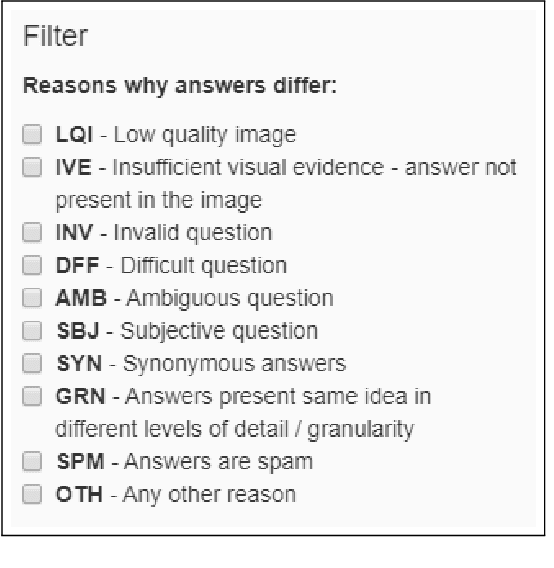
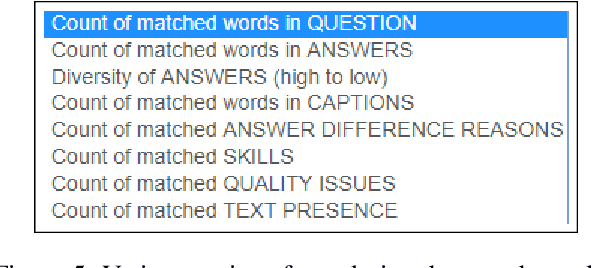
Why Does a Visual Question Have Different Answers?
Aug 14, 2019
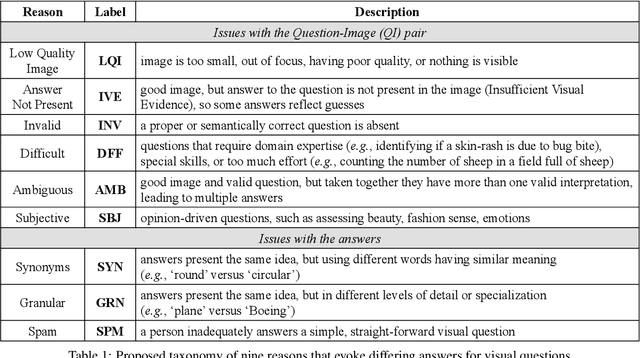
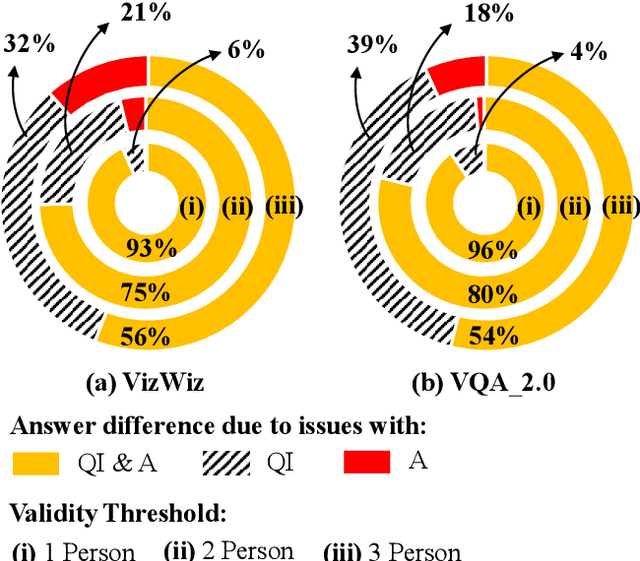
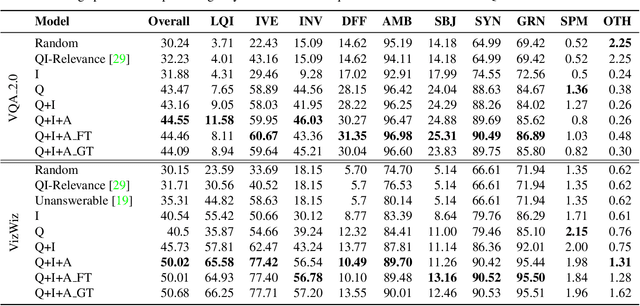
Visual question answering is the task of returning the answer to a question about an image. A challenge is that different people often provide different answers to the same visual question. To our knowledge, this is the first work that aims to understand why. We propose a taxonomy of nine plausible reasons, and create two labelled datasets consisting of ~45,000 visual questions indicating which reasons led to answer differences. We then propose a novel problem of predicting directly from a visual question which reasons will cause answer differences as well as a novel algorithm for this purpose. Experiments demonstrate the advantage of our approach over several related baselines on two diverse datasets. We publicly share the datasets and code at https://vizwiz.org.
FWLBP: A Scale Invariant Descriptor for Texture Classification
Aug 02, 2018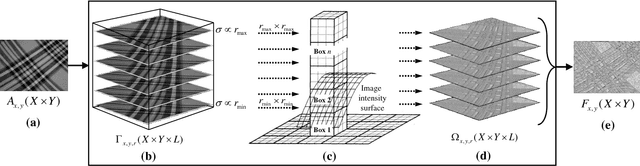

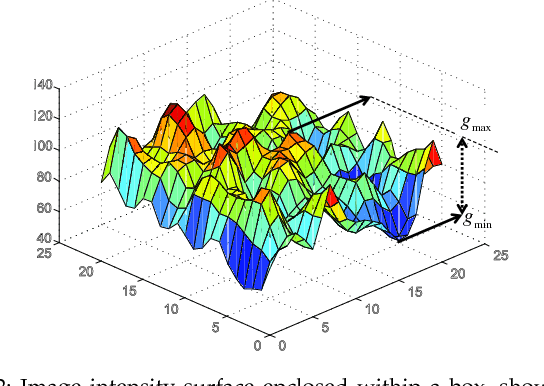
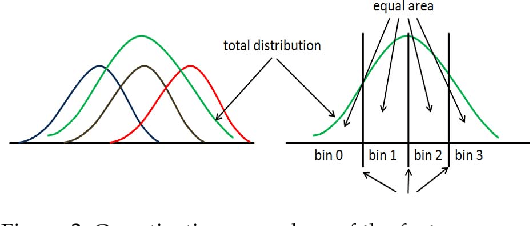
In this paper we propose a novel texture descriptor called Fractal Weighted Local Binary Pattern (FWLBP). The fractal dimension (FD) measure is relatively invariant to scale-changes, and presents a good correlation with human viewpoint of surface roughness. We have utilized this property to construct a scale-invariant descriptor. Here, the input image is sampled using an augmented form of the local binary pattern (LBP) over three different radii, and then used an indexing operation to assign FD weights to the collected samples. The final histogram of the descriptor has its features calculated using LBP, and its weights computed from the FD image. The proposed descriptor is scale invariant, and is also robust in rotation or reflection, and partially tolerant to noise and illumination changes. In addition, the local fractal dimension is relatively insensitive to the bi-Lipschitz transformations, whereas its extension is adequate to precisely discriminate the fundamental of texture primitives. Experiment results carried out on standard texture databases show that the proposed descriptor achieved better classification rates compared to the state-of-the-art descriptors.
Relating Eye-Tracking Measures With Changes In Knowledge on Search Tasks
May 07, 2018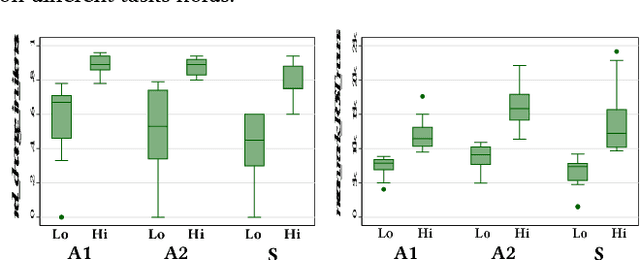

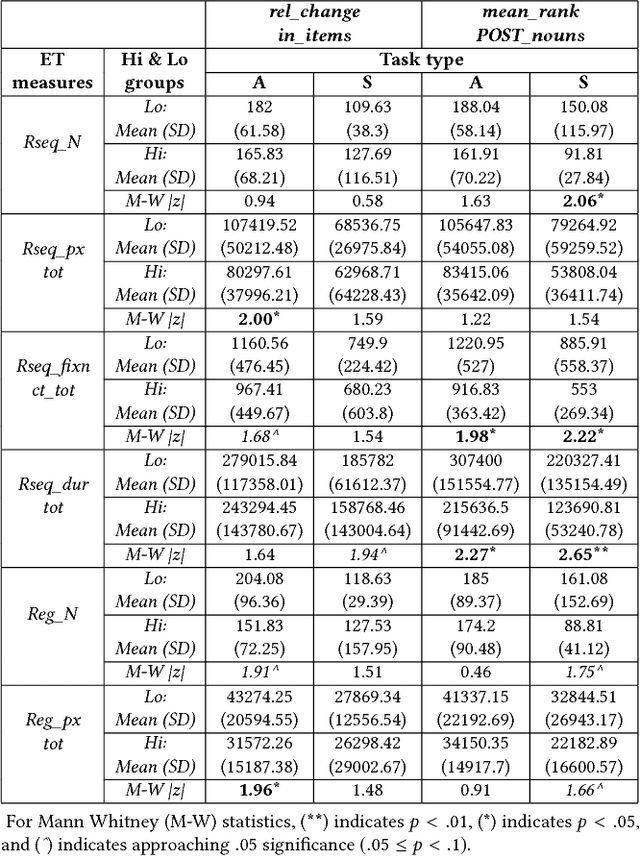
We conducted an eye-tracking study where 30 participants performed searches on the web. We measured their topical knowledge before and after each task. Their eye-fixations were labelled as "reading" or "scanning". The series of reading fixations in a line, called "reading-sequences" were characterized by their length in pixels, fixation duration, and the number of fixations making up the sequence. We hypothesize that differences in knowledge-change of participants are reflected in their eye-tracking measures related to reading. Our results show that the participants with higher change in knowledge differ significantly in terms of their total reading-sequence-length, reading-sequence-duration, and number of reading fixations, when compared to participants with lower knowledge-change.
* ACM Symposium on Eye Tracking Research and Applications (ETRA), June 14-17, 2018, Warsaw, Poland