 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review on Sentiment Analysis: Tasks, Approaches and Applications
Nov 19, 2023Sentiment analysis (SA) is an emerging field in text mining. It is the process of computationally identifying and categorizing opinions expressed in a piece of text over different social media platforms. Social media plays an essential role in knowing the customer mindset towards a product, services, and the latest market trends. Most organizations depend on the customer's response and feedback to upgrade their offered products and services. SA or opinion mining seems to be a promising research area for various domains. It plays a vital role in analyzing big data generated daily in structured and unstructured formats over the internet. This survey paper defines sentiment and its recent research and development in different domains, including voice, images, videos, and text. The challenges and opportunities of sentiment analysis are also discussed in the paper. \keywords{Sentiment Analysis, Machine Learning, Lexicon-based approach, Deep Learning, Natural Language Processing}
Feature Reweighting for EEG-based Motor Imagery Classification
Jul 29, 2023Classification of motor imagery (MI) using non-invasive electroencephalographic (EEG) signals is a critical objective as it is used to predict the intention of limb movements of a subject. In recent research, convolutional neural network (CNN) based methods have been widely utilized for MI-EEG classification. The challenges of training neural networks for MI-EEG signals classification include low signal-to-noise ratio, non-stationarity, non-linearity, and high complexity of EEG signals. The features computed by CNN-based networks on the highly noisy MI-EEG signals contain irrelevant information. Subsequently, the feature maps of the CNN-based network computed from the noisy and irrelevant features contain irrelevant information. Thus, many non-contributing features often mislead the neural network training and degrade the classification performance. Hence, a novel feature reweighting approach is proposed to address this issue. The proposed method gives a noise reduction mechanism named feature reweighting module that suppresses irrelevant temporal and channel feature maps. The feature reweighting module of the proposed method generates scores that reweight the feature maps to reduce the impact of irrelevant information. Experimental results show that the proposed method significantly improved the classification of MI-EEG signals of Physionet EEG-MMIDB and BCI Competition IV 2a datasets by a margin of 9.34% and 3.82%, respectively, compared to the state-of-the-art methods.
DyAnNet: A Scene Dynamicity Guided Self-Trained Video Anomaly Detection Network
Nov 02, 2022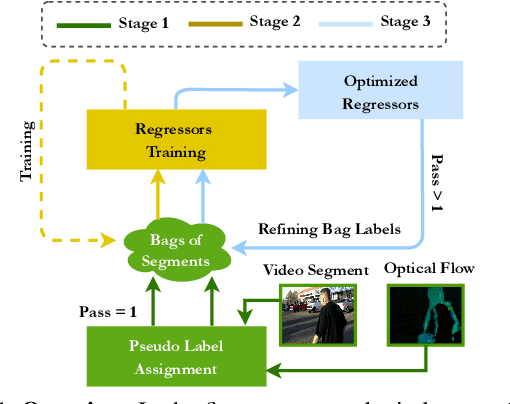
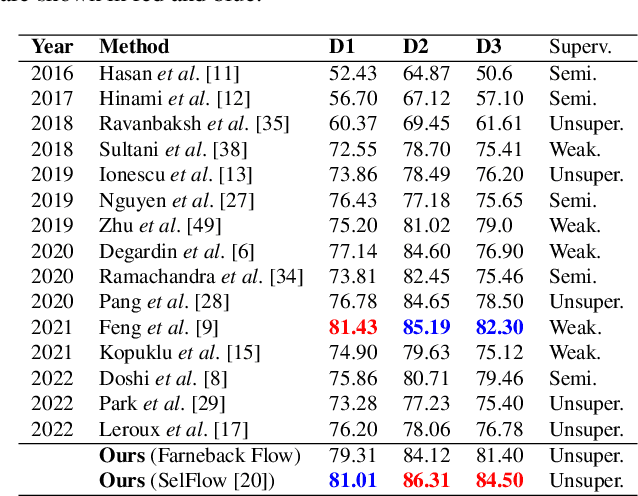
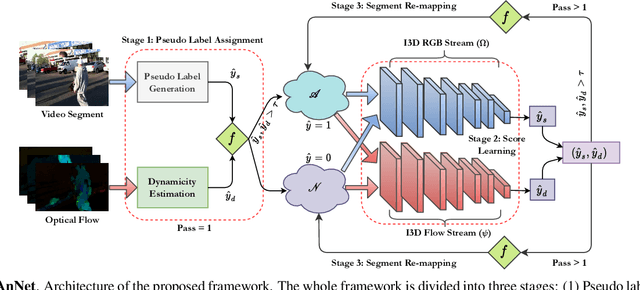
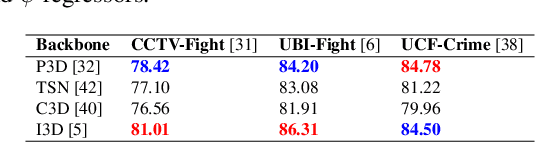
Unsupervised approaches for video anomaly detection may not perform as good as supervised approaches. However, learning unknown types of anomalies using an unsupervised approach is more practical than a supervised approach as annotation is an extra burden. In this paper, we use isolation tree-based unsupervised clustering to partition the deep feature space of the video segments. The RGB- stream generates a pseudo anomaly score and the flow stream generates a pseudo dynamicity score of a video segment. These scores are then fused using a majority voting scheme to generate preliminary bags of positive and negative segments. However, these bags may not be accurate as the scores are generated only using the current segment which does not represent the global behavior of a typical anomalous event. We then use a refinement strategy based on a cross-branch feed-forward network designed using a popular I3D network to refine both scores. The bags are then refined through a segment re-mapping strategy. The intuition of adding the dynamicity score of a segment with the anomaly score is to enhance the quality of the evidence. The method has been evaluated on three popular video anomaly datasets, i.e., UCF-Crime, CCTV-Fights, and UBI-Fights. Experimental results reveal that the proposed framework achieves competitive accuracy as compared to the state-of-the-art video anomaly detection methods.
Efficacy of Transformer Networks for Classification of Raw EEG Data
Feb 08, 2022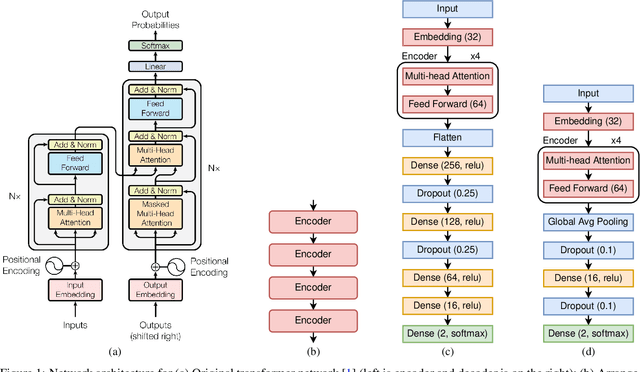
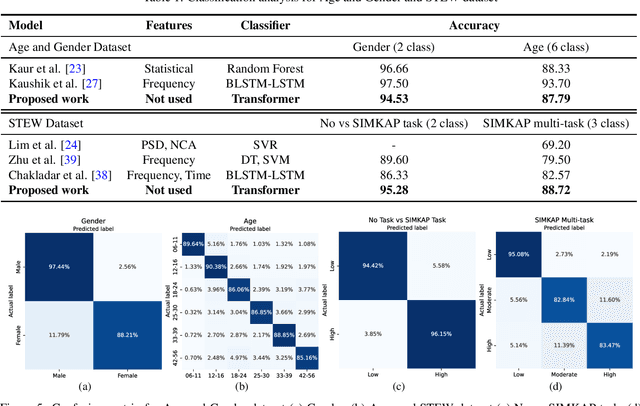
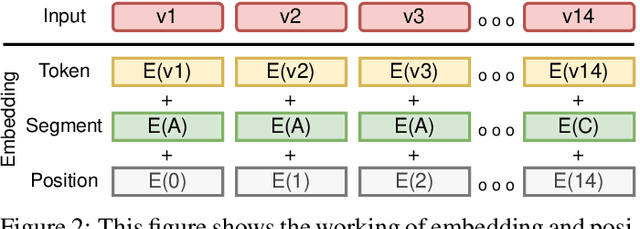
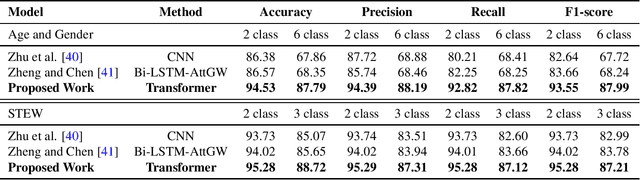
With the unprecedented success of transformer networks in natural language processing (NLP), recently, they have been successfully adapted to areas like computer vision, generative adversarial networks (GAN), and reinforcement learning. Classifying electroencephalogram (EEG) data has been challenging and researchers have been overly dependent on pre-processing and hand-crafted feature extraction. Despite having achieved automated feature extraction in several other domains, deep learning has not yet been accomplished for EEG. In this paper, the efficacy of the transformer network for the classification of raw EEG data (cleaned and pre-processed) is explored. The performance of transformer networks was evaluated on a local (age and gender data) and a public dataset (STEW). First, a classifier using a transformer network is built to classify the age and gender of a person with raw resting-state EEG data. Second, the classifier is tuned for mental workload classification with open access raw multi-tasking mental workload EEG data (STEW). The network achieves an accuracy comparable to state-of-the-art accuracy on both the local (Age and Gender dataset; 94.53% (gender) and 87.79% (age)) and the public (STEW dataset; 95.28% (two workload levels) and 88.72% (three workload levels)) dataset. The accuracy values have been achieved using raw EEG data without feature extraction. Results indicate that the transformer-based deep learning models can successfully abate the need for heavy feature-extraction of EEG data for successful classification.
Understanding Crowd Flow Movements Using Active-Langevin Model
Mar 13, 2020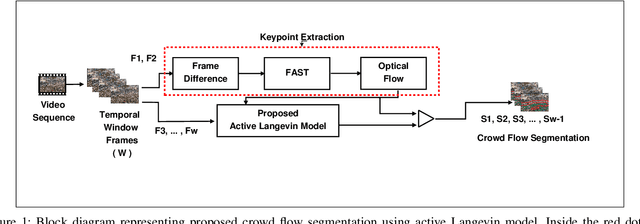
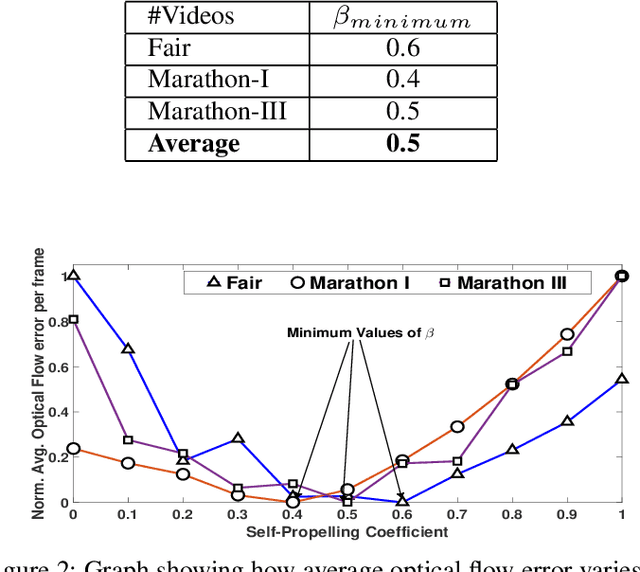
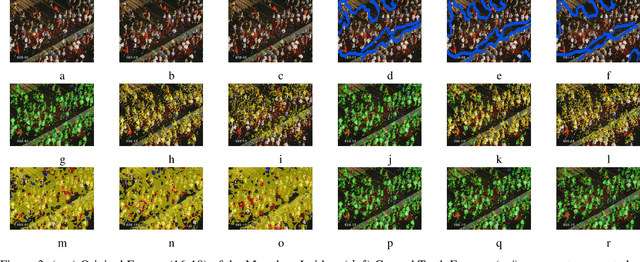

Crowd flow describes the elementary group behavior of crowds. Understanding the dynamics behind these movements can help to identify various abnormalities in crowds. However, developing a crowd model describing these flows is a challenging task. In this paper, a physics-based model is proposed to describe the movements in dense crowds. The crowd model is based on active Langevin equation where the motion points are assumed to be similar to active colloidal particles in fluids. The model is further augmented with computer-vision techniques to segment both linear and non-linear motion flows in a dense crowd. The evaluation of the active Langevin equation-based crowd segmentation has been done on publicly available crowd videos and on our own videos. The proposed method is able to segment the flow with lesser optical flow error and better accuracy in comparison to existing state-of-the-art methods.
Estimation of Linear Motion in Dense Crowd Videos using Langevin Model
Apr 15, 2019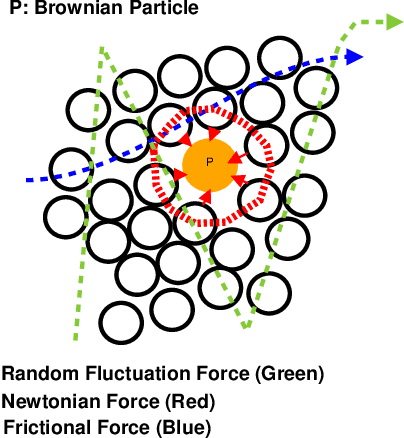
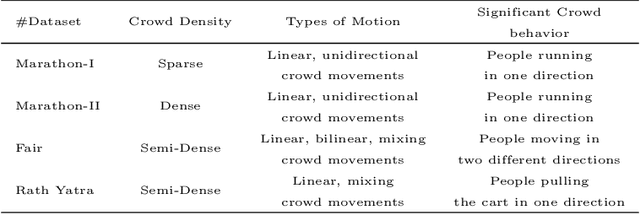
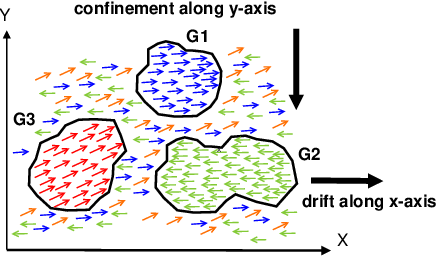
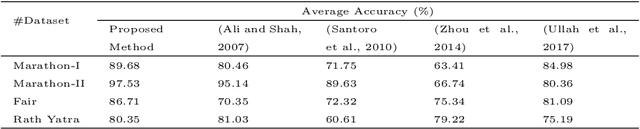
Crowd gatherings at social and cultural events are increasing in leaps and bounds with the increase in population. Surveillance through computer vision and expert decision making systems can help to understand the crowd phenomena at large gatherings. Understanding crowd phenomena can be helpful in early identification of unwanted incidents and their prevention. Motion flow is one of the important crowd phenomena that can be instrumental in describing the crowd behavior. Flows can be useful in understanding instabilities in the crowd. However, extracting motion flows is a challenging task due to randomness in crowd movement and limitations of the sensing device. Moreover, low-level features such as optical flow can be misleading if the randomness is high. In this paper, we propose a new model based on Langevin equation to analyze the linear dominant flows in videos of densely crowded scenarios. We assume a force model with three components, namely external force, confinement/drift force, and disturbance force. These forces are found to be sufficient to describe the linear or near-linear motion in dense crowd videos. The method is significantly faster as compared to existing popular crowd segmentation methods. The evaluation of the proposed model has been carried out on publicly available datasets as well as using our dataset. It has been observed that the proposed method is able to estimate and segment the linear flows in the dense crowd with better accuracy as compared to state-of-the-art techniques with substantial decrease in the computational overhead.
Can We Automate Diagrammatic Reasoning?
Feb 13, 2019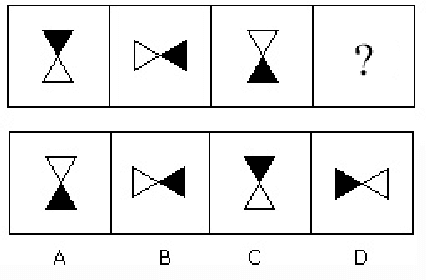


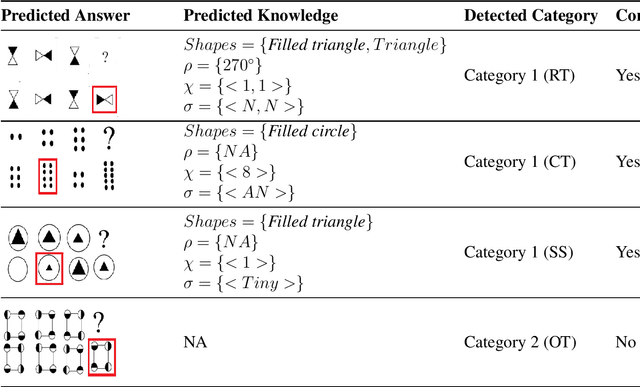
Learning to solve diagrammatic reasoning (DR) can be a challenging but interesting problem to the computer vision research community. It is believed that next generation pattern recognition applications should be able to simulate human brain to understand and analyze reasoning of images. However, due to the lack of benchmarks of diagrammatic reasoning, the present research primarily focuses on visual reasoning that can be applied to real-world objects. In this paper, we present a diagrammatic reasoning dataset that provides a large variety of DR problems. In addition, we also propose a Knowledge-based Long Short Term Memory (KLSTM) to solve diagrammatic reasoning problems. Our proposed analysis is arguably the first work in this research area. Several state-of-the-art learning frameworks have been used to compare with the proposed KLSTM framework in the present context. Preliminary results indicate that the domain is highly related to computer vision and pattern recognition research with several challenging avenues.
Person Re-identification in Videos by Analyzing Spatio-Temporal Tubes
Feb 13, 2019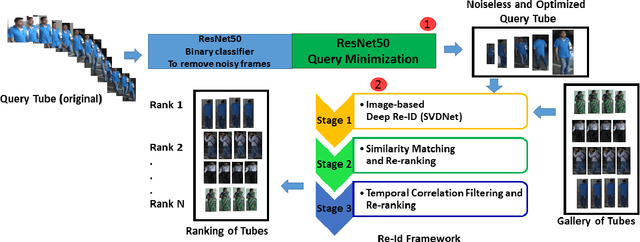
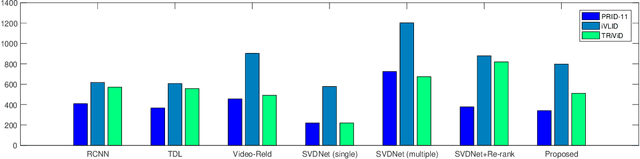
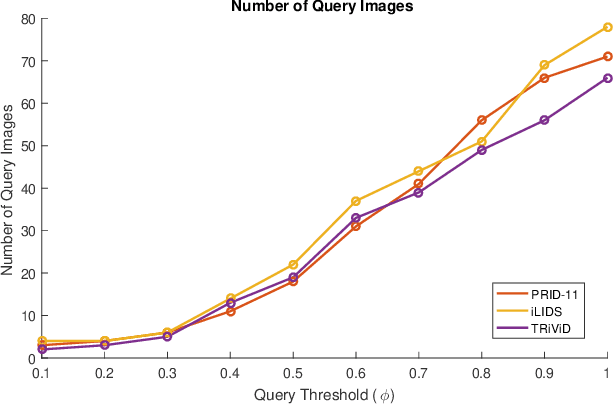
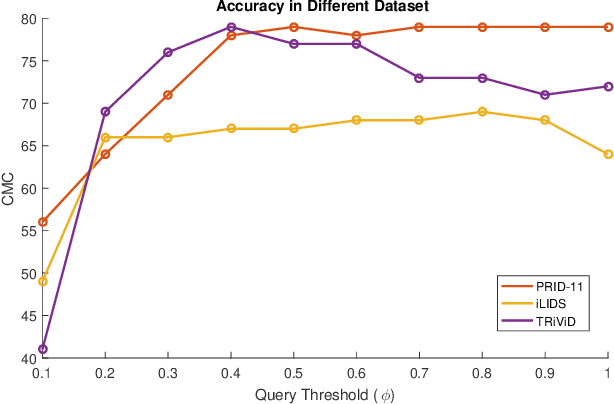
Typical person re-identification frameworks search for k best matches in a gallery of images that are often collected in varying conditions. The gallery may contain image sequences when re-identification is done on videos. However, such a process is time consuming as re-identification has to be carried out multiple times. In this paper, we extract spatio-temporal sequences of frames (referred to as tubes) of moving persons and apply a multi-stage processing to match a given query tube with a gallery of stored tubes recorded through other cameras. Initially, we apply a binary classifier to remove noisy images from the input query tube. In the next step, we use a key-pose detection-based query minimization. This reduces the length of the query tube by removing redundant frames. Finally, a 3-stage hierarchical re-identification framework is used to rank the output tubes as per the matching scores. Experiments with publicly available video re-identification datasets reveal that our framework is better than state-of-the-art methods. It ranks the tubes with an increased CMC accuracy of 6-8% across multiple datasets. Also, our method significantly reduces the number of false positives. A new video re-identification dataset, named Tube-based Reidentification Video Dataset (TRiViD), has been prepared with an aim to help the re-identification research community
Anomaly Detection in Road Traffic Using Visual Surveillance: A Survey
Jan 24, 2019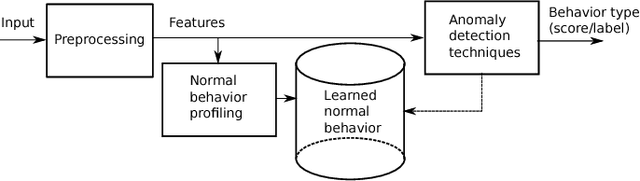
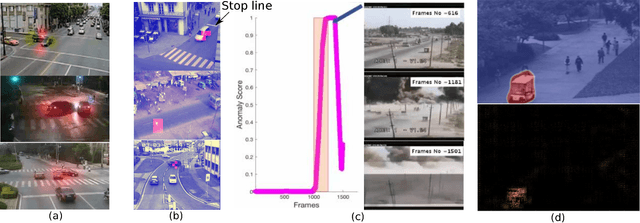
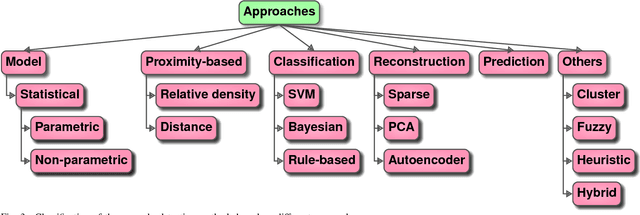
Computer vision has evolved in the last decade as a key technology for numerous applications replacing human supervision. In this paper, we present a survey on relevant visual surveillance related researches for anomaly detection in public places, focusing primarily on roads. Firstly, we revisit the surveys done in the last 10 years in this field. Since the underlying building block of a typical anomaly detection is learning, we emphasize more on learning methods applied on video scenes. We then summarize the important contributions made during last six years on anomaly detection primarily focusing on features, underlying techniques, applied scenarios and types of anomalies using single static camera. Finally, we discuss the challenges in the computer vision related anomaly detection techniques and some of the important future possibilities.
Video Trajectory Classification and Anomaly Detection Using Hybrid CNN-VAE
Dec 18, 2018
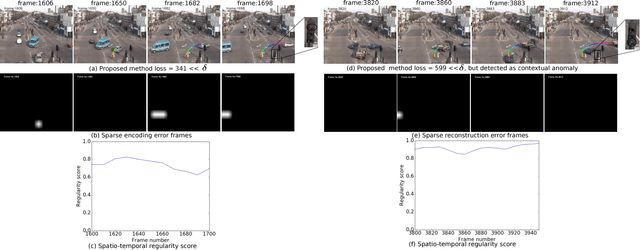
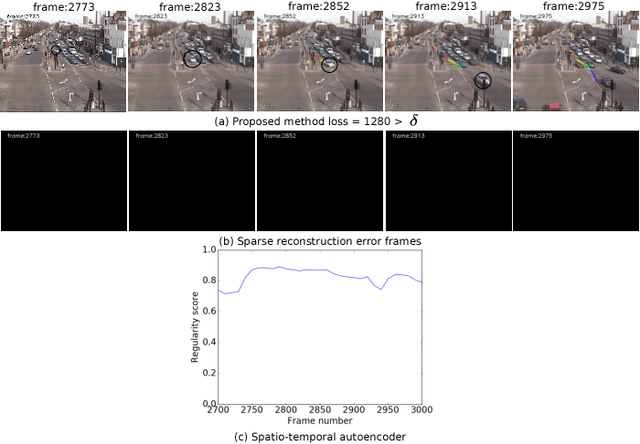
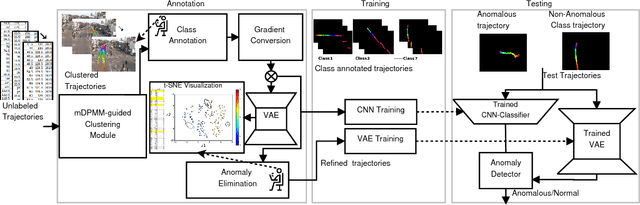
Classifying time series data using neural networks is a challenging problem when the length of the data varies. Video object trajectories, which are key to many of the visual surveillance applications, are often found to be of varying length. If such trajectories are used to understand the behavior (normal or anomalous) of moving objects, they need to be represented correctly. In this paper, we propose video object trajectory classification and anomaly detection using a hybrid Convolutional Neural Network (CNN) and Variational Autoencoder (VAE) architecture. First, we introduce a high level representation of object trajectories using color gradient form. In the next stage, a semi-supervised way to annotate moving object trajectories extracted using Temporal Unknown Incremental Clustering (TUIC), has been applied for trajectory class labeling. Anomalous trajectories are separated using t-Distributed Stochastic Neighbor Embedding (t-SNE). Finally, a hybrid CNN-VAE architecture has been used for trajectory classification and anomaly detection. The results obtained using publicly available surveillance video datasets reveal that the proposed method can successfully identify some of the important traffic anomalies such as vehicles not following lane driving, sudden speed variations, abrupt termination of vehicle movement, and vehicles moving in wrong directions. The proposed method is able to detect above anomalies at higher accuracy as compared to existing anomaly detection methods.