 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Deep Learning Method for Thermal to Annotated Thermal-Optical Fused Images
Jul 13, 2021



Thermal Images profile the passive radiation of objects and capture them in grayscale images. Such images have a very different distribution of data compared to optical colored images. We present here a work that produces a grayscale thermo-optical fused mask given a thermal input. This is a deep learning based pioneering work since to the best of our knowledge, there exists no other work on thermal-optical grayscale fusion. Our method is also unique in the sense that the deep learning method we are proposing here works on the Discrete Wavelet Transform (DWT) domain instead of the gray level domain. As a part of this work, we also present a new and unique database for obtaining the region of interest in thermal images based on an existing thermal visual paired database, containing the Region of Interest on 5 different classes of data. Finally, we are proposing a simple low cost overhead statistical measure for identifying the region of interest in the fused images, which we call as the Region of Fusion (RoF). Experiments on the database show encouraging results in identifying the region of interest in the fused images. We also show that they can be processed better in the mixed form rather than with only thermal images.
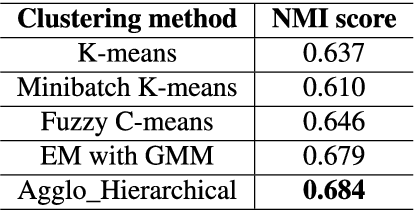
Intra-Variable Handwriting Inspection Reinforced with Idiosyncrasy Analysis
Dec 19, 2019
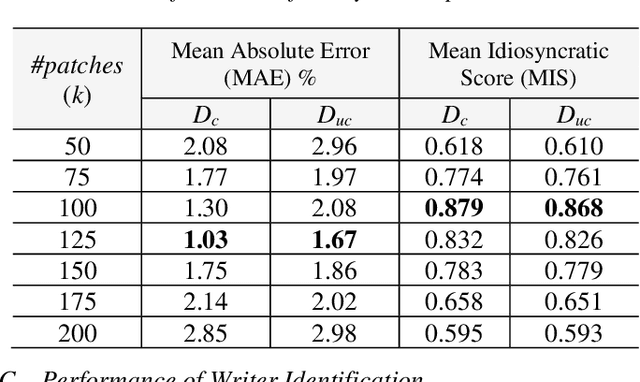
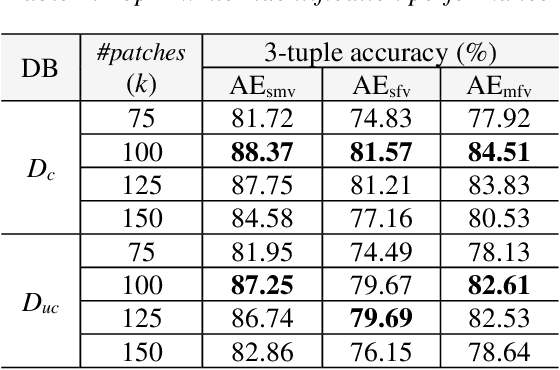
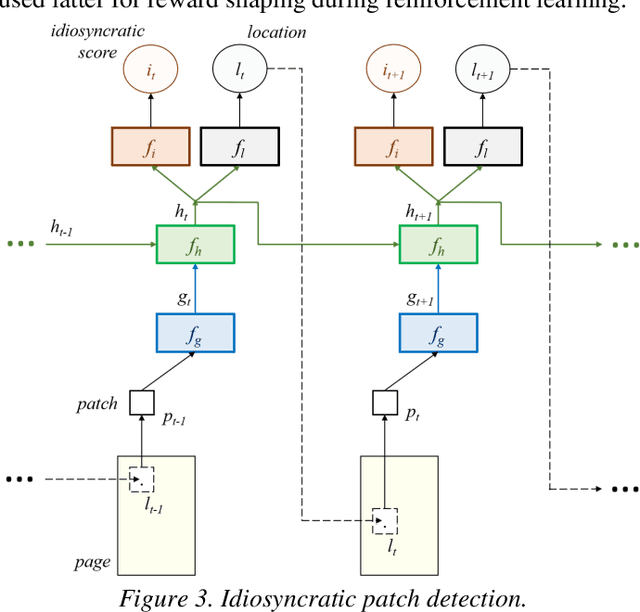
In this paper, we work on intra-variable handwriting, where the writing samples of an individual can vary significantly. Such within-writer variation throws a challenge for automatic writer inspection, where the state-of-the-art methods do not perform well. To deal with intra-variability, we analyze the idiosyncrasy in individual handwriting. We identify/verify the writer from highly idiosyncratic text-patches. Such patches are detected using a deep recurrent reinforcement learning-based architecture. An idiosyncratic score is assigned to every patch, which is predicted by employing deep regression analysis. For writer identification, we propose a deep neural architecture, which makes the final decision by the idiosyncratic score-induced weighted sum of patch-based decisions. For writer verification, we propose two algorithms for deep feature aggregation, which assist in authentication using a triplet network. The experiments were performed on two databases, where we obtained encouraging results.
HybridSN: Exploring 3D-2D CNN Feature Hierarchy for Hyperspectral Image Classification
Feb 19, 2019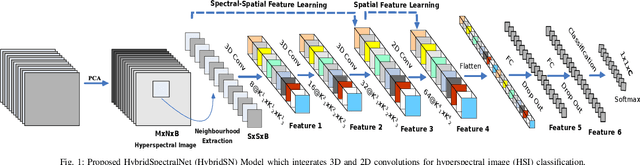

Hyperspectral image (HSI) classification is widely used for the analysis of remotely sensed images. Hyperspectral imagery includes varying bands of images. Convolutional Neural Network (CNN) is one of the most frequently used deep learning based methods for visual data processing. The use of CNN for HSI classification is also visible in recent works. These approaches are mostly based on 2D CNN. Whereas, the HSI classification performance is highly dependent on both spatial and spectral information. Very few methods have utilized the 3D CNN because of increased computational complexity. This letter proposes a Hybrid Spectral Convolutional Neural Network (HybridSN) for HSI classification. Basically, the HybridSN is a spectral-spatial 3D-CNN followed by spatial 2D-CNN. The 3D-CNN facilitates the joint spatial-spectral feature representation from a stack of spectral bands. The 2D-CNN on top of the 3D-CNN further learns more abstract level spatial representation. Moreover, the use of hybrid CNNs reduces the complexity of the model compared to 3D-CNN alone. To test the performance of this hybrid approach, very rigorous HSI classification experiments are performed over Indian Pines, Pavia University and Salinas Scene remote sensing datasets. The results are compared with the state-of-the-art hand-crafted as well as end-to-end deep learning based methods. A very satisfactory performance is obtained using the proposed HybridSN for HSI classification. The source code can be found at \url{https://github.com/gokriznastic/HybridSN}.
A Kalman filtering induced heuristic optimization based partitional data clustering
Jan 25, 2019

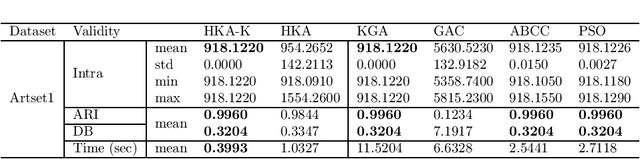
Clustering algorithms have regained momentum with recent popularity of data mining and knowledge discovery approaches. To obtain good clustering in reasonable amount of time, various meta-heuristic approaches and their hybridization, sometimes with K-Means technique, have been employed. A Kalman Filtering based heuristic approach called Heuristic Kalman Algorithm (HKA) has been proposed a few years ago, which may be used for optimizing an objective function in data/feature space. In this paper at first HKA is employed in partitional data clustering. Then an improved approach named HKA-K is proposed, which combines the benefits of global exploration of HKA and the fast convergence of K-Means method. Implemented and tested on several datasets from UCI machine learning repository, the results obtained by HKA-K were compared with other hybrid meta-heuristic clustering approaches. It is shown that HKA-K is atleast as good as and often better than the other compared algorithms.
LiSHT: Non-Parametric Linearly Scaled Hyperbolic Tangent Activation Function for Neural Networks
Jan 01, 2019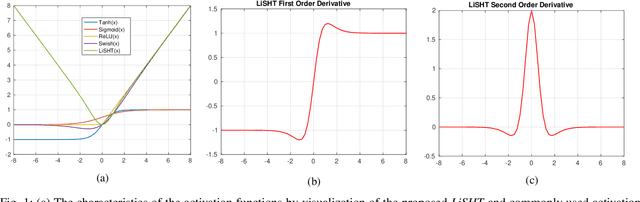
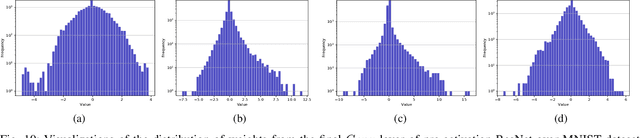
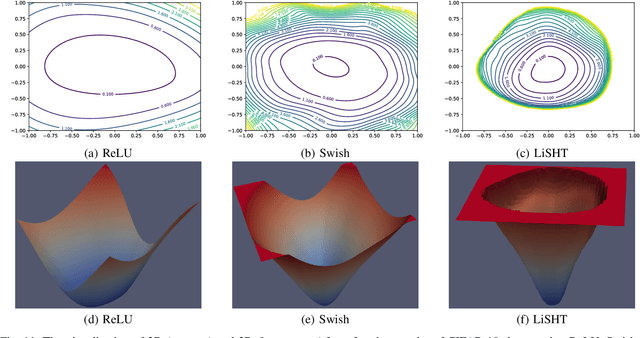
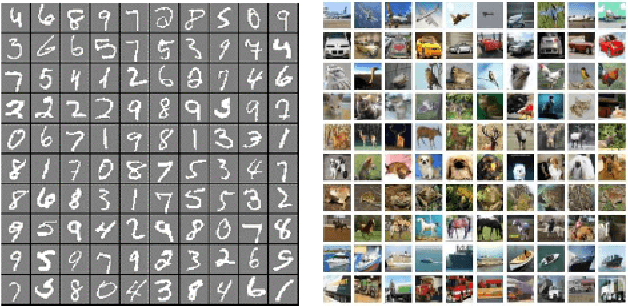
The activation function in neural network is one of the important aspects which facilitates the deep training by introducing the non-linearity into the learning process. However, because of zero-hard rectification, some the of existing activations function such as ReLU and Swish miss to utilize the negative input values and may suffer from the dying gradient problem. Thus, it is important to look for a better activation function which is free from such problems. As a remedy, this paper proposes a new non-parametric function, called Linearly Scaled Hyperbolic Tangent (LiSHT) for Neural Networks (NNs). The proposed LiSHT activation function is an attempt to scale the non-linear Hyperbolic Tangent (Tanh) function by a linear function and tackle the dying gradient problem. The training and classification experiments are performed over benchmark Car Evaluation, Iris, MNIST, CIFAR10, CIFAR100 and twitter140 datasets to show that the proposed activation achieves faster convergence and higher performance. A very promising performance improvement is observed on three different type of neural networks including Multi-layer Perceptron (MLP), Convolutional Neural Network (CNN) and Recurrent neural network like Long-short term memory (LSTM). The advantages of proposed activation function are also visualized in terms of the feature activation maps, weight distribution and loss landscape.
A Study on Writer Identification and Verification from Intra-variable Individual Handwriting
Sep 06, 2018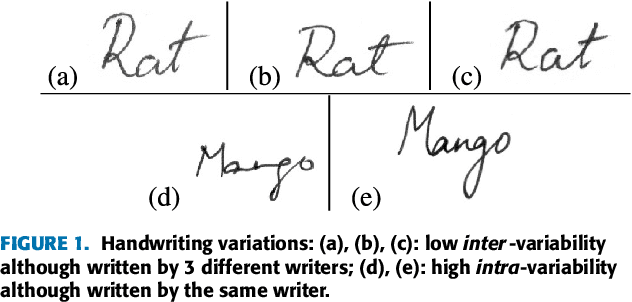
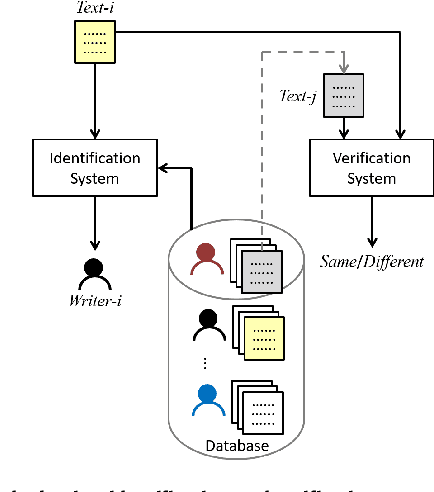
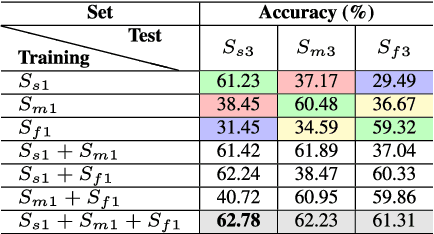
The handwriting of an individual may vary substantially with factors such as mood, time, space, writing speed, writing medium and tool, writing topic, etc. It becomes challenging to perform automated writer verification/identification on a particular set of handwritten patterns (e.g., speedy handwriting) of a person, especially when the system is trained using a different set of writing patterns (e.g., normal speed) of that same person. However, it would be interesting to experimentally analyze if there exists any implicit characteristic of individuality which is insensitive to high intra-variable handwriting. In this paper, we study some handcrafted features and auto-derived features extracted from intra-variable writing. Here, we work on writer identification/verification from offline Bengali handwriting of high intra-variability. To this end, we use various models mainly based on handcrafted features with SVM (Support Vector Machine) and features auto-derived by the convolutional network. For experimentation, we have generated two handwritten databases from two different sets of 100 writers and enlarged the dataset by a data-augmentation technique. We have obtained some interesting results.
FWLBP: A Scale Invariant Descriptor for Texture Classification
Aug 02, 2018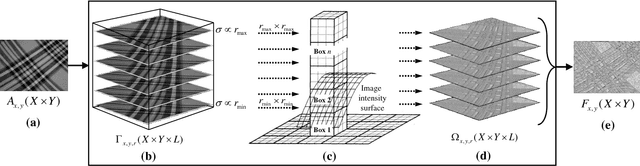

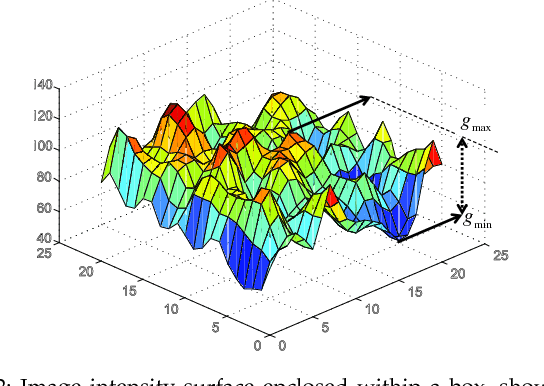
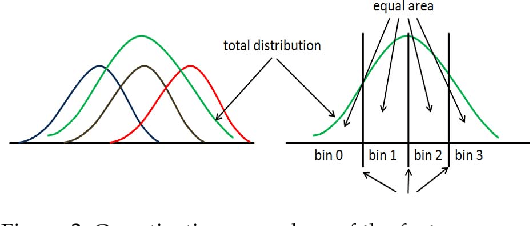
In this paper we propose a novel texture descriptor called Fractal Weighted Local Binary Pattern (FWLBP). The fractal dimension (FD) measure is relatively invariant to scale-changes, and presents a good correlation with human viewpoint of surface roughness. We have utilized this property to construct a scale-invariant descriptor. Here, the input image is sampled using an augmented form of the local binary pattern (LBP) over three different radii, and then used an indexing operation to assign FD weights to the collected samples. The final histogram of the descriptor has its features calculated using LBP, and its weights computed from the FD image. The proposed descriptor is scale invariant, and is also robust in rotation or reflection, and partially tolerant to noise and illumination changes. In addition, the local fractal dimension is relatively insensitive to the bi-Lipschitz transformations, whereas its extension is adequate to precisely discriminate the fundamental of texture primitives. Experiment results carried out on standard texture databases show that the proposed descriptor achieved better classification rates compared to the state-of-the-art descriptors.
Local Jet Pattern: A Robust Descriptor for Texture Classification
Jul 08, 2018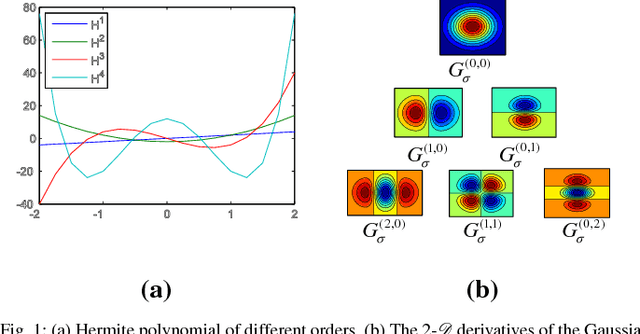
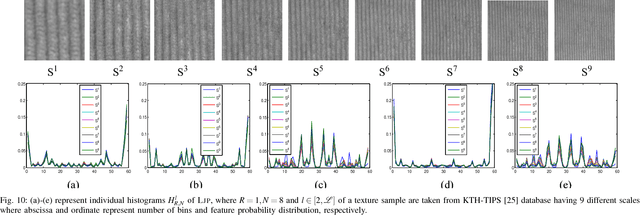
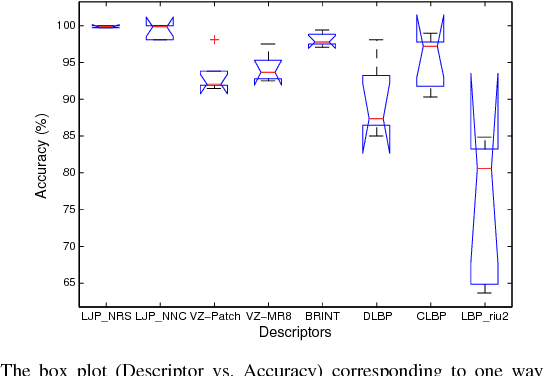
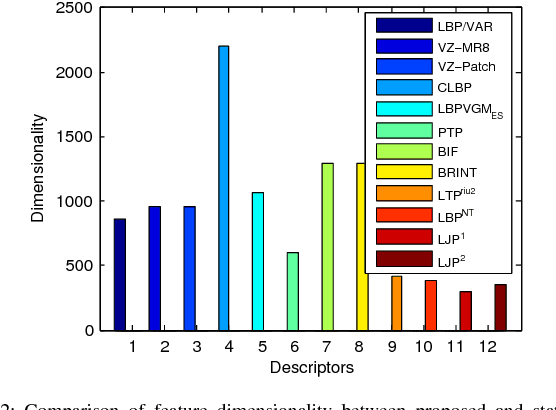
Methods based on local image features have recently shown promise for texture classification tasks, especially in the presence of large intra-class variation due to illumination, scale, and viewpoint changes. Inspired by the theories of image structure analysis, this paper presents a simple, efficient, yet robust descriptor namely local jet pattern (LJP) for texture classification. In this approach, a jet space representation of a texture image is derived from a set of derivatives of Gaussian (DtGs) filter responses up to second order, so called local jet vectors (LJV), which also satisfy the Scale Space properties. The LJP is obtained by utilizing the relationship of center pixel with the local neighborhood information in jet space. Finally, the feature vector of a texture region is formed by concatenating the histogram of LJP for all elements of LJV. All DtGs responses up to second order together preserves the intrinsic local image structure, and achieves invariance to scale, rotation, and reflection. This allows us to develop a texture classification framework which is discriminative and robust. Extensive experiments on five standard texture image databases, employing nearest subspace classifier (NSC), the proposed descriptor achieves 100%, 99.92%, 99.75%, 99.16%, and 99.65% accuracy for Outex_TC-00010 (Outex_TC10), and Outex_TC-00012 (Outex_TC12), KTH-TIPS, Brodatz, CUReT, respectively, which are outperforms the state-of-the-art methods.
Synthetic data generation for Indic handwritten text recognition
Apr 17, 2018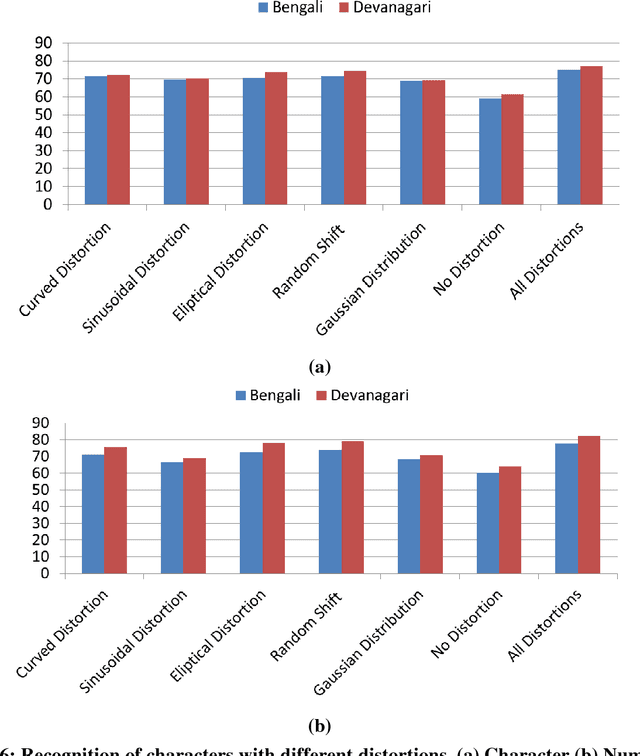
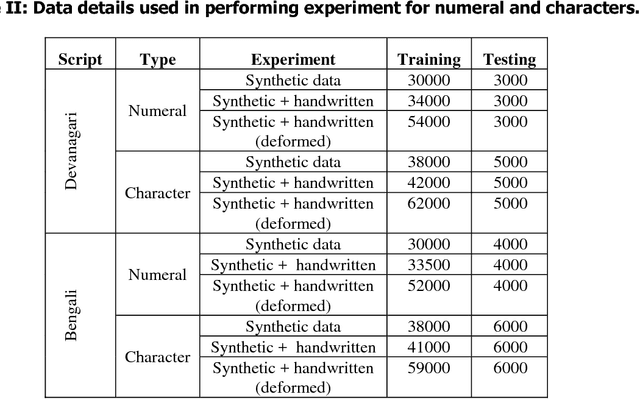
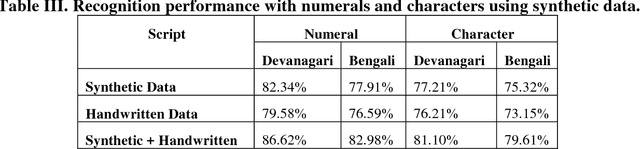
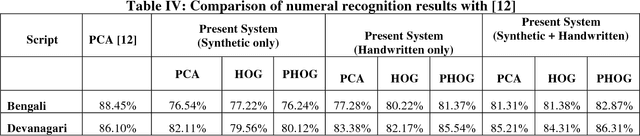
This paper presents a novel approach to generate synthetic dataset for handwritten word recognition systems. It is difficult to recognize handwritten scripts for which sufficient training data is not readily available or it may be expensive to collect such data. Hence, it becomes hard to train recognition systems owing to lack of proper dataset. To overcome such problems, synthetic data could be used to create or expand the existing training dataset to improve recognition performance. Any available digital data from online newspaper and such sources can be used to generate synthetic data. In this paper, we propose to add distortion/deformation to digital data in such a way that the underlying pattern is preserved, so that the image so produced bears a close similarity to actual handwritten samples. The images thus produced can be used independently to train the system or be combined with natural handwritten data to augment the original dataset and improve the recognition system. We experimented using synthetic data to improve the recognition accuracy of isolated characters and words. The framework is tested on 2 Indic scripts - Devanagari (Hindi) and Bengali (Bangla), for numeral, character and word recognition. We have obtained encouraging results from the experiment. Finally, the experiment with Latin text verifies the utility of the approach.
Text Line Identification in Tagore's Manuscript
Aug 18, 2016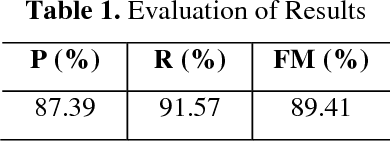

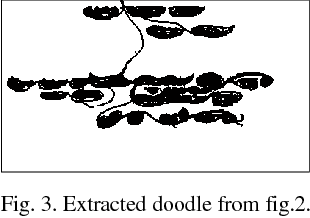
In this paper, a text line identification method is proposed. The text lines of printed document are easy to segment due to uniform straightness of the lines and sufficient gap between the lines. But in handwritten documents, the line is non-uniform and interline gaps are variable. We take Rabindranath Tagore's manuscript as it is one of the most difficult manuscripts that contain doodles. Our method consists of a pre-processing stage to clean the document image. Then we separate doodles from the manuscript to get the textual region. After that we identify the text lines on the manuscript. For text line identification, we use window examination, black run-length smearing, horizontal histogram and connected component analysis.