 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Reweighting for EEG-based Motor Imagery Classification
Jul 29, 2023Classification of motor imagery (MI) using non-invasive electroencephalographic (EEG) signals is a critical objective as it is used to predict the intention of limb movements of a subject. In recent research, convolutional neural network (CNN) based methods have been widely utilized for MI-EEG classification. The challenges of training neural networks for MI-EEG signals classification include low signal-to-noise ratio, non-stationarity, non-linearity, and high complexity of EEG signals. The features computed by CNN-based networks on the highly noisy MI-EEG signals contain irrelevant information. Subsequently, the feature maps of the CNN-based network computed from the noisy and irrelevant features contain irrelevant information. Thus, many non-contributing features often mislead the neural network training and degrade the classification performance. Hence, a novel feature reweighting approach is proposed to address this issue. The proposed method gives a noise reduction mechanism named feature reweighting module that suppresses irrelevant temporal and channel feature maps. The feature reweighting module of the proposed method generates scores that reweight the feature maps to reduce the impact of irrelevant information. Experimental results show that the proposed method significantly improved the classification of MI-EEG signals of Physionet EEG-MMIDB and BCI Competition IV 2a datasets by a margin of 9.34% and 3.82%, respectively, compared to the state-of-the-art methods.
Separate Scene Text Detector for Unseen Scripts is Not All You Need
Jul 29, 2023
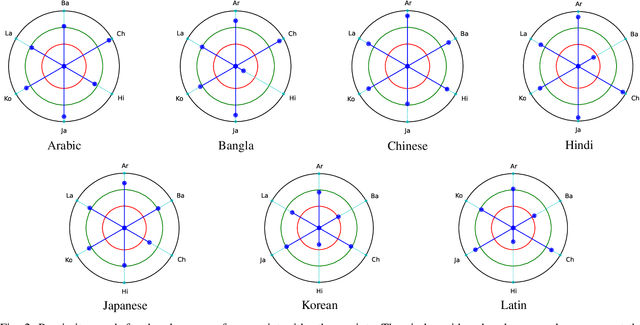

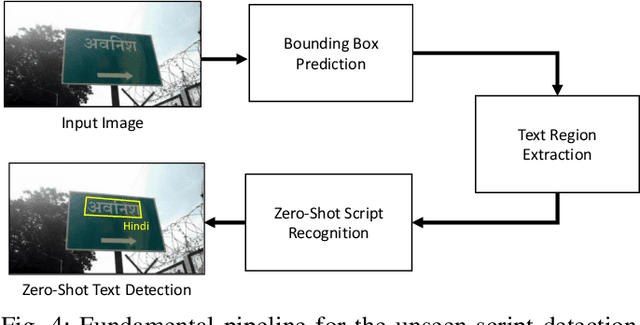
Text detection in the wild is a well-known problem that becomes more challenging while handling multiple scripts. In the last decade, some scripts have gained the attention of the research community and achieved good detection performance. However, many scripts are low-resourced for training deep learning-based scene text detectors. It raises a critical question: Is there a need for separate training for new scripts? It is an unexplored query in the field of scene text detection. This paper acknowledges this problem and proposes a solution to detect scripts not present during training. In this work, the analysis has been performed to understand cross-script text detection, i.e., trained on one and tested on another. We found that the identical nature of text annotation (word-level/line-level) is crucial for better cross-script text detection. The different nature of text annotation between scripts degrades cross-script text detection performance. Additionally, for unseen script detection, the proposed solution utilizes vector embedding to map the stroke information of text corresponding to the script category. The proposed method is validated with a well-known multi-lingual scene text dataset under a zero-shot setting. The results show the potential of the proposed method for unseen script detection in natural images.