 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Automate Diagrammatic Reasoning?
Feb 13, 2019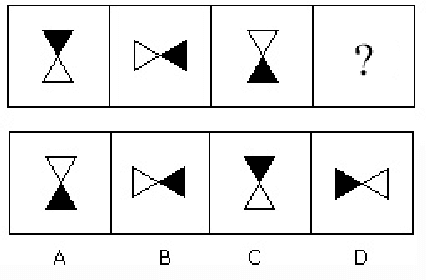


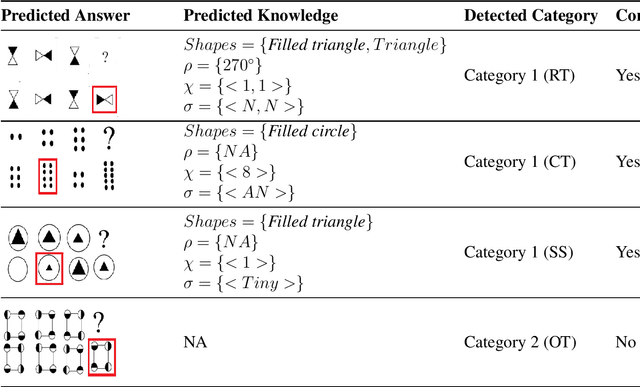
Learning to solve diagrammatic reasoning (DR) can be a challenging but interesting problem to the computer vision research community. It is believed that next generation pattern recognition applications should be able to simulate human brain to understand and analyze reasoning of images. However, due to the lack of benchmarks of diagrammatic reasoning, the present research primarily focuses on visual reasoning that can be applied to real-world objects. In this paper, we present a diagrammatic reasoning dataset that provides a large variety of DR problems. In addition, we also propose a Knowledge-based Long Short Term Memory (KLSTM) to solve diagrammatic reasoning problems. Our proposed analysis is arguably the first work in this research area. Several state-of-the-art learning frameworks have been used to compare with the proposed KLSTM framework in the present context. Preliminary results indicate that the domain is highly related to computer vision and pattern recognition research with several challenging avenues.
Person Re-identification in Videos by Analyzing Spatio-Temporal Tubes
Feb 13, 2019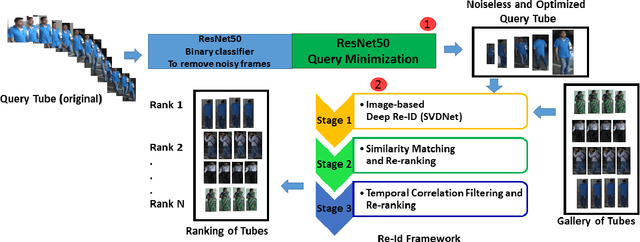
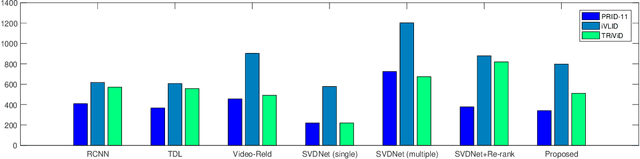
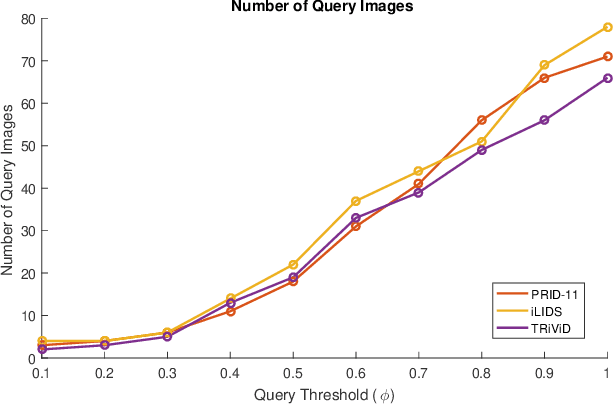
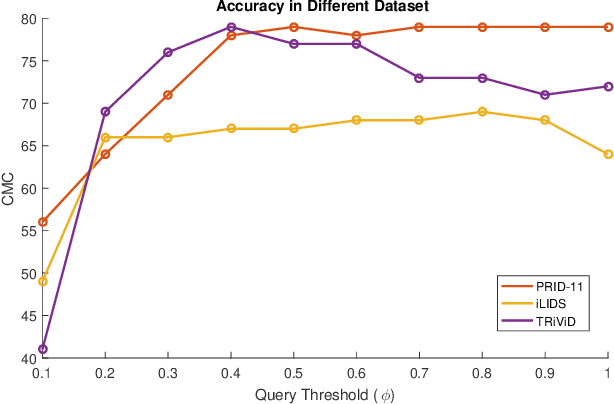
Typical person re-identification frameworks search for k best matches in a gallery of images that are often collected in varying conditions. The gallery may contain image sequences when re-identification is done on videos. However, such a process is time consuming as re-identification has to be carried out multiple times. In this paper, we extract spatio-temporal sequences of frames (referred to as tubes) of moving persons and apply a multi-stage processing to match a given query tube with a gallery of stored tubes recorded through other cameras. Initially, we apply a binary classifier to remove noisy images from the input query tube. In the next step, we use a key-pose detection-based query minimization. This reduces the length of the query tube by removing redundant frames. Finally, a 3-stage hierarchical re-identification framework is used to rank the output tubes as per the matching scores. Experiments with publicly available video re-identification datasets reveal that our framework is better than state-of-the-art methods. It ranks the tubes with an increased CMC accuracy of 6-8% across multiple datasets. Also, our method significantly reduces the number of false positives. A new video re-identification dataset, named Tube-based Reidentification Video Dataset (TRiViD), has been prepared with an aim to help the re-identification research community