 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeartBeatAI: An Interpretable and Robust Deep Learning Framework for Multi-Label ECG Arrhythmia Detection
May 23, 2026While Deep Learning (DL) enhances automated electrocardiogram (ECG) analysis, clinical deployment is hindered by class imbalance and the generalization gap. This paper presents HeartBeatAI, a deep learning framework combining domain generalization, multi-scale feature aggregation, and clinical explainability for robust 12-lead ECG classification. Moving beyond image-based paradigms, HeartBeatAI integrates a Squeeze-and-Excitation (SE) ResNet to isolate diagnostic leads alongside a Multi-Layer Concentration Pipeline to capture macro-rhythm and micro-morphological anomalies. To mitigate domain shift, the framework employs MixStyle regularization and Label Smoothing. Rigorous benchmarking across four large-scale datasets using intra-source and Leave-One-Domain-Out (LODO) protocols demonstrates high performance (98% Macro F1-score) under intra-source conditions. However, LODO evaluations reveal significant degradation in detecting rare anomalies, highlighting a persistent challenge in cross-institutional deployment.
Modified TSception for Analyzing Driver Drowsiness and Mental Workload from EEG
Dec 25, 2025Driver drowsiness remains a primary cause of traffic accidents, necessitating the development of real-time, reliable detection systems to ensure road safety. This study presents a Modified TSception architecture designed for the robust assessment of driver fatigue using Electroencephalography (EEG). The model introduces a novel hierarchical architecture that surpasses the original TSception by implementing a five-layer temporal refinement strategy to capture multi-scale brain dynamics. A key innovation is the use of Adaptive Average Pooling, which provides the structural flexibility to handle varying EEG input dimensions, and a two - stage fusion mechanism that optimizes the integration of spatiotemporal features for improved stability. When evaluated on the SEED-VIG dataset and compared against established methods - including SVM, Transformer, EEGNet, ConvNeXt, LMDA-Net, and the original TSception - the Modified TSception achieves a comparable accuracy of 83.46% (vs. 83.15% for the original). Critically, the proposed model exhibits a substantially reduced confidence interval (0.24 vs. 0.36), signifying a marked improvement in performance stability. Furthermore, the architecture's generalizability is validated on the STEW mental workload dataset, where it achieves state-of-the-art results with 95.93% and 95.35% accuracy for 2-class and 3-class classification, respectively. These improvements in consistency and cross-task generalizability underscore the effectiveness of the proposed modifications for reliable EEG-based monitoring of drowsiness and mental workload.
A Comprehensive Review on Sentiment Analysis: Tasks, Approaches and Applications
Nov 19, 2023Sentiment analysis (SA) is an emerging field in text mining. It is the process of computationally identifying and categorizing opinions expressed in a piece of text over different social media platforms. Social media plays an essential role in knowing the customer mindset towards a product, services, and the latest market trends. Most organizations depend on the customer's response and feedback to upgrade their offered products and services. SA or opinion mining seems to be a promising research area for various domains. It plays a vital role in analyzing big data generated daily in structured and unstructured formats over the internet. This survey paper defines sentiment and its recent research and development in different domains, including voice, images, videos, and text. The challenges and opportunities of sentiment analysis are also discussed in the paper. \keywords{Sentiment Analysis, Machine Learning, Lexicon-based approach, Deep Learning, Natural Language Processing}
Enhancing Document Information Analysis with Multi-Task Pre-training: A Robust Approach for Information Extraction in Visually-Rich Documents
Oct 25, 2023



This paper introduces a deep learning model tailored for document information analysis, emphasizing document classification, entity relation extraction, and document visual question answering. The proposed model leverages transformer-based models to encode all the information present in a document image, including textual, visual, and layout information. The model is pre-trained and subsequently fine-tuned for various document image analysis tasks. The proposed model incorporates three additional tasks during the pre-training phase, including reading order identification of different layout segments in a document image, layout segments categorization as per PubLayNet, and generation of the text sequence within a given layout segment (text block). The model also incorporates a collective pre-training scheme where losses of all the tasks under consideration, including pre-training and fine-tuning tasks with all datasets, are considered. Additional encoder and decoder blocks are added to the RoBERTa network to generate results for all tasks. The proposed model achieved impressive results across all tasks, with an accuracy of 95.87% on the RVL-CDIP dataset for document classification, F1 scores of 0.9306, 0.9804, 0.9794, and 0.8742 on the FUNSD, CORD, SROIE, and Kleister-NDA datasets respectively for entity relation extraction, and an ANLS score of 0.8468 on the DocVQA dataset for visual question answering. The results highlight the effectiveness of the proposed model in understanding and interpreting complex document layouts and content, making it a promising tool for document analysis tasks.
Feature Reweighting for EEG-based Motor Imagery Classification
Jul 29, 2023Classification of motor imagery (MI) using non-invasive electroencephalographic (EEG) signals is a critical objective as it is used to predict the intention of limb movements of a subject. In recent research, convolutional neural network (CNN) based methods have been widely utilized for MI-EEG classification. The challenges of training neural networks for MI-EEG signals classification include low signal-to-noise ratio, non-stationarity, non-linearity, and high complexity of EEG signals. The features computed by CNN-based networks on the highly noisy MI-EEG signals contain irrelevant information. Subsequently, the feature maps of the CNN-based network computed from the noisy and irrelevant features contain irrelevant information. Thus, many non-contributing features often mislead the neural network training and degrade the classification performance. Hence, a novel feature reweighting approach is proposed to address this issue. The proposed method gives a noise reduction mechanism named feature reweighting module that suppresses irrelevant temporal and channel feature maps. The feature reweighting module of the proposed method generates scores that reweight the feature maps to reduce the impact of irrelevant information. Experimental results show that the proposed method significantly improved the classification of MI-EEG signals of Physionet EEG-MMIDB and BCI Competition IV 2a datasets by a margin of 9.34% and 3.82%, respectively, compared to the state-of-the-art methods.
Separate Scene Text Detector for Unseen Scripts is Not All You Need
Jul 29, 2023
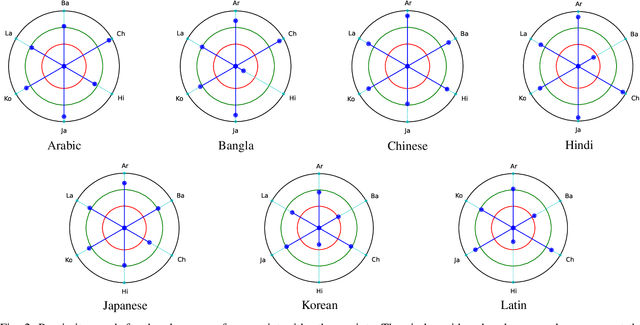

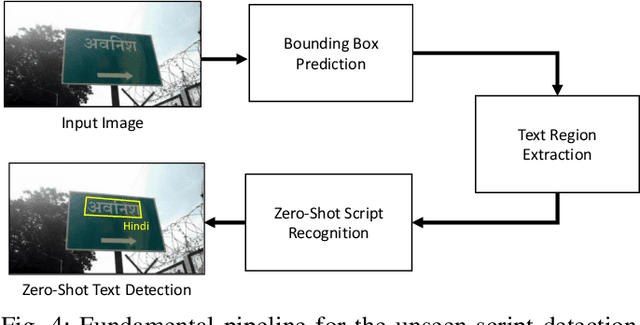
Text detection in the wild is a well-known problem that becomes more challenging while handling multiple scripts. In the last decade, some scripts have gained the attention of the research community and achieved good detection performance. However, many scripts are low-resourced for training deep learning-based scene text detectors. It raises a critical question: Is there a need for separate training for new scripts? It is an unexplored query in the field of scene text detection. This paper acknowledges this problem and proposes a solution to detect scripts not present during training. In this work, the analysis has been performed to understand cross-script text detection, i.e., trained on one and tested on another. We found that the identical nature of text annotation (word-level/line-level) is crucial for better cross-script text detection. The different nature of text annotation between scripts degrades cross-script text detection performance. Additionally, for unseen script detection, the proposed solution utilizes vector embedding to map the stroke information of text corresponding to the script category. The proposed method is validated with a well-known multi-lingual scene text dataset under a zero-shot setting. The results show the potential of the proposed method for unseen script detection in natural images.
Efficacy of Transformer Networks for Classification of Raw EEG Data
Feb 08, 2022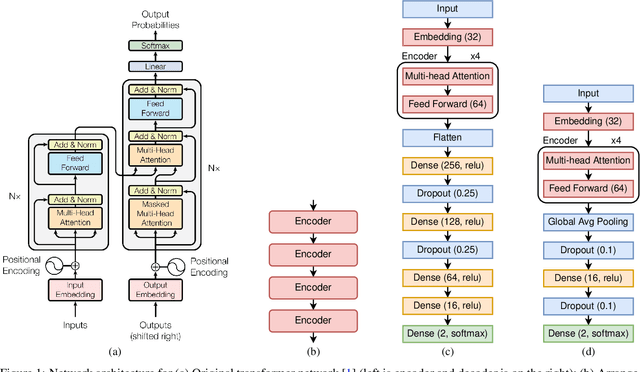
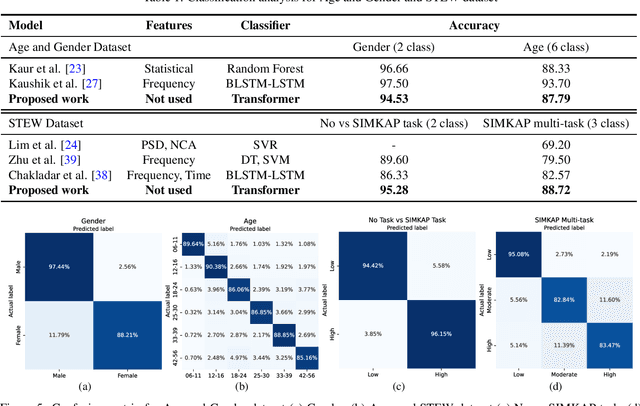
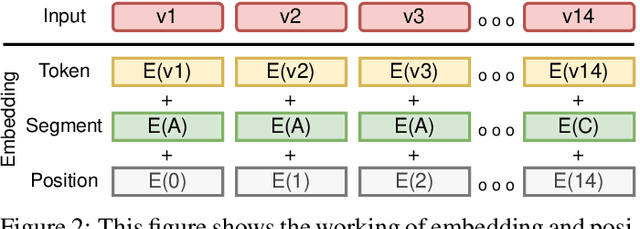
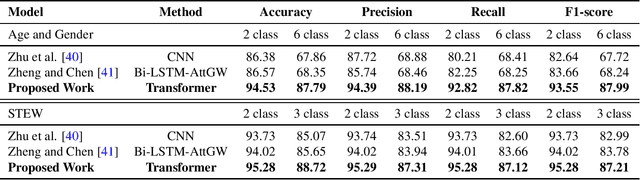
With the unprecedented success of transformer networks in natural language processing (NLP), recently, they have been successfully adapted to areas like computer vision, generative adversarial networks (GAN), and reinforcement learning. Classifying electroencephalogram (EEG) data has been challenging and researchers have been overly dependent on pre-processing and hand-crafted feature extraction. Despite having achieved automated feature extraction in several other domains, deep learning has not yet been accomplished for EEG. In this paper, the efficacy of the transformer network for the classification of raw EEG data (cleaned and pre-processed) is explored. The performance of transformer networks was evaluated on a local (age and gender data) and a public dataset (STEW). First, a classifier using a transformer network is built to classify the age and gender of a person with raw resting-state EEG data. Second, the classifier is tuned for mental workload classification with open access raw multi-tasking mental workload EEG data (STEW). The network achieves an accuracy comparable to state-of-the-art accuracy on both the local (Age and Gender dataset; 94.53% (gender) and 87.79% (age)) and the public (STEW dataset; 95.28% (two workload levels) and 88.72% (three workload levels)) dataset. The accuracy values have been achieved using raw EEG data without feature extraction. Results indicate that the transformer-based deep learning models can successfully abate the need for heavy feature-extraction of EEG data for successful classification.
Word-level Sign Language Recognition with Multi-stream Neural Networks Focusing on Local Regions
Jun 30, 2021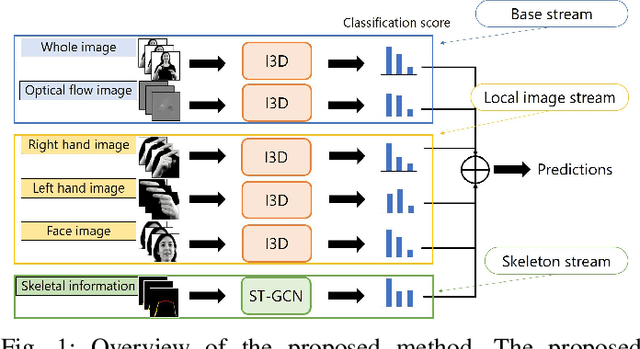
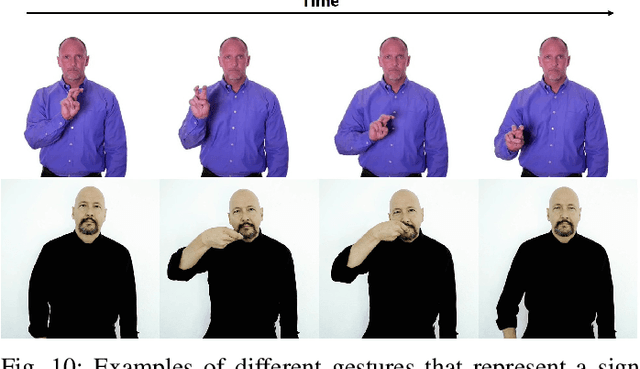
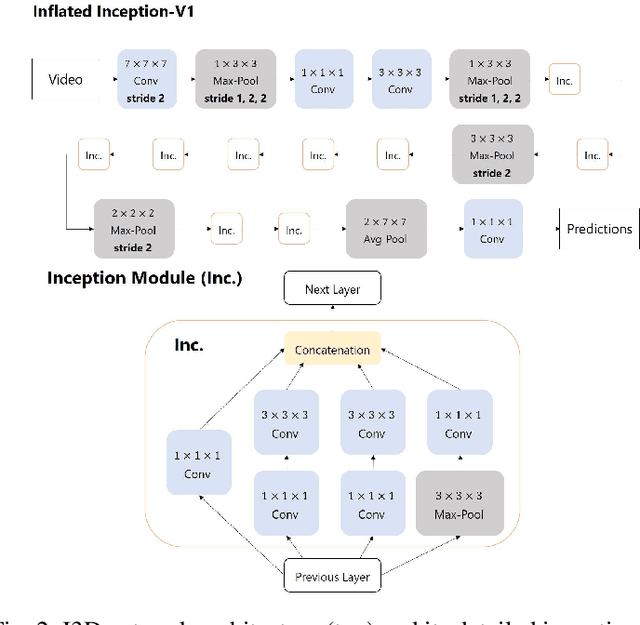
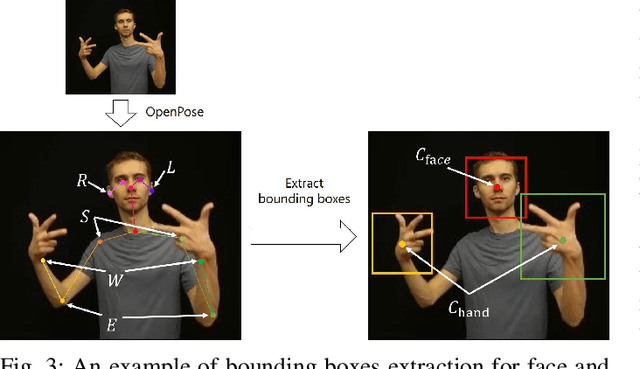
In recent years, Word-level Sign Language Recognition (WSLR) research has gained popularity in the computer vision community, and thus various approaches have been proposed. Among these approaches, the method using I3D network achieves the highest recognition accuracy on large public datasets for WSLR. However, the method with I3D only utilizes appearance information of the upper body of the signers to recognize sign language words. On the other hand, in WSLR, the information of local regions, such as the hand shape and facial expression, and the positional relationship among the body and both hands are important. Thus in this work, we utilized local region images of both hands and face, along with skeletal information to capture local information and the positions of both hands relative to the body, respectively. In other words, we propose a novel multi-stream WSLR framework, in which a stream with local region images and a stream with skeletal information are introduced by extending I3D network to improve the recognition accuracy of WSLR. From the experimental results on WLASL dataset, it is evident that the proposed method has achieved about 15% improvement in the Top-1 accuracy than the existing conventional methods.
Position and Rotation Invariant Sign Language Recognition from 3D Point Cloud Data with Recurrent Neural Networks
Oct 23, 2020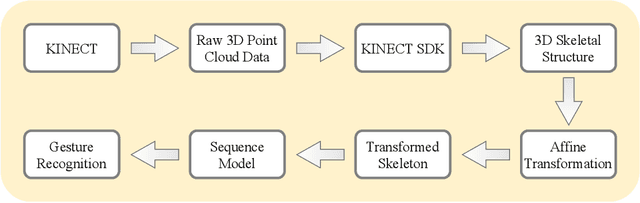
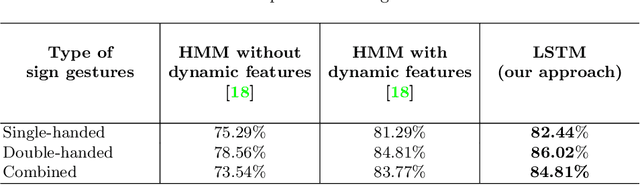
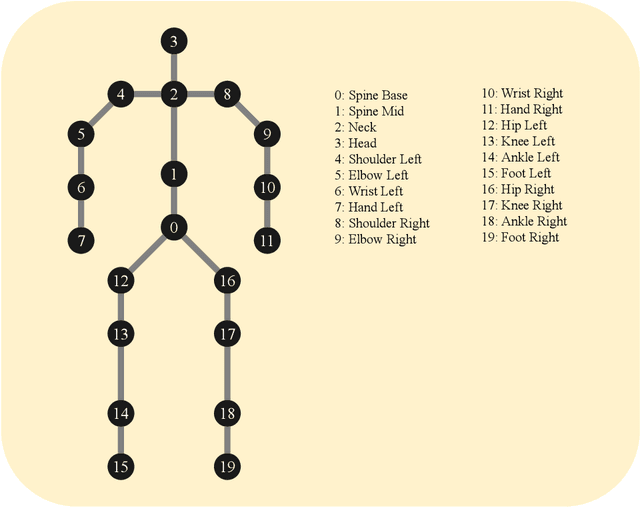
Sign language is a gesture based symbolic communication medium among speech and hearing impaired people. It also serves as a communication bridge between non-impaired population and impaired population. Unfortunately, in most situations a non-impaired person is not well conversant in such symbolic languages which restricts natural information flow between these two categories of population. Therefore, an automated translation mechanism can be greatly useful that can seamlessly translate sign language into natural language. In this paper, we attempt to perform recognition on 30 basic Indian sign gestures. Gestures are represented as temporal sequences of 3D depth maps each consisting of 3D coordinates of 20 body joints. A recurrent neural network (RNN) is employed as classifier. To improve performance of the classifier, we use geometric transformation for alignment correction of depth frames. In our experiments the model achieves 84.81% accuracy.
UDBNET: Unsupervised Document Binarization Network via Adversarial Game
Jul 14, 2020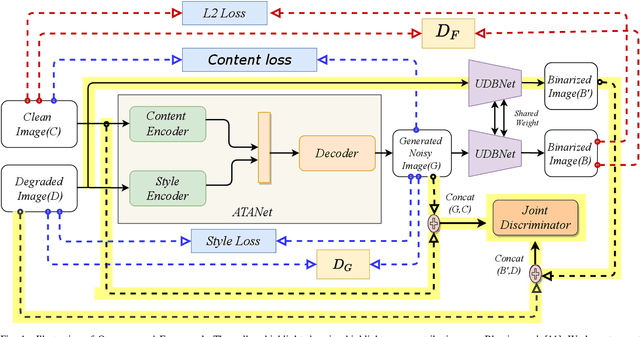



Degraded document image binarization is one of the most challenging tasks in the domain of document image analysis. In this paper, we present a novel approach towards document image binarization by introducing three-player min-max adversarial game. We train the network in an unsupervised setup by assuming that we do not have any paired-training data. In our approach, an Adversarial Texture Augmentation Network (ATANet) first superimposes the texture of a degraded reference image over a clean image. Later, the clean image along with its generated degraded version constitute the pseudo paired-data which is used to train the Unsupervised Document Binarization Network (UDBNet). Following this approach, we have enlarged the document binarization datasets as it generates multiple images having same content feature but different textual feature. These generated noisy images are then fed into the UDBNet to get back the clean version. The joint discriminator which is the third-player of our three-player min-max adversarial game tries to couple both the ATANet and UDBNet. The three-player min-max adversarial game stops, when the distributions modelled by the ATANet and the UDBNet align to the same joint distribution over time. Thus, the joint discriminator enforces the UDBNet to perform better on real degraded image. The experimental results indicate the superior performance of the proposed model over existing state-of-the-art algorithm on widely used DIBCO datasets. The source code of the proposed system is publicly available at https://github.com/VIROBO-15/UDBNET.