 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic data generation for Indic handwritten text recognition
Apr 17, 2018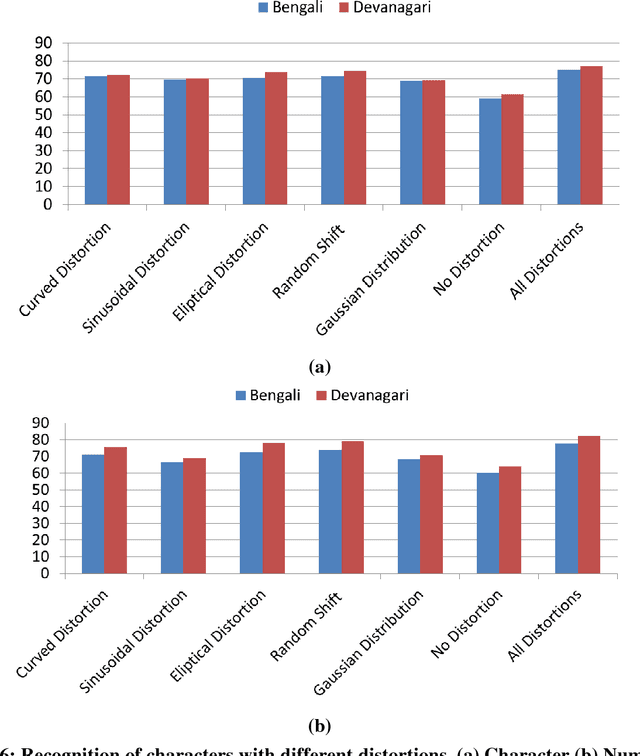
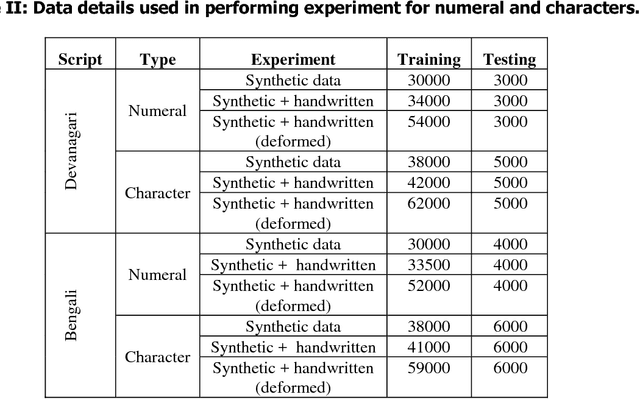
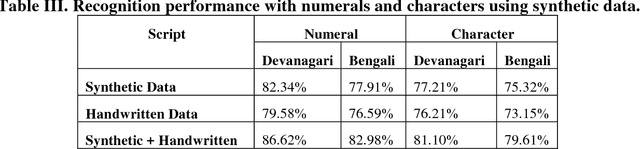
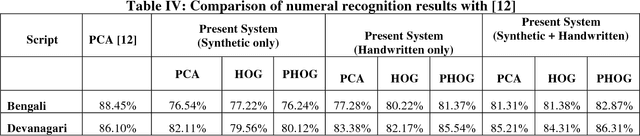
This paper presents a novel approach to generate synthetic dataset for handwritten word recognition systems. It is difficult to recognize handwritten scripts for which sufficient training data is not readily available or it may be expensive to collect such data. Hence, it becomes hard to train recognition systems owing to lack of proper dataset. To overcome such problems, synthetic data could be used to create or expand the existing training dataset to improve recognition performance. Any available digital data from online newspaper and such sources can be used to generate synthetic data. In this paper, we propose to add distortion/deformation to digital data in such a way that the underlying pattern is preserved, so that the image so produced bears a close similarity to actual handwritten samples. The images thus produced can be used independently to train the system or be combined with natural handwritten data to augment the original dataset and improve the recognition system. We experimented using synthetic data to improve the recognition accuracy of isolated characters and words. The framework is tested on 2 Indic scripts - Devanagari (Hindi) and Bengali (Bangla), for numeral, character and word recognition. We have obtained encouraging results from the experiment. Finally, the experiment with Latin text verifies the utility of the approach.
Cross-language Framework for Word Recognition and Spotting of Indic Scripts
Jan 28, 2018

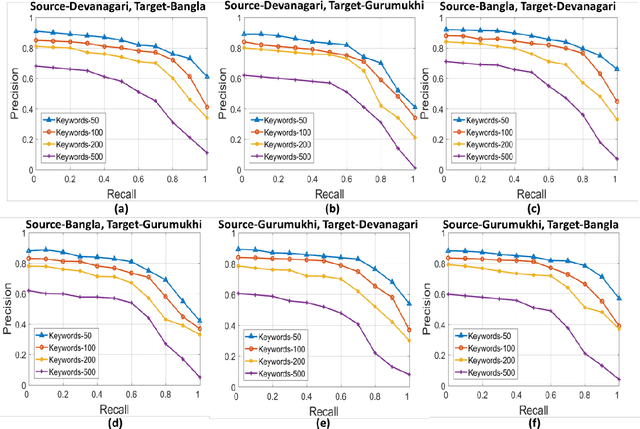
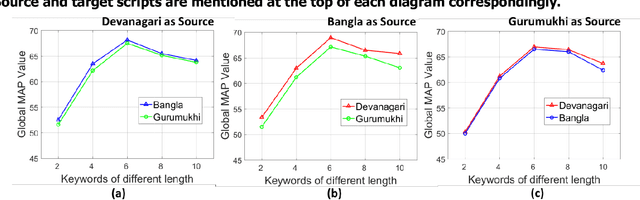
Handwritten word recognition and spotting of low-resource scripts are difficult as sufficient training data is not available and it is often expensive for collecting data of such scripts. This paper presents a novel cross language platform for handwritten word recognition and spotting for such low-resource scripts where training is performed with a sufficiently large dataset of an available script (considered as source script) and testing is done on other scripts (considered as target script). Training with one source script and testing with another script to have a reasonable result is not easy in handwriting domain due to the complex nature of handwriting variability among scripts. Also it is difficult in mapping between source and target characters when they appear in cursive word images. The proposed Indic cross language framework exploits a large resource of dataset for training and uses it for recognizing and spotting text of other target scripts where sufficient amount of training data is not available. Since, Indic scripts are mostly written in 3 zones, namely, upper, middle and lower, we employ zone-wise character (or component) mapping for efficient learning purpose. The performance of our cross-language framework depends on the extent of similarity between the source and target scripts. Hence, we devise an entropy based script similarity score using source to target character mapping that will provide a feasibility of cross language transcription. We have tested our approach in three Indic scripts, namely, Bangla, Devanagari and Gurumukhi, and the corresponding results are reported.